准备TensorFlow模型npy数据文件
本版本不提供TensorFlow模型npy数据生成功能,请自行安装TensorFlow环境并提前准备npy数据。本文仅提供生成numpy格式TensorFlow原始数据“*.npy”文件的样例参考。
在进行TensorFlow模型生成npy数据前,您需要已经有一套完整的、可执行的、标准的TensorFlow模型应用工程。然后利用TensorFlow官方提供的debug工具tfdbg调试程序,从而生成npy文件。主要操作示例如下,请根据自己的应用工程适配操作:
- 修改TF应用工程脚本,添加debug选项设置。代码中增加如下代码:
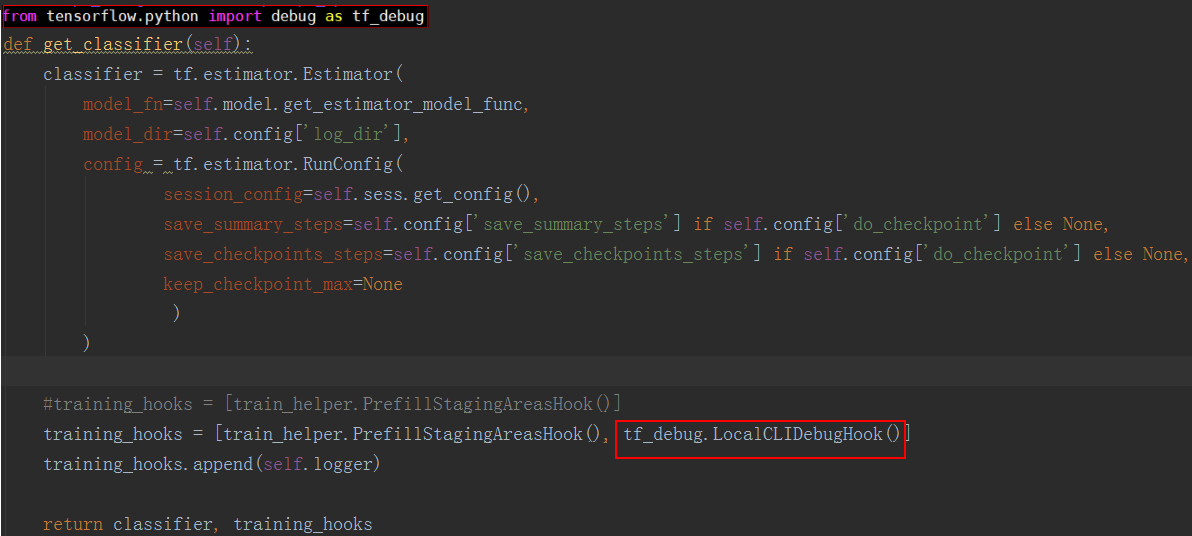
- Estimator模式:
1 2
from tensorflow.python import debug as tf_debug training_hooks = [train_helper.PrefillStagingAreaHook(), tf_debug.LocalCLIDebugHook()]
如图1所示,添加tfdbg的hook。 - session.run模式:
1 2
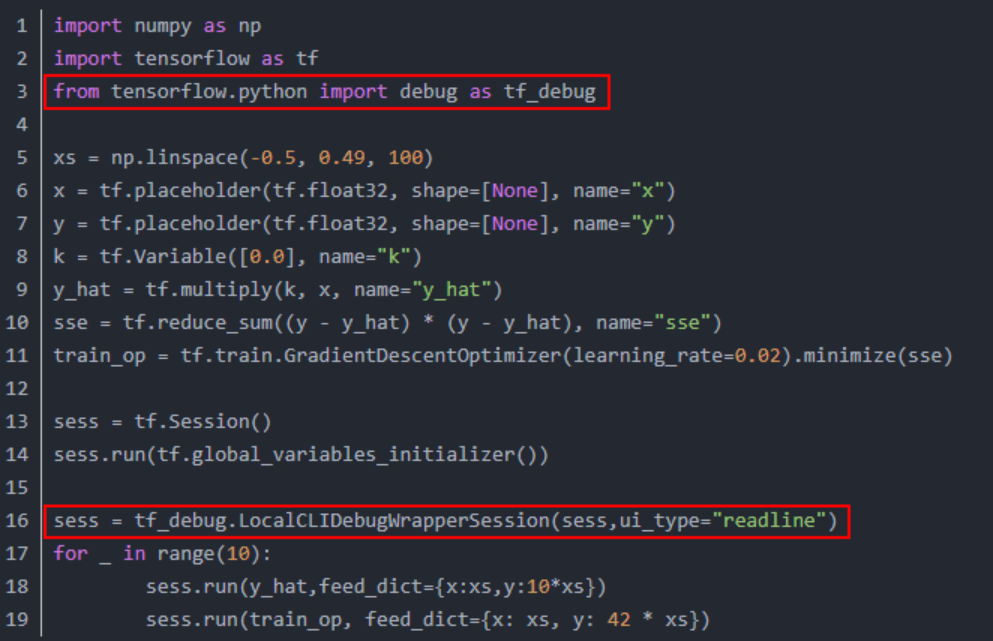
from tensorflow.python import debug as tf_debug sess = tf_debug.LocalCLIDebugWrapperSession(sess, ui_type="readline")
如图2所示,在run之前设置tfdbg装饰器。
- Estimator模式:
- 执行推理脚本。
进入调试命令行交互模式后,输入run命令。
- 收集npy文件。
执行run命令完成后,在命令行交互界面,可以通过lt查询已存储的张量,通过pt可以查看已存储的张量内容,可以保存数据为numpy格式文件。
因为tfdbg一次命令只能dump一个tensor,为了自动生成收集所有数据,可以按以下几个步骤操作:
- 执行lt > tensor_name将所有tensor的名称暂存到文件里。
- 退出tfdbg命令行,在linux命令行下执行下述命令,用以生成在tfdbg命令行执行的命令
timestamp=$[$(date +%s%N)/1000] ; cat tensor_name | awk '{print "pt",$4,$4}' | awk '{gsub("/", "_", $3);gsub(":", ".", $3);print($1,$2,"-n 0 -w "$3".""'$timestamp'"".npy")}' > tensor_name_cmd.txt

- 该示例生成符合精度比对需要的npy文件名称格式,存储到tensor_name_cmd.txt文件。其中,tensor_name为自定义tensor列表对应的文件名,timestamp为16位的时间戳。
- 本步骤也可以不退出tfdbg命令行,重新开启一个命令窗口,在新的窗口中执行。
- 回到tfdbg命令行,输入run命令后,将上一步生成的所有tensor存储的命令粘贴执行,即可存储所有npy文件。
npy文件默认是以numpy.save()形式存储的,上述命令会将“/”与“:”用下划线_替换。
如果命令行界面无法粘贴文件内容,可以在tfdbg命令行中输入“mouse off”指令关闭鼠标模式后再进行粘贴。
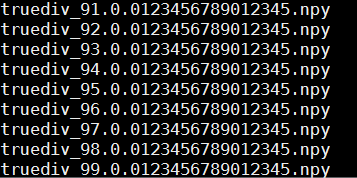
- 检查生成的npy文件命名是否符合规则,如图3所示。
- npy文件命名规则:{op_name}.{output_index}.{timestamp}.npy,其中op_name字段需满足“A-Za-z0-9_-”正则表达式规则,timestamp为16位时间戳,output_index为0~9数字组成。
- 如果因算子名较长,造成按命名规则生成的npy文件名超过255字符而产生文件名异常,这类算子不支持精度比对。
- 因tfdbg自身原因或运行环境原因,可能存在部分生成的npy文件名不符合精度比对要求,请按命名规则手工重命名。如果不符合要求的npy文件较多,请参见生成npy文件名异常情况批量处理重新生成npy文件。
父主题: 比对数据准备