参数概览
总体约束
在进行模型转换前,请务必查看如下约束要求:
- 如果要将Faster RCNN等网络模型转成适配昇腾AI处理器的离线模型,则务必参见定制网络修改(Caffe)先修改prototxt模型文件。
- 支持原始框架类型为Caffe、TensorFlow、MindSpore、ONNX的模型转换:
- 当原始框架类型为Caffe、MindSpore、ONNX时,输入数据类型为FP32、FP16(通过设置入参--input_fp16_nodes实现,MindSpore框架不支持该参数)、UINT8(通过配置数据预处理--insert_op_conf实现);
- 当原始框架类型为TensorFlow时,输入数据类型为FP16、FP32、UINT8、INT32、INT64、BOOL。
- 当原始框架类型为Caffe时,模型文件(.prototxt)和权重文件(.caffemodel)的op name、op type必须保持名称一致(包括大小写)。
- 当原始框架类型为TensorFlow时,只支持FrozenGraphDef格式。
- 不支持动态shape的输入,例如:NHWC输入为[?,?,?,3]多个维度可任意指定数值。模型转换时需指定固定数值。
- 对于Caffe框架网络模型:输入数据最大支持四维,转维算子(reshape、expanddim等)不能输出五维。
- 模型中的所有层算子除const算子外,输入和输出需要满足dim!=0。
- 只支持算子规格参考中的算子,并需满足算子限制条件。
- 由于软件约束(动态shape场景下暂不支持输入数据为DT_INT8),量化后的部署模型使用ATC工具进行模型转换时,不能使用动态shape相关参数,例如--dynamic_batch_size和--dynamic_image_size等,否则模型转换会失败。
参数概览
图1列出了所有芯片共用的ATC参数(参数只在某些芯片下使用的未列出),其中 表示参数互斥,不能同时使用;关联参数表示需要相互配合或者某些场景下需要配合使用。通过该图,您可以快速了解ATC中的部分参数,更多详细参数请参见表1。
表示参数互斥,不能同时使用;关联参数表示需要相互配合或者某些场景下需要配合使用。通过该图,您可以快速了解ATC中的部分参数,更多详细参数请参见表1。
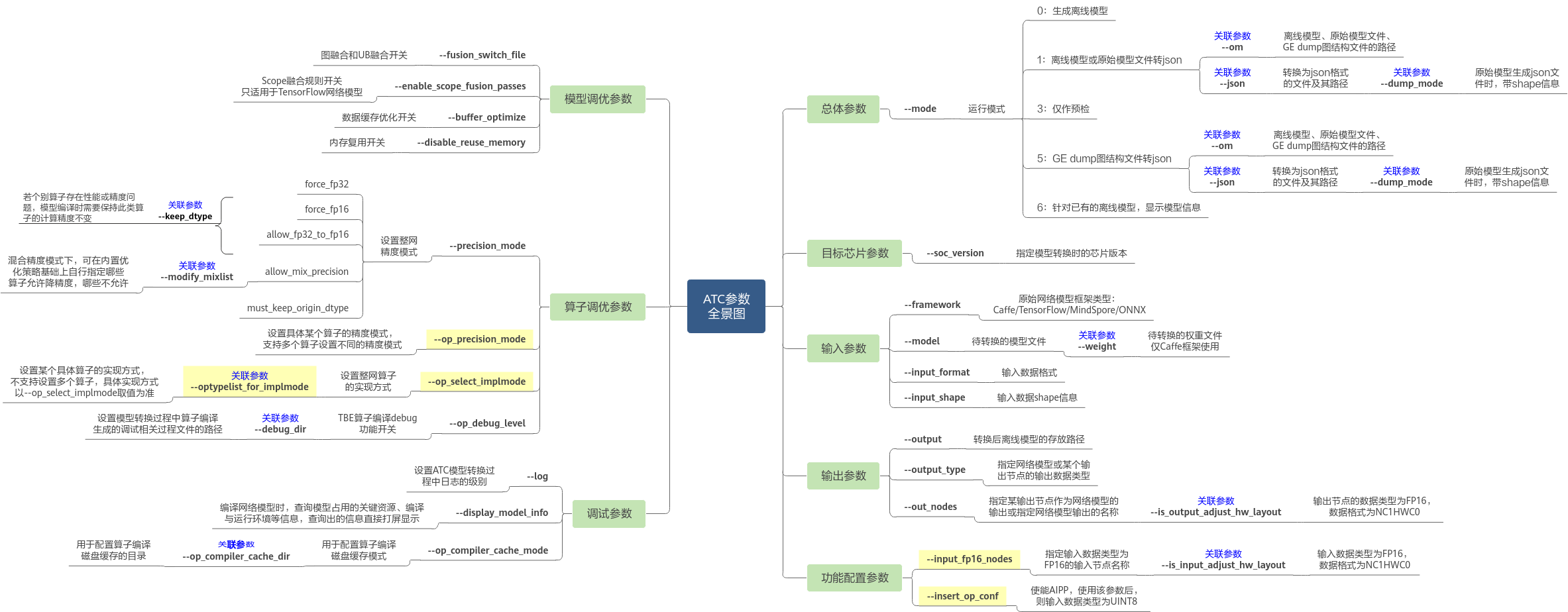

- 如果通过atc --help命令查询出的参数未解释在表1,则说明该参数预留或适用于其他芯片版本,用户无需关注。
- 使用atc命令进行模型转换时,命令有两种方式,用户根据实际情况进行选择:
- atc param1=value1 param2=value2 ...(value值前面不能有空格,否则会导致截断,param取的value值为空)
- atc param1 value1 param2 value2 ...
- 参数是否必选以--mode为0和3为准。
- 使用ATC参数时,参数名支持以--作为前缀(例如--help),也支持以-作为前缀(例如-help),当使用-作为前缀时,在执行atc命令时,会自动转换为--。本文的参数名均以--前缀为例。
- 使用ATC参数时,参数名称支持以下划线连接两个字符串(例如soc_version),也支持以中划线连接两个字符串(例如soc-version)。本文的参数名称均以下划线连接两个字符串(例如soc_version)为例。
ATC参数名称 |
参数简述(具体说明见参数描述章节) |
是否必选 |
默认值 |
|---|---|---|---|
显示帮助信息。 |
否 |
不涉及 |
|
运行模式。 |
否 |
0 |
|
原始模型文件路径与文件名。 |
是 |
不涉及 |
|
权重文件路径与文件名。 |
否 |
不涉及 |
|
需要转换为json格式的离线模型或原始模型文件的路径和文件名。 |
否 |
不涉及 |
|
原始框架类型。 |
是 |
不涉及 |
|
输入数据格式。 |
否 |
Caffe、ONNX默认为NCHW;TensorFlow默认为NHWC。 |
|
模型输入数据的shape。 |
否 |
不涉及 |
|
指定模型输入数据的shape范围。 该参数后续版本会废弃,请勿使用。 |
否 |
不涉及 |
|
设置动态batch档位参数,适用于执行推理时,每次处理图片数量不固定的场景。 |
否 |
不涉及 |
|
设置输入图片的动态分辨率参数。适用于执行推理时,每次处理图片宽和高不固定的场景。 |
否 |
不涉及 |
|
设置ND格式下动态维度的档位。适用于执行推理时,每次处理任意维度的场景。 |
否 |
不涉及 |
|
单算子定义文件,将单个算子json文件转换成适配昇腾AI处理器的离线模型。 |
否 |
不涉及 |
|
|
是 |
不涉及 |
|
指定网络输出数据类型或指定某个输出节点的输出类型。 |
否 |
不涉及 |
|
预检结果保存文件路径和文件名。 |
否 |
check_result.json |
|
离线模型或原始模型文件转换为json格式文件的路径和文件名。 |
否 |
不涉及 |
|
若模型编译环境的操作系统及其架构与模型运行环境不一致时,则需使用本参数设置模型运行环境的操作系统类型。 |
否 |
不涉及 |
|
若模型编译环境的操作系统及其架构与模型运行环境不一致时,则需使用本参数设置模型运行环境的操作系统架构。 |
否 |
不涉及 |
|
模型转换时指定芯片版本。 |
是 |
不涉及 |
|
设置模型编译时使用的aicore数目。 |
否 |
默认值为最大值 |
|
是否支持离线模型在算力分组生成的虚拟设备上运行。 |
否 |
0 |
|
指定输出节点。 |
否 |
不涉及 |
|
指定输入数据类型为FP16的输入节点名称。 |
否 |
不涉及 |
|
插入算子的配置文件路径与文件名,例如aipp预处理算子。 |
否 |
不涉及 |
|
生成om模型文件时,是否将原始网络中的Const/Constant节点的权重保存在单独的文件中,同时将节点类型转换为FileConstant类型。 |
否 |
0 |
|
扩展算子(非标准算子)映射配置文件路径和文件名,不同的网络中某扩展算子的功能不同,可以指定该扩展算子到具体网络中实际运行的扩展算子的映射。 |
否 |
不涉及 |
|
用于指定网络输入数据类型是否为FP16,数据格式是否为NC1HWC0。 |
否 |
false |
|
用于指定网络输出的数据类型是否为FP16,数据格式是否为NC1HWC0。 |
否 |
false |
|
内存复用开关。 |
否 |
0 |
|
融合开关配置文件路径以及文件名。 |
否 |
不涉及 |
|
是否使能small channel的优化,使能后在channel<=4的首层卷积会有性能收益。 |
否 |
0 |
|
压缩优化功能配置文件路径以及文件名。 |
否 |
不涉及 |
|
是否开启数据缓存优化。 |
否 |
l2_optimize |
|
加载模型调优后自定义知识库的路径。 |
否 |
${HOME}/Ascend/latest/data/aoe/custom/graph/<soc_version> |
|
使能全局稀疏特性。 |
否 |
0 |
|
设置网络模型的精度模式。 |
否 |
force_fp16 |
|
设置网络模型的精度模式。 |
否 |
fp16 |
|
设置具体某个算子的精度模式,通过该参数可以为不同的算子设置不同的精度模式。 |
否 |
不涉及 |
|
混合精度场景下,修改算子使用混合精度名单。 |
否 |
不涉及 |
|
设置网络模型中算子是高精度实现模式还是高性能实现模式。 |
否 |
high_performance |
|
设置optype列表中算子的实现模式,算子实现模式包括high_precision、high_performance两种。 |
否 |
不涉及 |
|
保持原始模型编译时个别算子的计算精度不变。 |
否 |
不涉及 |
|
模型编译时自定义算子的计算精度。 |
否 |
不涉及 |
|
加载AOE调优后自定义知识库的路径。 |
否 |
默认自定义知识库路径$HOME/Ascend/latest/data/aoe/custom/op |
|
TBE算子编译debug功能开关。 |
否 |
0 |
|
是否生成带shape信息的json文件。 |
否 |
0 |
|
设置ATC模型转换过程中显示日志的级别。 |
否 |
null |
|
用于配置保存模型转换、网络迁移过程中算子编译生成的调试相关过程文件的路径,包括算子.o/.json/.cce等文件。 |
否 |
./kernel_meta |
|
用于配置算子编译磁盘缓存模式。 |
否 |
disable |
|
用于配置算子编译磁盘缓存的目录。 |
否 |
$HOME/atc_data |
|
模型编译时或对已有的离线模型,查询模型占用的关键资源信息、编译与运行环境等信息。 |
否 |
0 |
|
图编译时Shape的编译方式。 该参数后续版本会废弃,请勿使用。 |
否 |
shape_precise |
|
控制编译算子时是否添加溢出检测逻辑。 |
否 |
0 |
|
使能Global Memory(DDR)内存检测功能的配置文件路径及文件名。 |
否 |
不涉及 |
|
是否集中清理网络中所有atomic算子(含有atomic属性的算子都是atomic算子)占用的内存。 |
否 |
0 |