产品描述
产品介绍
MindIO故障快速恢复特性,当前包括TTP(Try To Persist)临终遗言CheckPoint保存。针对大模型训练过程中故障恢复加速,TTP特性通过在训练过程中发生故障后,校验中间状态数据的完整性和一致性,生成一次临时CheckPoint数据,恢复训练时能够通过该CheckPoint数据恢复,减少故障造成的训练迭代损失。
产品价值
LLM(Large Language Model)是全球当前科技界竞争的焦点,LLM模型的训练往往需要长达数十天、甚至数月,CheckPoint是模型训练中断后恢复训练的关键点,CheckPoint过程中,整个集群中的训练任务会停滞,为了集群的利用率,CheckPoint的周期都配置的比较长,甚至达到数小时级。这导致如果训练任务在即将生成CheckPoint数据前一刻发生故障,未能生成本次CheckPoint数据,则只能从上一次的CheckPoint数据恢复,上次CheckPoint到故障前一刻的训练迭代需要重新计算,损失较大。通过TTP特性,在故障发生后,立即生成一次CheckPoint数据,恢复时也能立即恢复到故障前一刻的状态,减少迭代损失。
MindIO故障快速恢复架构
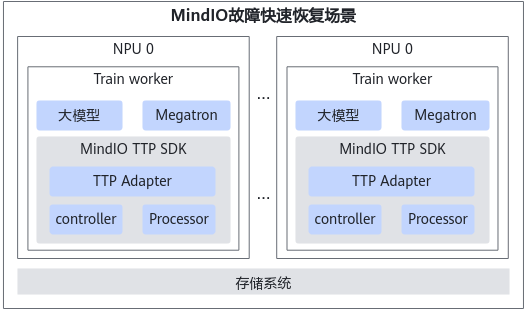
MindIO故障快速恢复的各个功能集成在一个whl包中对外提供,需要通过import模块的方式使用对应功能。MindIO故障快速恢复的关键点如下:
- MindIO TTP通过修改ModelLink等大模型框架适配TTP;通过TTP的controller和processor模块,检测模型训练状态和NPU硬件状态;通过心跳定期汇报至controller模块。一旦检测到故障,就开始临终CheckPoint保存。
- 大模型训练中业界定期保存CheckPoint的时间间隔长。如果发生故障时,距离上一次保存的时间间隔过长,但又没到下一次保存的时间,此时如果重新训练就会消耗大量时间和资源。TTP提供了几乎零损时间和资源的重新训练方案,即重新训练从上一次故障处开始。
