产品描述
产品介绍
MindCluster MindIO Training Fault Tolerance(下文简称MindIO TFT)包括临终CheckPoint保存、进程级在线恢复和进程级别重调度等功能,分别对应:
- MindCluster MindIO Try To Persist(下文简称MindIO TTP)功能,主要针对大模型训练过程中故障恢复加速,MindIO TTP特性通过在训练过程中发生故障后,校验中间状态数据的完整性和一致性,生成一次临终CheckPoint数据,恢复训练时能够通过该CheckPoint数据恢复,减少故障造成的训练迭代损失。
- MindCluster MindIO Uncorrectable Memory Error(下文简称MindIO UCE)功能,主要是针对大模型训练过程中片上内存的UCE故障检测,并完成在线修复,达到Step级重计算。
- MindCluster MindIO Air Refuelling(下文简称MindIO ARF)功能,训练发生异常后,不用重新拉起整个集群,只需以节点为单位进行重启或替换,完成修复并继续训练。
产品价值
LLM(Large Language Model)是全球当前科技界竞争的焦点,LLM的训练往往需要长达数十天、甚至数月,CheckPoint是模型训练中断后恢复训练的关键点,CheckPoint过程中,整个集群中的训练任务会停滞,为了集群的利用率,CheckPoint的周期都配置的比较长,甚至达到数小时。这导致如果训练任务在即将生成CheckPoint数据的前一刻发生故障,未能生成本次CheckPoint数据,则只能从上一次的CheckPoint数据恢复,上次CheckPoint到故障前一刻的训练迭代需要重新计算,损失较大。MindIO TTP特性,在故障发生后,立即生成一次CheckPoint数据,恢复时也能立即恢复到故障前一刻的状态,减少迭代损失。
与此同时,LLM训练每一次保存CheckPoint数据并加载数据重新迭代训练所需时间同保存和加载周期CheckPoint类似都比较长,MindIO UCE和MindIO ARF针对不同的故障类型,完成在线修复或仅故障节点重启级别的在线修复,节约集群停止重启时间。
MindIO TFT架构
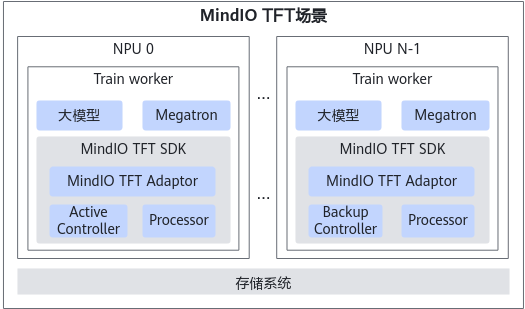
MindIO TFT的各个功能集成在一个whl包中对外提供,需要通过import模块的方式,修改MindSpeed-LLM等大模型框架适配并使用对应功能。
MindIO TFT的关键点如下:
- MindIO TTP
- 通过Controller和Processor模块,检测模型训练状态;通过心跳定期汇报至Controller模块。一旦检测到故障,就开始临终CheckPoint保存。
- 大模型训练中业界定期保存CheckPoint的时间间隔长。如果发生故障时,距离上一次保存的时间间隔过长,但又没到下一次保存的时间,此时如果重新训练就会消耗大量时间和资源。MindIO TTP提供了几乎零损时间和资源的重新训练方案,即重新训练从上一次故障处开始。
- MindIO UCE
- 一旦检测到UCE故障,就开始在线修复。
- 在大模型训练中,无论是定期保存CheckPoint,还是MindIO TFT的临终CheckPoint保存,重新训练的消耗都是巨大的。UCE提供了训练框架Step级重计算能力,不需要重启进程,同时能保证续训迭代损失,UCE失败后进入TTP流程。
- MindIO ARF
针对更多的故障,不需要模型停止训练,只需通过节点重启或替换,完成修复和模型续训。
逻辑模型
- Controller模块:负责分布式任务的协同,内部维护状态机,状态机支持不同场景的流程控制;实时收集各个训练进程的训练状态,当训练发生异常后,结合异常类型,触发状态机运作,将状态机对应的Action发送到Processor模块执行。
- Processor模块:负责与训练框架交互,获取训练进程的训练状态,向Controller汇报,同时负责执行Controller模块下发的对应Action动作。
- Adaptor模块:负责完成训练框架对MindIO TTP、MindIO UCE、MindIO ARF特性的适配。目前MindIO TFT已完成对MindSpeed-LLM、MindSpeed训练框架的适配。对于其他训练框架,需用户参考并自行适配。
部署形态
- Controller模块:在整个训练集群中,仅支持存在一个Active Controller,建议部署在集群0号节点上,并自动拉起最多两个Backup Controller。
- Processor模块:在整个训练集群中,每个训练进程均需要拉起Processor。