'%20fill='%23C31D20'%20fill-rule='nonzero'%3e%3cpath%20d='M7.55269822,13.7609409%20C10.8552199,9.97176134%2014.2271223,7.63452926%2017.1034483,6.5677512%20L17.0816429,0.884990191%20C17.0593112,0.508963963%2016.8188535,0.182653682%2016.4703158,0.055395956%20C16.1217781,-0.0718617705%2015.7322263,0.0244201241%2015.4799397,0.300178022%20L12.9584465,3.07097775%20L0.368821458,17.4916392%20C0.0232151224,17.8857306%20-0.0894678188,18.437454%200.0732192079,18.9389805%20C0.235906234,19.4405071%200.649247199,19.815643%201.15754056,19.9230783%20C1.66583392,20.0305135%202.19185783,19.853926%202.53746417,19.4598346%20L7.5467513,13.7690073%20L7.55269822,13.7609409%20Z'%20id='路径'%3e%3c/path%3e%3cpath%20d='M10.6896552,12.0927463%20L15.1004089,17.5535201%20C15.4511303,17.8402432%2015.9409156,17.8973222%2016.3502521,17.6991755%20C16.7595885,17.5010287%2017.0117165,17.0848129%2016.993637,16.6370685%20L17.1034483,10.0202479%20C14.5615201,9.75868982%2012.477139,10.7130773%2010.6896552,12.0927463%20Z'%20id='路径'%3e%3c/path%3e%3c/g%3e%3crect%20id='矩形'%20x='0'%20y='0'%20width='24'%20height='24'%3e%3c/rect%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
脚本适配
使用断点续训功能相关的脚本适配流程如图1所示,其中配置CheckPoint保存和加载后即可实现断点续训功能,如果要使用断点续训特性中的临终遗言功能,则需要继续进行相关的脚本适配,为了更好地让用户使用断点续训功能,本文以r1.5版本的resnet和pangu代码作为示例介绍脚本适配的方法。
约束
使用前需要检查存储的磁盘空间,确保可以容纳checkpoint。
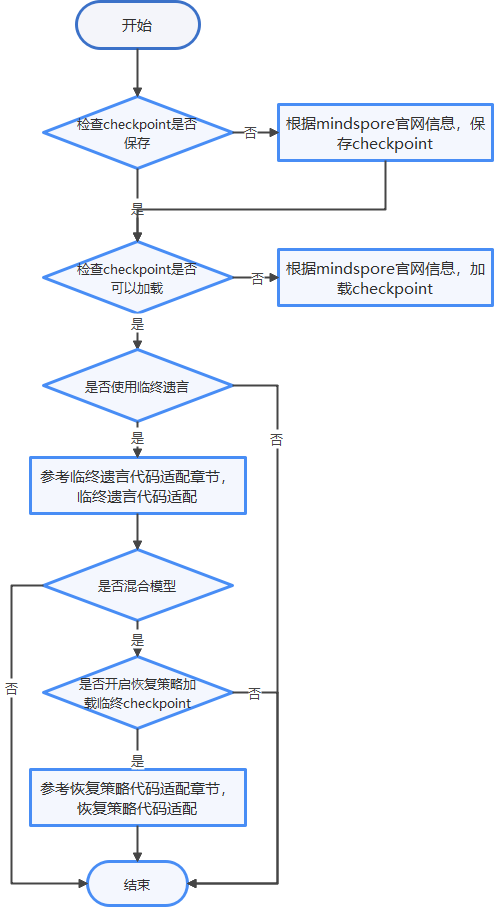
- 检查checkpoint是否保存。如果已保存,则执行3;否则执行2。
- 参考MindSpore官网教程,实现checkpoint的保存。
- 检查checkpoint是否可以加载。如果可以,则结束;否则执行4。
- 参考MindSpore官网教程,实现checkpoint的加载。
- 如果需要使用临终遗言功能,则继续参见临终遗言适配内容对脚本进行适配。
- 模型是否是混合并行,如果不是,则结束;如果是,则执行7。
- 如果需要开启恢复策略加载临终checkpoint功能,则执行8;如果不是,则结束。
- 参见混合并行模型恢复策略适配,进行恢复策略代码适配。
此章节展示的代码为开源代码,其中涉及到的脚本(Python以及shell)需要设置相同的用户和用户组。出于安全的考虑,建议用户对其中的输入参数、文件目录、文件路径等信息进行校验。
输入参数校验项目包括但不限于:
- 涉及使用外部变量作为命令的一部分都进行严格的参数校验和防注入措施。
- 从环境变量中获取的外部变量在用于命令拼接之前都要做严格的校验和防注入措施。
- 所有的进程理应最小权限原则,避免由于注入导致严重后果。
- 代码中不存在直接使用外部变量作为命令。
- 遵守各类编程语言安全规范。
文件路径校验项目包括但不限于:
- 路径长度有做限制。
- 路径有做特殊字符过滤和防绕过机制。
- 不存在命令注入。
- 进程满足最小权限原则。
- 白名单之中不存在高危路径。
- 文件路径真实性有校验,有做抛异常处理。

- 命令注入是可控外部变量导致的非预期行为。
- 临终遗言和恢复策略只支持Python3.7和Python3.9版本。
- 脚本适配中,用户需要根据情况对异常进行捕捉并按照业务逻辑处理。
Resnet50脚本适配
请下载MindSpore代码仓中r1.5分支的resnet代码作为训练代码。
- 创建代码目录。
执行以下命令,在管理节点创建代码目录。
mkdir /data/atlas_dls/code
- 获取训练脚本。
- 如果训练任务需要断点续训功能,请下载MindSpore代码仓中r1.5分支的resnet代码作为训练代码,将下载的训练代码解压到创建好的代码目录下。
- 2进入“MindXDL-deploy”仓库,选择“3.0.RC3”分支,获取“samples/mindspore/resnet50”目录中的“train_start.sh”、“main.sh”和“pre_stop.sh”文件,结合训练代码中“resnet/scripts”目录,在管理节点构造成如下的目录结构。
root@ubuntu:/data/atlas_dls/code/resnet/scripts/# scripts/ ├── pre_stop.sh ├── main.sh ... ├── run_distribute_train.sh ├── run_distribute_train_gpu.sh └── train_start.sh
- 修改“/data/atlas_dls/code/resnet/scripts”目录下的“train_start.sh”文件,将“dataset_path”修改为容器内实际的数据集目录,“conig_yaml_path”修改为容器内实际的配置文件路径。“train_start.sh”脚本通过调用“main.sh”脚本启动训练任务。在适配其他模型时,请根据其训练启动脚本(本示例为“train.py”)的使用指导,调整“main.sh”脚本中的环境变量配置、启动脚本路径、启动脚本参数。
# train_start.sh: 根据实际情况进行修改,全局配置参数:数据集路径,配置参数文件路径;其他模型适配,请根据实际情况增删参数。 dataset_path=/job/data/imagenet_full/train config_yaml_path=/job/code/resnet/resnet50_imagenet2012_config.yaml # main.sh: 针对本示例(Resnet50模型),用户不需要再修改此脚本;其他模型适配,请根据实际情况,增、删或修改环境变量配置,然后修改训练启动脚本路径和对应的参数,即main.sh脚本中python命令调用的部分。 # 本例中,单机单卡的python命令如下: python ${ROOT_PATH}/../train.py --data_path=${DATA_PATH} --config_path=${CONFIG_PATH} --output_path=${OUTPUT_PATH} # 本例中,单机多卡和分布式的命令如下: python ${ROOT_PATH}/../train.py --run_distribute=True --device_num=${device_each_server} --data_path=${DATA_PATH} --config_path=${CONFIG_PATH} --output_path=${OUTPUT_PATH} - resnet代码的启动脚本为“train.py”,检查“train.py”中是否存在保存checkpoint的代码。如果存在,则执行6;否则执行5。
- 补充保存checkpoint的代码。以下为resnet的r1.5分支提供的checkpoint保存样例,其中所用参数需要用户在配置文件中定义和设置。其他模型适配,请参考如下片段,根据启动脚本具体内容,添加保存checkpoint的代码。
... # 模型保存代码 if config.save_checkpoint: ckpt_append_info = [{"epoch_num": config.has_trained_epoch, "step_num": config.has_trained_step}] config_ck = CheckpointConfig(save_checkpoint_steps=config.save_checkpoint_epochs * step_size, keep_checkpoint_max=config.keep_checkpoint_max, append_info=ckpt_append_info) ckpt_cb = ModelCheckpoint(prefix="resnet", directory=ckpt_save_dir, config=config_ck) cb += [ckpt_cb] ... - resnet代码的启动脚本为“train.py”,检查“train.py”中是否存在加载checkpoint的代码。如果存在,则结束;否则执行7。
- 补充加载checkpoint的代码。以下为resnet的r1.5分支提供的checkpoint加载样例,其中所用参数需要用户在配置文件中定义和设置。其他模型适配,请参考如下片段,根据启动脚本具体内容,添加加载checkpoint的代码。
... def load_pre_trained_checkpoint(): """ Load checkpoint according to pre_trained path. """ param_dict = None if config.pre_trained: if os.path.isdir(config.pre_trained): # 为了文档简洁性, 此处省略了config.output_path等配置参数的校验, 请用户自行添加相关校验 ckpt_save_dir = os.path.join(config.output_path, config.checkpoint_path, "ckpt_0") ckpt_pattern = os.path.join(ckpt_save_dir, "*.ckpt") ckpt_files = glob.glob(ckpt_pattern) if not ckpt_files: logger.warning(f"There is no ckpt file in {ckpt_save_dir}, " f"pre_trained is unsupported.") else: ckpt_files.sort(key=os.path.getmtime, reverse=True) time_stamp = datetime.datetime.now() print(f"time stamp {time_stamp.strftime('%Y.%m.%d-%H:%M:%S')}" f" pre trained ckpt model {ckpt_files[0]} loading", flush=True) param_dict = load_checkpoint(ckpt_files[0]) elif os.path.isfile(config.pre_trained): # 调用checkpoint加载代码 param_dict = load_checkpoint(config.pre_trained) else: print(f"Invalid pre_trained {config.pre_trained} parameter.") return param_dict ...
Pangu模型运行
- 创建代码目录。
执行以下命令,在管理节点创建代码目录。
mkdir /data/atlas_dls/code
- 获取训练脚本。
- 如果训练任务需要断点续训功能,请下载MindSpore代码仓中r1.5分支的pangu_alpha代码作为训练代码,将下载的训练代码解压到创建好的代码目录下。
- 进入“MindXDL-deploy”仓库,选择“3.0.RC3”分支,获取“samples/mindspore/pangu_alpha”目录中的“train_start.sh”、“main.sh”和“pre_stop.sh”文件,结合训练代码中“pangu_alpha/scripts”目录,在管理节点构造成如下的目录结构。
root@ubuntu:/data/atlas_dls/code/pangu_alpha/scripts/# scripts/ ├── cache_util.sh ├── hccl.log ├── log ├── main.sh ├── pre_stop.sh ├── run_distribute_train_gpu.sh ├── run_distribute_train.sh ├── run_eval_gpu_resnet_benckmark.sh ├── run_eval_gpu.sh ├── run_eval.sh ├── run_gpu_resnet_benchmark.sh ├── run_infer_310.sh ├── run_infer.sh ├── run_parameter_server_train_gpu.sh ├── run_parameter_server_train.sh ├── run_standalone_train_gpu.sh ├── run_standalone_train.sh └── train_start.sh
- 修改“/data/atlas_dls/code/pangu_alpha/scripts”目录下的“train_start.sh”文件,将“dataset”修改为容器内实际的数据集目录。
... # 训练数据集路径,根据实际情况修改 # 安全提示,涉及对路径和输入参数的校验 dataset="/job/data/dataset/train_data" # 单节点训练场景 if [[ "$server_count" == "1" ]]; then server_id=0 if [ ${device_count} -lt 8 ]; then echo "Less than 8 card training is not supported for pangu alpha model." | tee log fi if [ ${device_count} -eq 8 ]; then bash main.sh ${device_count} ${server_count} ${RANK_TABLE_FILE} ${server_id} ${dataset} fi # 分布式训练场景 else server_id=$(get_server_id) if [ $? -eq 1 ];then echo "get server id failed." exit 1 fi echo "server id is: "${server_id} bash main.sh ${device_count} ${server_count} ${RANK_TABLE_FILE} ${server_id} ${dataset} - (可选)训练千亿模型时,期望恢复时间小于5min,需要进行额外脚本适配。百亿及以下模型可跳过该步骤。
下文以MindSpore代码仓中pangu_alpha的r1.7分支为例(已完成断点续训任务配置和脚本适配),需要对pangu_alpha_config.py进行相关配置更改,主要涉及三个参数的更改:args_opt.num_layers,args_opt.stage_num,args_opt.micro_size。
修改src/pangu_alpha_config.py,代码示例如下,加粗内容为修改部分。def set_parse_200B(args_opt): r""" Set config for 200B mode """ args_opt.embedding_size = 16384 args_opt.num_layers = 32 args_opt.num_heads = 128 if args_opt.per_batch_size == 0: args_opt.per_batch_size = 1 args_opt.word_emb_dp = 0 if args_opt.run_type == "train": args_opt.start_lr = 6e-5 args_opt.end_lr = 6e-6 args_opt.stage_num = 8 args_opt.micro_size = 16 args_opt.op_level_model_parallel_num = 16 if args_opt.optimizer_shard = 1: args_opt.op_level_model_parallel_num = 8 elif args_opt.run_type == "predict": args_opt.stage_num = 4 args_opt.micro_size = 1 args_opt.op_level_model_parallel_num = 16 if args_opt.optimizer_shard == 1: args_opt.op_level_model_parallel_num = 8 - 断点续训脚本适配。
- pangu代码的启动脚本为“train.py”,检查“train.py”中是否存在保存checkpoint的代码。如果存在,则执行步5.c;否则执行5.b。
- 补充保存checkpoint的代码。以下为pangu的r1.5分支提供的checkpoint保存样例,其中所用参数可参照5.e在配置文件“src/utils.py”中定义和设置。
... # 保存checkpoint的代码调用 add_checkpoint_callback_policy(args_opt, callback, rank) ... # 保存checkpoint代码定义 def add_checkpoint_callback_policy(args_param, callback, rank_id): r""" Add checkpoint policy to callback. """ # 安全提示,涉及对路径和输入参数的校验 if args_param.save_checkpoint: # checkpoint保存epoch_num 和 step_num info信息 ckpt_append_info = [{"epoch_num": args_param.has_trained_epoches, "step_num": args_param.has_trained_steps}] ckpt_config = CheckpointConfig(save_checkpoint_steps=args_param.save_checkpoint_steps, keep_checkpoint_max=args_param.keep_checkpoint_max, integrated_save=False, append_info=ckpt_append_info ) ckpoint_cb = ModelCheckpoint(prefix=args_param.ckpt_name_prefix + str(rank_id), directory=os.path.join(args_param.save_checkpoint_path, f"rank_{rank_id}"), config=ckpt_config) callback.append(ckpoint_cb) ... - pangu代码的启动脚本为“train.py”,检查“train.py”中是否存在加载checkpoint的代码。如果存在,则结束;否则执行5.e。本示例中“train.py”存在部分加载checkpoint的代码,需要添加断点续训特性相关checkpoint加载代码(加粗体部分内容)。
... # 安全提示,涉及对路径和输入参数的校验 # 断点续训中增加内容 if not os.path.exists(args_opt.strategy_load_ckpt_path): args_opt.strategy_load_ckpt_path = "" # 断点续训中增加内容,strategy_ckpt_save_file_path参数可以根据容器内路径指定 strategy_ckpt_save_file_path = '/job/data/code/fault_torlence/pangu_alpha/strategy.ckpt' if args_opt.strategy_load_ckpt_path == strategy_ckpt_save_file_path: strategy_ckpt_save_file_path = '/job/data/code/fault_torlence/pangu_alpha/strategy_new.ckpt' # strategy_ckpt_save_file='strategy.ckpt'修改成strategy_ckpt_save_file=strategy_ckpt_save_file_path context.set_auto_parallel_context( parallel_mode=ParallelMode.SEMI_AUTO_PARALLEL, gradients_mean=False, full_batch=bool(args_opt.full_batch), strategy_ckpt_load_file=args_opt.strategy_load_ckpt_path, enable_parallel_optimizer=bool(args_opt.optimizer_shard), strategy_ckpt_save_file='strategy.ckpt') set_algo_parameters(elementwise_op_strategy_follow=True) _set_multi_subgraphs() ... update_cell = DynamicLossScaleUpdateCell(loss_scale_value=loss_scale_value, scale_factor=2, scale_window=1000) pangu_alpha_with_grads = PanguAlphaTrainOneStepWithLossScaleCell( pangu_alpha_with_loss, optimizer=optimizer, scale_update_cell=update_cell, enable_global_norm=True, config=config) model = Model(pangu_alpha_with_grads) # checkpoint加载代码调用 # 安全提示,涉及对路径和输入参数的校验 if args_opt.pre_trained: restore_checkpoint(args_opt, callback_size, ds, model, pangu_alpha_with_grads, actual_epoch_num) callback = [ TimeMonitor(callback_size), LossCallBack(callback_size, rank, args_opt.has_trained_epoches, args_opt.has_trained_steps) ] add_checkpoint_callback_policy(args_opt, callback, rank) ... def restore_checkpoint(args_param, sink_size, dataset, model, network, epoch): r""" Load checkpoint process. """ print("======start single checkpoint", flush=True) ckpt_name = args_param.ckpt_name_prefix # 为了文档简洁易读, 此处省略了命令行参数save_checkpoint_path和ckpt_name的校验, 请用户自行添加相关校验 ckpt_pattern = os.path.join(args_param.save_checkpoint_path, "rank_{}".format(D.get_rank()), f"{ckpt_name}*.ckpt") ckpt_files = glob.glob(ckpt_pattern) if not ckpt_files: print(f"There is no ckpt file in {args_param.save_checkpoint_path}, " f"current ckpt_files found is {ckpt_files} " f"with pattern {ckpt_pattern}, so skip the loading.") return ckpt_files.sort(key=os.path.getmtime, reverse=True) time_stamp = datetime.datetime.now() print(f"time stamp {time_stamp.strftime('%Y.%m.%d-%H:%M:%S')} pre trained ckpt model {ckpt_files} loading", flush=True) # 加载checkpoint最新文件 print(f'Start to load from {ckpt_files[0]}') param_dict = load_checkpoint(ckpt_files[0]) if param_dict.get("epoch_num") and param_dict.get("step_num"): args_param.has_trained_epoches = int(param_dict["epoch_num"].data.asnumpy()) args_param.has_trained_steps = int(param_dict["step_num"].data.asnumpy()) model.build(train_dataset=dataset, sink_size=sink_size, epoch=epoch) load_param_into_net(network, param_dict) - 以下为pangu的r1.5分支提供的checkpoint加载样例,其中所用参数需要用户在配置文件中设置。
... 如果运行的模型没有开启pipeline并行,则修改在以下函数 def set_parallel_context(args_opt): 如果运行的模型开启pipeline并行,则修改在以下函数 # 安全提示,涉及对路径和输入参数的校验 def set_pipeline_parallel_context(args_opt): # 在context.set_auto_parallel_context前添加以下代码前,请参考MindSpore文档分布式并行接口说明对“set_auto_parallel_context”参数的使用介绍... # 断点续训增加内容 if not os.path.exists(args_opt.strategy_load_ckpt_path): args_opt.strategy_load_ckpt_path = "" # 断点续训增加内容,strategy_ckpt_save_file_path参数可以根据容器内路径指定 strategy_ckpt_save_file_path = '/job/data/code/fault_torlence/pangu_alpha/strategy.ckpt' if args_opt.strategy_load_ckpt_path == strategy_ckpt_save_file_path: strategy_ckpt_save_file_path = '/job/data/code/fault_torlence/pangu_alpha/strategy_new.ckpt' # strategy_ckpt_save_file='strategy.ckpt'修改成strategy_ckpt_save_file=strategy_ckpt_save_file_path context.set_auto_parallel_context( parallel_mode=ParallelMode.SEMI_AUTO_PARALLEL, gradients_mean=False, full_batch=bool(args_opt.full_batch), strategy_ckpt_load_file=args_opt.strategy_load_ckpt_path, enable_parallel_optimizer=bool(args_opt.optimizer_shard), strategy_ckpt_save_file='strategy.ckpt') set_algo_parameters(elementwise_op_strategy_follow=True) _set_multi_subgraphs() ... # 如果运行的模型没有开启pipeline并行,则修改在以下函数 def run_train(args_opt): # 如果运行的模型开启pipeline并行,则修改在以下函数,其中的rank表示进程所对应的芯片的rank id,根据上下文对参数进行修改。 def run_train_pipeline(args_opt): # checkpoint加载代码调用 if args_opt.pre_trained: restore_checkpoint(args_opt, args_opt.sink_size, ds, model, pangu_alpha_with_grads, epoch=actual_epoch_num) callback = [ TimeMonitor(callback_size), LossCallBack(callback_size, rank, args_opt.has_trained_epoches, args_opt.has_trained_steps) ] add_checkpoint_callback_policy(args_opt, callback, rank) ... # checkpoint加载代码定义 # 安全提示,涉及对路径和输入参数的校验 def restore_checkpoint(args_param, sink_size, dataset, model, network, epoch): r""" Load checkpoint process. """ print("======start single checkpoint", flush=True) ckpt_name = args_param.ckpt_name_prefix # 为了文档简洁易读, 此处省略了命令行参数save_checkpoint_path和ckpt_name的校验, 请用户自行添加相关校验 ckpt_pattern = os.path.join(args_param.save_checkpoint_path, "rank_{}".format(D.get_rank()), f"{ckpt_name}*.ckpt") ckpt_files = glob.glob(ckpt_pattern) if not ckpt_files: print(f"There is no ckpt file in {args_param.save_checkpoint_path}, " f"current ckpt_files found is {ckpt_files} " f"with pattern {ckpt_pattern}, so skip the loading.") return ckpt_files.sort(key=os.path.getmtime, reverse=True) time_stamp = datetime.datetime.now() print(f"time stamp {time_stamp.strftime('%Y.%m.%d-%H:%M:%S')} pre trained ckpt model {ckpt_files} loading", flush=True) # 加载checkpoint最新文件 print(f'Start to load from {ckpt_files[0]}') param_dict = load_checkpoint(ckpt_files[0]) if param_dict.get("epoch_num") and param_dict.get("step_num"): args_param.has_trained_epoches = int(param_dict["epoch_num"].data.asnumpy()) args_param.has_trained_steps = int(param_dict["step_num"].data.asnumpy()) model.build(train_dataset=dataset, sink_size=sink_size, epoch=epoch) load_param_into_net(network, param_dict) ...
- 修改“src/utils.py”文件中的参数。
... opt.add_argument("--vocab_size", type=int, default=50304, # 根据训练数据集进行修改,此处已修改为样例数据集的取值 help="vocabulary size, default is 40000.") ... opt.add_argument("--data_column_name", type=str, default="text", # 根据数据集定义的字段进行修改,此处已修改为样例数据集的取值 help="Column name of datasets") ... parser.add_argument("--strategy_load_ckpt_path", type=str, default="/job/data/code/fault_torlence/pangu_alpha/strategy/strategy.ckpt", # 断点续训中,根据用户习惯指定容器内路径,且路径不会被训练覆盖。 help="The training prallel strategy for the model.") parser.add_argument("--tokenizer_path", type=str, default="./tokenizer_path", help="The path where stores vocab and vocab model file") ... def add_retrain_params(opt): """ Add parameters about retrain. """ opt.add_argument("--pre_trained", type=str, default="/job/data/code/fault_torlence/pangu_alpha/8p", # 指定预训练模型路径, help="Pretrained checkpoint path.") opt.add_argument("--save_checkpoint_path", # 指定模型保存路径 type=str, default="/job/data/code/fault_torlence/pangu_alpha/8p", help="Save checkpoint path.") opt.add_argument("--keep_checkpoint_max", #指定模型保存策略:最大数量 type=int, default=1, help="Max checkpoint save number.") opt.add_argument("--save_checkpoint_steps", #指定模型保存策略:保存间隔 type=int, default=20, help="Save checkpoint step number.") opt.add_argument("--save_checkpoint", #指定当次训练是否保存模型 type=ast.literal_eval, default=True, help="Whether save checkpoint in local disk.") opt.add_argument("--ckpt_name_prefix", #指定模型保存策略:文件名前缀 type=str, default="pangu", help="Saving checkpoint name prefix.") ...
临终遗言适配
临终遗言功能目前只支持MindSpore框架,需要参见和学习MindSpore断点续训(“保存模型”章节中的“断点续训”内容)中的方法和样例,再对训练启动脚本进行适配。
MindX DL也对临终遗言功能进行了增强,以pangu_alpha模型r1.5分支为例,在“train.py”文件中添加以下加粗内容。其中mindx_elastic需要通过下载软件包获取,并且在容器内进行安装。
from mindx_elastic.terminating_message import ExceptionCheckpoint
...
def add_checkpoint_callback_policy(args_param, callback, rank_id):
...
ckpoint_cb = ModelCheckpoint(
prefix=args_param.ckpt_name_prefix + str(rank_id),
directory=os.path.join(args_param.save_checkpoint_path,
f"rank_{rank_id}"),
config=ckpt_config)
# 异常回调
# 安全提示,涉及对路径和输入参数的校验
ckpoint_exp = ExceptionCheckpoint(
prefix=args_param.ckpt_name_prefix + str(rank_id),
directory=os.path.join(args_param.save_checkpoint_path,
f"rank_{rank_id}"), config=ckpt_config)
callback.append(ckpoint_cb)
callback.append(ckpoint_exp)
...
以resnet模型r1.5分支为例,在“train.py”文件中添加以下加粗内容:
from mindx_elastic.terminating_message import ExceptionCheckpoint
import os # 如果之前不存在,则引入
import datetime # 如果之前不存在,则引入
...
def _is_time_interval_valid():
# 安全提示,涉及对路径和输入参数的校验
ckpt_save_dir = os.path.join(config.output_path, config.checkpoint_path, "ckpt_0")
ckpt_pattern = os.path.join(ckpt_save_dir, "*breakpoint.ckpt")
ckpt_files = glob.glob(ckpt_pattern)
if not ckpt_files:
return True
else:
ckpt_files.sort(key=os.path.getmtime, reverse=True)
last_breakpoint_ckpt = ckpt_files[0]
last_breakpoint_ckpt_timestamp = os.path.getmtime(last_breakpoint_ckpt)
if int((datetime.datetime.now() - datetime.timedelta(minutes=1)).timestamp()) > int(last_breakpoint_ckpt_timestamp):
return True
return False
def train_net():
...
# define callbacks
time_cb = TimeMonitor(data_size=step_size)
loss_cb = LossCallBack(config.has_trained_epoch)
cb = [time_cb, loss_cb]
ckpt_save_dir = set_save_ckpt_dir()
if config.save_checkpoint:
ckpt_append_info = [{"epoch_num": config.has_trained_epoch, "step_num": config.has_trained_step}]
config_ck = CheckpointConfig(save_checkpoint_steps=config.save_checkpoint_epochs * step_size,
keep_checkpoint_max=config.keep_checkpoint_max,
append_info=ckpt_append_info,
exception_save=_is_time_interval_valid())
ckpt_cb = ModelCheckpoint(prefix="resnet", directory=ckpt_save_dir, config=config_ck)
cb += [ckpt_cb]
if _is_time_interval_valid():
ckpoint_exp = ExceptionCheckpoint(prefix="resnet", directory=ckpt_save_dir, config=config_ck)
cb += [ckpoint_exp]
run_eval(target, model, ckpt_save_dir, cb)
...
其余模型适配是类似的,理解ExceptionCheckpoint的使用方法,和ModelCheckpoint用法类似,将定义的ExceptionCheckpoint添加到Callback列表中发挥作用。
混合并行模型恢复策略适配
- 以pangu_alpha模型为例介绍混合并行模型恢复策略适配方法,使用a800_vcjob.yaml文件运行任务。下发任务yaml中“metadata.name”对应的环境变量名称为“mindx-dls-test”和任务名保持一致,如以下代码中加粗内容所示。
... apiVersion: batch.volcano.sh/v1alpha1 kind: Job metadata: name: mindx-dls-test namespace: xxx labels: ring-controller.atlas: ascend-910 ... spec: terminationGracePeriodSeconds: 600 # 参考表2。 containers: - image: mindspore:b035 imagePullPolicy: IfNotPresent name: mindspore env: - name: mindx-dls-test valueFrom: fieldRef: fieldPath: metadata.name - name: XDL_IP valueFrom: ... - 配置混合并行模型恢复策略,参考MindSpore文档了解“GROUP_INFO_FILE”变量的使用方法,以pangu_alpha模型为例,在DL组件启动脚本main.sh中增加变量的示例如加粗内容所示。
... rankid=$((rank_start + i)) export DEVICE_ID=${i} export RANK_ID=${rankid} mkdir -p ${ROOT_PATH}/../device${rankid} cd ${ROOT_PATH}/../device${rankid} || exit group_info_dir=./group_info.pb group_info_file_tmp=$(realpath $group_info_dir) export GROUP_INFO_FILE=${group_info_file_tmp} echo "start training for rank ${RANK_ID}, device ${DEVICE_ID}" ... - 确保在可利用计算资源内开启混合并行模型恢复策略。以MindSpore pangu_alpha 2.6B模型为例,下载MindSpore代码仓中r1.5分支的pangu_alpha代码,在“src/pangu_alpha_config.py”文件中确认“args_opt.optimizer_shard”参数修改为“0”。
# 确保optimizer_shard参数设置为0 elif args_opt.mode == "2.6B": args_opt.embedding_size = 2560 args_opt.num_layers = 32 args_opt.num_heads = 32 args_opt.op_level_model_parallel_num = 8 if args_opt.run_type == "train": args_opt.start_lr = 1e-4 args_opt.end_lr = 1e-6 args_opt.optimizer_shard = 0 - 根据恢复策略加载临终checkpoint,以MindSpore pangu_alpha 2.6B模型为例,在“train.py”文件中核实如下代码,具体适配流程如下:
- 导入python依赖包,其中mindx_elastic需要通过下载软件包获取,并且在容器内进行安装。
- 增加对并行策略环境变量的处理。
- 新增临终checkpoint加载方法。
- 对原checkpoint加载方法进行检查和适配。
# 导入依赖 import json from mindx_elastic.restore_module import RestoreStrategyGenerator ... # 如果运行的模型没有开启pipeline并行,则修改在以下函数 def run_train(args_opt): # 如果运行的模型开启pipeline并行,则修改在以下函数 def run_train_pipeline(args_opt): # 增加并行策略环境变量处理 ... device_num = 1 if args_opt.distribute == "true": rank, device_num = set_parallel_context(args_opt) context.set_context(save_graphs=False, save_graphs_path="./graphs_of_device_id_" + str(rank)) # env variable prepare # 安全提示,涉及对路径、输入参数和环境变量的校验 group_info_file = os.getenv("GROUP_INFO_FILE") if group_info_file: os.environ["GROUP_INFO_FILE_REFLECT"] = group_info_file if group_info_file: # 为了文档简洁易读, 省略了对group_info_file的校验, 用户使用时根据需要进行相关校验 with open(os.path.expanduser("/job/code/group_info_env"), "a") as outfile: outfile.write(f"export GROUP_INFO_FILE_REFLECT={group_info_file}\n") ... # 加载checkpoint修改 if args_opt.pre_trained: flag = restore_exception_checkpoint(args_opt, args_opt.sink_size, ds, model, pangu_alpha_with_grads, epoch=actual_epoch_num) if not flag: restore_checkpoint(args_opt, args_opt.sink_size, ds, model, pangu_alpha_with_grads, epoch=actual_epoch_num) ... # 修改原checkpoint文件加载方法 # 安全提示,涉及对路径、输入参数和环境变量的校验 def restore_checkpoint(args_param, sink_size, dataset, model, network, epoch): r""" Load checkpoint process. """ print("======start single checkpoint", flush=True) ckpt_name = args_param.ckpt_name_prefix ckpt_pattern = os.path.join(args_param.save_checkpoint_path, "rank_{}".format(D.get_rank()), f"{ckpt_name}*.ckpt") ckpt_all_files = glob.glob(ckpt_pattern) if not ckpt_all_files: print(f"There is no ckpt file in {args_param.save_checkpoint_path}, " f"current ckpt_files found is {ckpt_all_files} " f"with pattern {ckpt_pattern}, so skip the loading.") ckpt_exp_pattern = os.path.join(args_param.save_checkpoint_path, "rank_{}".format(D.get_rank()), f"{ckpt_name}*_breakpoint.ckpt") ckpt_exp_files = glob.glob(ckpt_exp_pattern) ckpt_files = [] for file in ckpt_all_files: if file not in ckpt_exp_files: ckpt_files.append(file) if not ckpt_files: print(f"There is no ckpt file in {args_param.save_checkpoint_path}, " f"current ckpt_files found is {ckpt_files} " f"with pattern {ckpt_pattern}, so skip the loading.") return ckpt_files.sort(key=os.path.getmtime, reverse=True) ... # 定义临终checkpoint加载方法 # 安全提示,涉及对路径、输入参数和环境变量的校验 def get_exception_checkpoints(args_param): r""" Load checkpoint process. """ print("======start exception checkpoint", flush=True) restore_ranks = os.getenv("RESTORE_RANKS") if not restore_ranks: return None restore_rank_list = list(map(int, restore_ranks.split(","))) ckpt_file_list = [] ckpt_name = args_param.ckpt_name_prefix for ckpt_rank in restore_rank_list: ckpt_pattern = os.path.join(args_param.save_checkpoint_path, f"rank_{ckpt_rank}", f"{ckpt_name}*_breakpoint.ckpt") ckpt_files = glob.glob(ckpt_pattern) if not ckpt_files: print( f"There is no ckpt file in {args_param.save_checkpoint_path}, " f"current ckpt_files found is {ckpt_files} " f"with pattern {ckpt_pattern}, so skip the loading.") return None ckpt_files.sort(key=os.path.getmtime, reverse=True) ckpt_file_list.append(ckpt_files[0]) print(f"checkpoint file {ckpt_file_list}") return ckpt_file_list # 安全提示,涉及对路径、输入参数和环境变量的校验 def check_exception_checkpoints(ckpt_file_list): """ Check exception checkpoints size. Args: ckpt_file_list: exception checkpoints Returns: result of exception checkpoints size check. """ ckpt_size_list = [] for ckpt_file in ckpt_file_list: ckpt_size_list.append(os.path.getsize(ckpt_file)) if len(set(ckpt_size_list)) > 1: return False return True # 安全提示,涉及对路径、输入参数和环境变量的校验 def restore_exception_checkpoint(args_param, sink_size, dataset, model, network, epoch): """ Restore exception checkpoint to training model. Args: args_param: model training parameters sink_size: model training sink size dataset: dataset used for training model: model network: pangu_alpha network epoch: training epoch Returns: load exception checkpont success or not. """ restore_strategy_generator = RestoreStrategyGenerator() res_query = restore_strategy_generator.gen_fault_tolerance_strategy() if not res_query: return False restore_ranks, restore_dict = res_query print(f"restore ranks: {restore_ranks}, restore dict: {restore_dict}") if not restore_ranks: return False if not restore_dict: return False os.environ["RESTORE_RANKS"] = restore_ranks os.environ["RESTORE_RANKS_MAP"] = str(restore_dict) if os.getenv("RESTORE_RANKS") == "-1": return False ckpt_file_list = get_exception_checkpoints(args_param) restore_flag = False if ckpt_file_list: restore_flag = check_exception_checkpoints(ckpt_file_list) if not restore_flag: return False ckpt_name = args_param.ckpt_name_prefix restore_ranks_map = os.getenv("RESTORE_RANKS_MAP") if not restore_ranks_map: return False try: print("whether run into load process") restore_ranks_map_json = json.loads(restore_ranks_map) map_rank_id = D.get_rank() for key in restore_ranks_map_json.keys(): key_list = list(key.split(",")) if str(D.get_rank()) in key_list: map_rank_id = restore_ranks_map_json.get(key) print(f"loading map rank id {map_rank_id}") ckpt_pattern = os.path.join(args_param.save_checkpoint_path, f"rank_{map_rank_id}", f"{ckpt_name}*breakpoint.ckpt") ckpt_files = glob.glob(ckpt_pattern) ckpt_files.sort(key=os.path.getmtime, reverse=True) print(f" checkpoint files {ckpt_files[0]}") param_dict = load_checkpoint(ckpt_files[0]) print(f" checkpoint param dict epoch num {param_dict.get('epoch_num')}") if param_dict.get("epoch_num") and param_dict.get("step_num"): args_param.has_trained_epoches = int( param_dict["epoch_num"].data.asnumpy()) args_param.has_trained_steps = int( param_dict["step_num"].data.asnumpy()) # 加载checkpoint文件 model.build(train_dataset=dataset, sink_size=sink_size, epoch=epoch) load_param_into_net(network, param_dict) except TypeError: return False else: return True
