LoadData
功能说明
LoadData分为Load2D和Load3D,其功能分别如下:
函数原型
- Load2D接口
1 2 3 4
template <typename T> void LoadData(const LocalTensor<T>& dstLocal, const LocalTensor<T>& srcLocal, const LoadData2DParams& loadDataParams) template <typename T> void LoadData(const LocalTensor<T>& dstLocal, const GlobalTensor<T>& srcLocal, const LoadData2DParams& loadDataParams)
- Load3Dv1接口
1 2
template <typename T, const IsResetLoad3dConfig &defaultConfig = IS_RESER_LOAD3D_DEFAULT_CONFIG> LoadData(const LocalTensor<T>& dstLocal, const LocalTensor<T>& srcLocal,const LoadData3DParamsV1<T>& loadDataParams)
- Load3Dv2接口
1 2
template <typename T, const IsResetLoad3dConfig &defaultConfig = IS_RESER_LOAD3D_DEFAULT_CONFIG> LoadData(const LocalTensor<T>& dstLocal, const LocalTensor<T>& srcLocal,const LoadData3DParamsV2<T>& loadDataParams)
参数说明
|
参数名称 |
含义 |
||||
|---|---|---|---|---|---|
|
T |
源操作数和目的操作数的数据类型。 load2d接口: Atlas 训练系列产品,支持的数据类型为:uint8_t, int8_t, uint16_t, int16_t, half。 Atlas推理系列产品AI Core,支持的数据类型为:uint8_t, int8_t, uint16_t, int16_t, half。 Atlas A2训练系列产品/Atlas 800I A2推理产品,支持数据类型:uint8_t, int8_t, uint16_t, int16_t, half, bfloat16_t, uint32_t, int32_t, float。 Atlas 200/500 A2推理产品, 支持数据类型:uint8_t, int8_t, uint16_t, int16_t, half, bfloat16_t, uint32_t, int32_t, float。 load3dv1接口: Atlas 训练系列产品,支持的数据类型为:uint8_t, int8_t, half。 Atlas推理系列产品AI Core,支持的数据类型为:uint8_t, int8_t, half。 load3dv2接口: Atlas推理系列产品AI Core,支持的数据类型为:uint8_t, int8_t, half。 Atlas A2训练系列产品/Atlas 800I A2推理产品,
Atlas 200/500 A2推理产品,
|
||||
|
defaultConfig |
控制是否在Load3Dv1/Load3Dv2接口内部设置相关属性。 IsResetLoad3dConfig类型。IsResetLoad3dConfig结构定义如下:
isSetFMatrix配置为true,表示在接口内部设置FeatureMap的属性描述(包括l1H、l1W、padList,参数介绍参考表4 LoadData3DParamsV1结构体内参数说明、表5 LoadData3DParamsV2结构体内参数说明);设置为false,表示该接口传入的FeatureMap的属性描述不生效,开发者需要通过SetFmatrix进行设置。 isSetPadding配置为true, 表示在接口内部设置Pad属性描述(即padValue参数,参数介绍参考表4 LoadData3DParamsV1结构体内参数说明、表5 LoadData3DParamsV2结构体内参数说明);设置为false,表示该接口传入的Pad属性不生效,开发者需要通过SetLoadDataPaddingValue进行设置。可参考样例调用示例 该参数的默认值如下:
|
|
参数名称 |
输入/输出 |
含义 |
|---|---|---|
|
dstLocal |
输出 |
目的操作数,类型为LocalTensor。目的操作数的起始地址对齐约束请参考表6。 数据连续排列顺序由目的操作数所在TPosition决定,具体约束如下:
|
|
srcLocal |
输入 |
源操作数,类型为LocalTensor或GlobalTensor。源操作数的起始地址对齐约束请参考表6。 数据类型需要与dstLocal保持一致。 |
|
loadDataParams |
输入 |
LoadData参数结构体,类型为: |
|
参数名称 |
输入/输出 |
含义 |
|---|---|---|
|
startIndex |
输入 |
分形矩阵ID,说明搬运起始位置为源操作数中第几个分形(0为源操作数中第1个分形矩阵)。取值范围:startIndex∈[0, 65535] 。单位:512B。默认为0。 |
|
repeatTimes |
输入 |
迭代次数,每个迭代可以处理512B数据。取值范围:repeatTimes∈[1, 255]。 |
|
srcStride |
输入 |
相邻迭代间,源操作数前一个分形与后一个分形起始地址的间隔,单位:512B。取值范围:src_stride∈[0, 65535]。默认为0。 |
|
sid |
输入 |
预留参数,配置为0即可。 |
|
dstGap |
输入 |
相邻迭代间,目的操作数前一个分形结束地址与后一个分形起始地址的间隔,单位:512B。取值范围:dstGap∈[0, 65535]。默认为0。 注:Atlas 训练系列产品此参数不使能。 |
|
ifTranspose |
输入 |
是否启用转置功能,对每个分形矩阵进行转置,默认为false:
注意:只有A1->A2和B1->B2通路才能使能转置,使能转置功能时,源操作数、目的操作数仅支持uint16_t, int16_t, half数据类型。 |
|
addrMode |
输入 |
预留参数,配置为0即可。 |
|
参数名称 |
输入/输出 |
含义 |
|---|---|---|
|
padList |
输入 |
padding列表 [padding_left, padding_right, padding_top, padding_bottom],每个元素取值范围:[0,255]。默认为{0, 0, 0, 0}。 |
|
l1H |
输入 |
源操作数 height,取值范围:l1H∈[1, 32767]。 |
|
l1W |
输入 |
源操作数 width,取值范围:l1W∈[1, 32767] 。 |
|
c1Index |
输入 |
该指令在源tensor C1维度的起点,取值范围:c1Index∈[0, 4095] 。默认为0。 |
|
fetchFilterW |
输入 |
该指令在卷积核上w维度的起始位置,取值范围:fetchFilterW∈[0, 254] 。默认为0。 |
|
fetchFilterH |
输入 |
该指令在filter上h维度的起始位置,取值范围:fetchFilterH∈[0, 254] 。默认为0。 |
|
leftTopW |
输入 |
该指令在源操作数上w维度的起点,取值范围:leftTopW∈[-255, 32767] 。默认为0。如果padding_left = a,leftTopW配置为-a。 |
|
leftTopH |
输入 |
该指令在源操作数上h维度的起点,取值范围:leftTopH∈[-255, 32767] 。默认为0。如果padding_top = a,leftTopH配置为-a。 |
|
strideW |
输入 |
卷积核在源操作数w维度滑动的步长,取值范围:strideW∈[1, 63] 。 |
|
strideH |
输入 |
卷积核在源操作数h维度滑动的步长,取值范围:strideH∈[1, 63] 。 |
|
filterW |
输入 |
卷积核width,取值范围:filterW∈[1, 255] 。 |
|
filterH |
输入 |
卷积核height,取值范围:filterH∈[1, 255] 。 |
|
dilationFilterW |
输入 |
卷积核width膨胀系数,取值范围:dilationFilterW∈[1, 255] 。 |
|
dilationFilterH |
输入 |
卷积核height膨胀系数,取值范围:dilationFilterH∈[1, 255] 。 |
|
jumpStride |
输入 |
迭代之间,目的操作数首地址步长,取值范围:jumpStride∈[1, 127] 。 |
|
repeatMode |
输入 |
迭代模式。
取值范围:repeatMode∈[0, 1] 。默认为0。 |
|
repeatTime |
输入 |
迭代次数,每一次源操作数和目的操作数的地址都会改变。取值范围:repeatTime∈[1,255] 。 |
|
cSize |
输入 |
配置是否开启cSize = 4(b16) / cSize = 8(b8)优化,取值范围:cSize∈[0, 1] 。默认为0。 |
|
padValue |
输入 |
Pad填充值的数值,数据类型需要与srcLocal保持一致。默认为0。若不想使能padding,可将padList设为全0。 |
|
参数名称 |
输入/输出 |
含义 |
|---|---|---|
|
padList |
输入 |
padding 列表 [padding_left, padding_right, padding_top, padding_bottom],每个元素取值范围:[0,255]。默认为{0, 0, 0, 0}。 |
|
l1H |
输入 |
源操作数height,取值范围:l1H∈[1, 32767]。 |
|
l1W |
输入 |
源操作数weight,取值范围:l1W∈[1, 32767] 。 |
|
channelSize |
输入 |
源操作数的通道数,取值范围:channelSize∈[1, 63] 。 针对以下型号,channelSize的取值要求为:对于half,channelSize可取值为4,8,16,N * 16 + 4,N * 16 + 8;对于int8_t/uint8_t,channelSize可取值为4,8,16,32,N * 32 + 4,N * 32 + 8,N * 32 + 16。N为正整数。 Atlas推理系列产品AI Core 针对以下型号,channelSize的取值要求为:对于uint32_t/int32_t/float,channelSize可取值为4,N * 8,N * 8 + 4;对于half/bfloat16,channelSize可取值为4,8,N * 16,N * 16 + 4,N * 16 + 8;对于int8_t/uint8_t,channelSize可取值为4,8,16, 32 * N,N * 32 + 4,N * 32 + 8,N * 32 + 16;对于int4b_t,ChannelSize可取值为8,16,32,N * 64,N * 64 + 8,N * 64 + 16,N * 64 + 32。N为正整数。 Atlas A2训练系列产品/Atlas 800I A2推理产品 Atlas 200/500 A2推理产品 |
|
kExtension |
输入 |
该指令在目的操作数width维度的传输长度,如果不覆盖最右侧的分形,对于half类型,应为16的倍数,对于int8_t/uint8_t应为32的倍数。取值范围: kExtension∈[1, 65535] 。 |
|
mExtension |
输入 |
该指令在目的操作数height维度的传输长度,如果不覆盖最下侧的分形,对于half/int8_t/uint8_t,应为16的倍数。取值范围:mExtension∈[1, 65535] 。 |
|
kStartPt |
输入 |
该指令在目的操作数width维度的起点,对于half类型,应为16的倍数,对于int8_t/uint8_t应为32的倍数。取值范围[0, 65535] 。默认为0。 |
|
mStartPt |
输入 |
该指令在目的操作数height维度的起点,如果不覆盖最下侧的分形,对于half/int8_t/uint8_t,应为16的倍数。取值范围[0, 65535] 。默认为0。 |
|
strideW |
输入 |
卷积核在源操作数width维度滑动的步长,取值范围:strideW∈[1, 63] 。 |
|
strideH |
输入 |
卷积核在源操作数height 维度滑动的步长,取值范围:strideH∈[1, 63] 。 |
|
filterW |
输入 |
卷积核width,取值范围:filterW∈[1, 255] 。 |
|
filterH |
输入 |
卷积核height,取值范围:filterH∈[1, 255] 。 |
|
dilationFilterW |
输入 |
卷积核width膨胀系数,取值范围:dilationFilterW∈[1, 255] 。 |
|
dilationFilterH |
输入 |
卷积核height膨胀系数,取值范围:dilationFilterH∈[1, 255] 。 |
|
enTranspose |
输入 |
是否启用转置功能,对整个目标矩阵进行转置,支持数据类型为 bool,仅在目的QuePosition为A2,且源操作数为half类型时有效。默认为false。
|
|
enSmallK |
输入 |
是否使能small k特性,每个分形矩阵大小为16*4,支持数据类型为 bool,默认为false。当前产品形态,该特性已不再支持。
|
|
padValue |
输入 |
Pad填充值的数值,数据类型需要与srcLocal保持一致。默认为0。若不想使能padding,可将padList设为全0。 |
支持的型号
注意事项
- 操作数的起始地址对齐要求如下:
- LoadData3DParamsV1 cSize特性的开启,需要保证A1/B1中的 feature map 为 4 channel对齐的。
- 不使用或者不想改变的配置,建议保持默认值,有助于性能提升。
load3d数据格式说明
要求输入的feature map和filter的格式是 NC1HWC0,其中 C0 是最低维度而且 C0 是固定值为 16(对于u8/s8类型为32),C1=C/C0。
为了简化场景,以下场景假设输入的 feature map 的 channel 为4,即 Ci=4。输入 feature maps 在 A1 中的形状为 (Hi,Wi,Ci),经过 load3dv1 处理后在 A2 的数据形状为(Wo*Ho, Hk*Wk*Ci)。其中 Wo 和 Ho 是卷积后输出的shape,Hk 和 Wk 是 filter 的 shape。
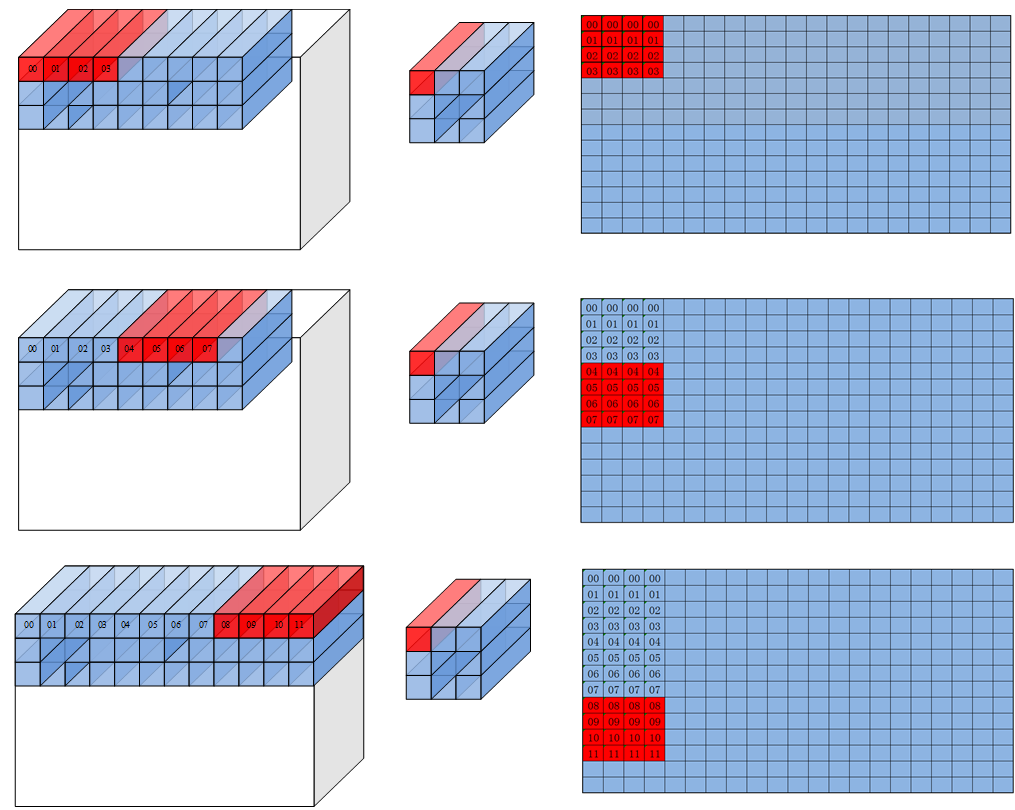
直观的来看,img2col 的过程就是 filter 在 feature map 上扫过,将对应 feature map 的数据展开成输出数据的每一行的过程。filter 首先在W方向上滑动 Wo 步,然后在 H 方向上走一步然后重复以上过程,最终输出 Wo*Ho 行数据。下图中红色和黄色的数据分别代表第一行和第二行。数字表示原始输入数据,filter 和输出数据三者之间的关联关系。可以看到,load3dv1 首先在输入数据的 Ci 维度搬运对应于 00 的 4 个数,然后搬运对应于 01 的四个数,最终这一行的大小为 Hk*Wk*Ci 即 3*3*4=36 个数。
对应的feature map格式如下图:
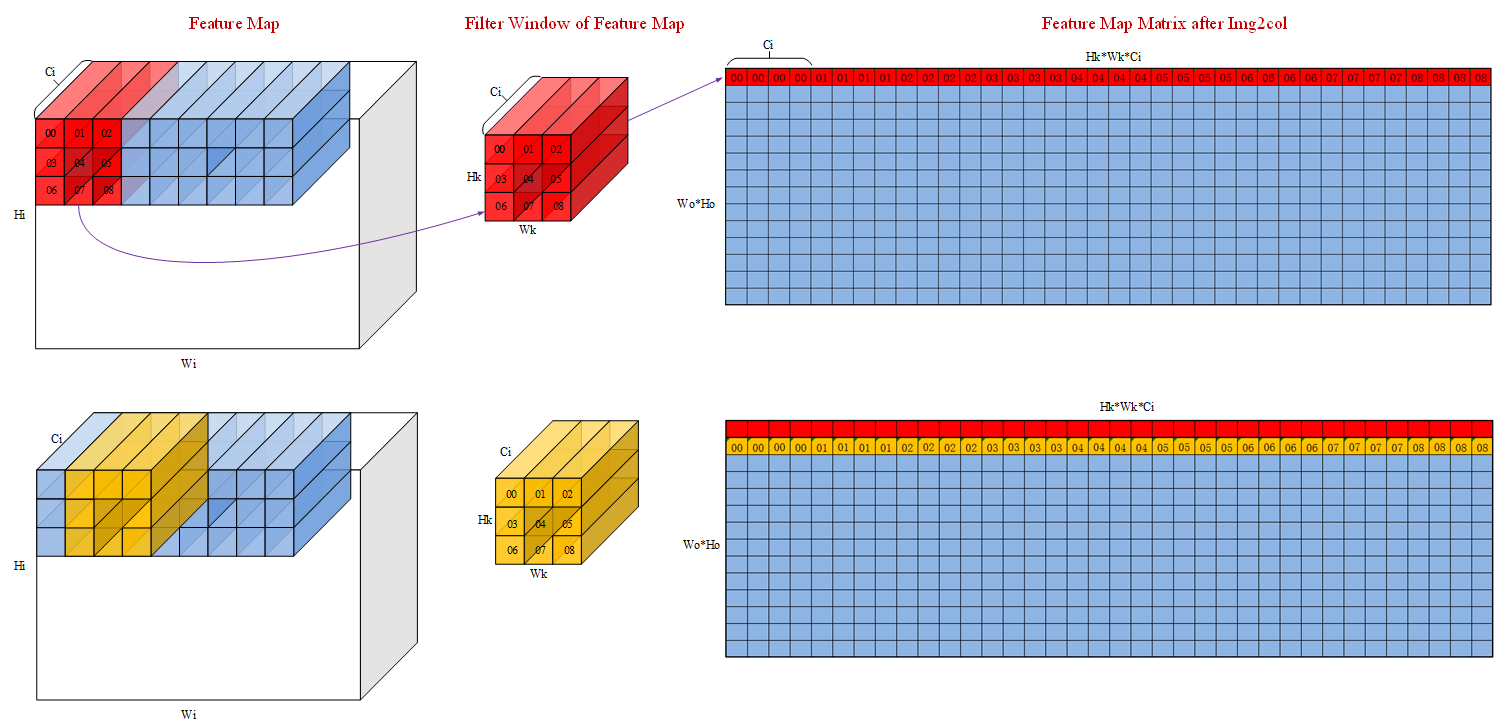
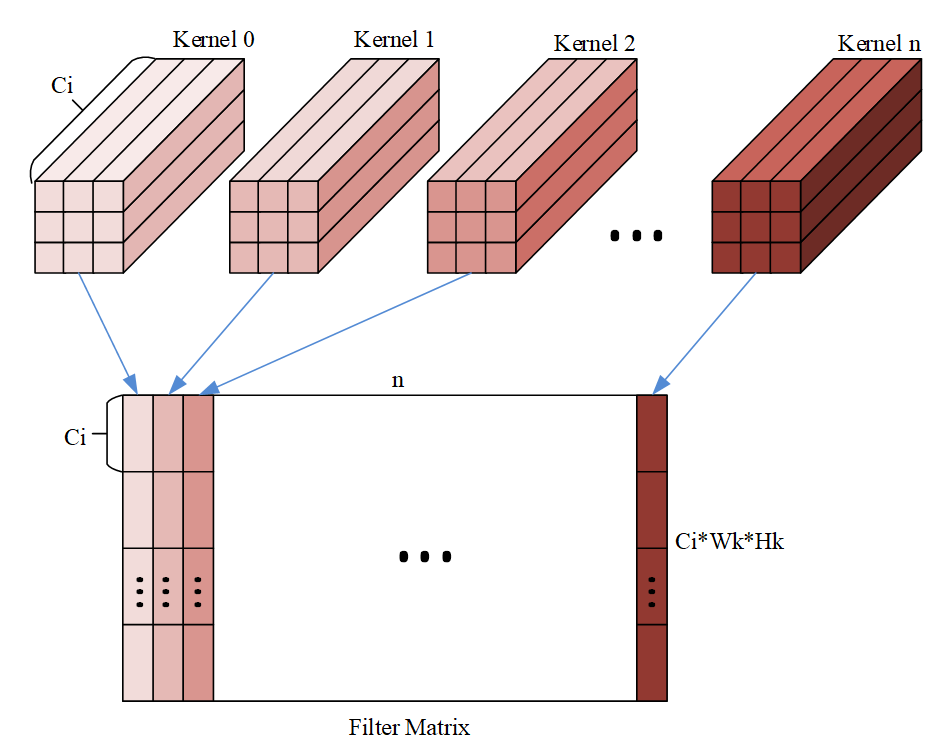
对应的 filter 的格式如下图:
其中 n 为 filter 的个数,可以看出维度排布为 (Hk,Wk,Ci,n),但是需要注意的是下图的格式还需要根据 mmad 中 B 矩阵的格式转换。
实际操作中,由于存储空间或者计算能力限制,我们通常会将整个卷积计算分块,一次只搬运并计算一小块数据。
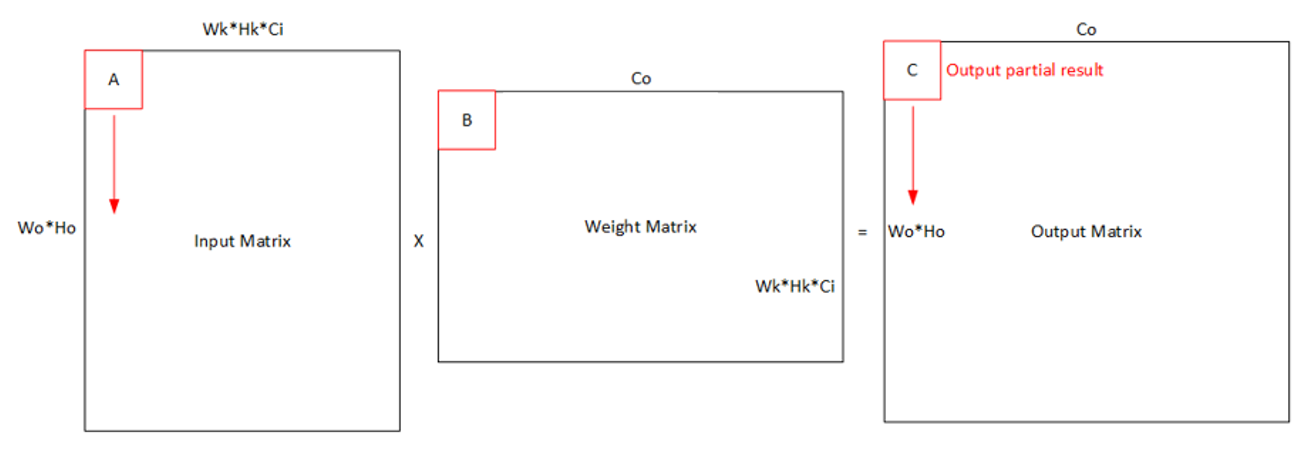
对于 A2 的 feature map 来说有两种方案,水平分块和垂直分块。分别对应参数中 repeatMode 的 0 和 1。
注:下图中的分型矩阵大小为 4x4,实际应该为 16x16 (对于 u8/s8 类型为 16x32)
repeatMode =0 时,每次 repeat 会改变在 filter 窗口中读取数据点的位置,然后跳到下一个 C0 的位置。
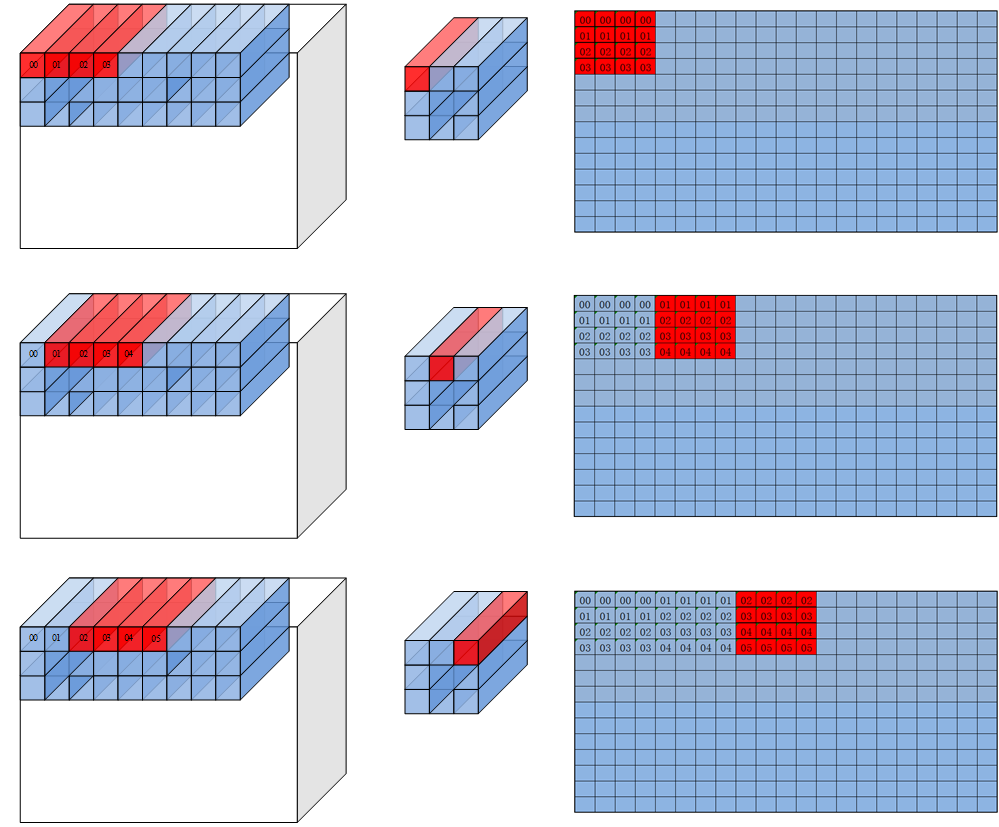
repeatMode =1 的时候 filter 窗口中读取数据的位置保持不变,每个 repeat 在 feature map 中前进 C0 个元素。
返回值
无
调用示例
该调用示例支持的运行平台为Atlas推理系列产品AI Core。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 |
#include "kernel_operator.h" class KernelLoadData { public: __aicore__ inline KernelLoadData() { coutBlocks = (Cout + 16 - 1) / 16; ho = (H + padTop + padBottom - dilationH * (Kh - 1) - 1) / strideH + 1; wo = (W + padLeft + padRight - dilationW * (Kw - 1) - 1) / strideW + 1; howo = ho * wo; howoRound = ((howo + 16 - 1) / 16) * 16; featureMapA1Size = C1 * H * W * C0; // shape: [C1, H, W, C0] weightA1Size = C1 * Kh * Kw * Cout * C0; // shape: [C1, Kh, Kw, Cout, C0] featureMapA2Size = howoRound * (C1 * Kh * Kw * C0); weightB2Size = (C1 * Kh * Kw * C0) * coutBlocks * 16; m = howo; k = C1 * Kh * Kw * C0; n = Cout; dstSize = coutBlocks * howo * 16; // shape: [coutBlocks, howo, 16] dstCO1Size = coutBlocks * howoRound * 16; fmRepeat = featureMapA2Size / (16 * C0); weRepeat = weightB2Size / (16 * C0); } __aicore__ inline void Init(__gm__ uint8_t* fmGm, __gm__ uint8_t* weGm, __gm__ uint8_t* dstGm) { fmGlobal.SetGlobalBuffer((__gm__ half*)fmGm); weGlobal.SetGlobalBuffer((__gm__ half*)weGm); dstGlobal.SetGlobalBuffer((__gm__ half*)dstGm); pipe.InitBuffer(inQueueFmA1, 1, featureMapA1Size * sizeof(half)); pipe.InitBuffer(inQueueFmA2, 1, featureMapA2Size * sizeof(half)); pipe.InitBuffer(inQueueWeB1, 1, weightA1Size * sizeof(half)); pipe.InitBuffer(inQueueWeB2, 1, weightB2Size * sizeof(half)); pipe.InitBuffer(outQueueCO1, 1, dstCO1Size * sizeof(float)); pipe.InitBuffer(outQueueUB, 1, dstSize * sizeof(half)); } __aicore__ inline void Process() { CopyIn(); Split(); Compute(); CopyUB(); CopyOut(); } private: __aicore__ inline void CopyIn() { AscendC::LocalTensor<half> featureMapA1 = inQueueFmA1.AllocTensor<half>(); AscendC::LocalTensor<half> weightB1 = inQueueWeB1.AllocTensor<half>(); AscendC::DataCopy(featureMapA1, fmGlobal, { 1, static_cast<uint16_t>(featureMapA1Size * sizeof(half) / 32), 0, 0 }); AscendC::DataCopy(weightB1, weGlobal, { 1, static_cast<uint16_t>(weightA1Size * sizeof(half) / 32), 0, 0 }); inQueueFmA1.EnQue(featureMapA1); inQueueWeB1.EnQue(weightB1); } __aicore__ inline void Split() { AscendC::LocalTensor<half> featureMapA1 = inQueueFmA1.DeQue<half>(); AscendC::LocalTensor<half> weightB1 = inQueueWeB1.DeQue<half>(); AscendC::LocalTensor<half> featureMapA2 = inQueueFmA2.AllocTensor<half>(); AscendC::LocalTensor<half> weightB2 = inQueueWeB2.AllocTensor<half>(); uint8_t padList[4] = {padTop, padBottom, padLeft, padRight}; AscendC::LoadData(featureMapA2, featureMapA1, { padList, H, W, 0, 0, 0, -1, -1, strideW, strideH, Kw, Kh, dilationW, dilationH, 1, 0, fmRepeat, 0, (half)(0)}); AscendC::LoadData(weightB2, weightB1, { 0, weRepeat, 1, 0, 0, false, 0 }); inQueueFmA2.EnQue<half>(featureMapA2); inQueueWeB2.EnQue<half>(weightB2); inQueueFmA1.FreeTensor(featureMapA1); inQueueWeB1.FreeTensor(weightB1); } __aicore__ inline void Compute() { AscendC::LocalTensor<half> featureMapA2 = inQueueFmA2.DeQue<half>(); AscendC::LocalTensor<half> weightB2 = inQueueWeB2.DeQue<half>(); AscendC::LocalTensor<float> dstCO1 = outQueueCO1.AllocTensor<float>(); AscendC::Mmad(dstCO1, featureMapA2, weightB2, { m, n, k, 0, false, true }); outQueueCO1.EnQue<float>(dstCO1); inQueueFmA2.FreeTensor(featureMapA2); inQueueWeB2.FreeTensor(weightB2); } __aicore__ inline void CopyUB() { AscendC::LocalTensor<float> dstCO1 = outQueueCO1.DeQue<float>(); AscendC::LocalTensor<half> dstUB = outQueueUB.AllocTensor<half>(); AscendC::DataCopyParams dataCopyParams; dataCopyParams.blockCount = 1; dataCopyParams.blockLen = m * n * sizeof(float) / 1024; AscendC::DataCopyEnhancedParams enhancedParams; enhancedParams.blockMode = AscendC::BlockMode::BLOCK_MODE_MATRIX; AscendC::DataCopy(dstUB, dstCO1, dataCopyParams, enhancedParams); outQueueUB.EnQue<half>(dstUB); outQueueCO1.FreeTensor(dstCO1); } __aicore__ inline void CopyOut() { AscendC::LocalTensor<half> dstUB = outQueueUB.DeQue<half>(); AscendC::DataCopy(dstGlobal, dstUB, m * n); outQueueUB.FreeTensor(dstUB); } private: AscendC::TPipe pipe; // feature map queue AscendC::TQue<AscendC::QuePosition::A1, 1> inQueueFmA1; AscendC::TQue<AscendC::QuePosition::A2, 1> inQueueFmA2; // weight queue AscendC::TQue<AscendC::QuePosition::B1, 1> inQueueWeB1; AscendC::TQue<AscendC::QuePosition::B2, 1> inQueueWeB2; // dst queue AscendC::TQue<AscendC::QuePosition::CO1, 1> outQueueCO1; AscendC::TQue<AscendC::QuePosition::CO2, 1> outQueueUB; AscendC::GlobalTensor<half> fmGlobal, weGlobal, dstGlobal; uint16_t C1 = 2; uint16_t H = 4, W = 4; uint8_t Kh = 2, Kw = 2; uint16_t Cout = 16; uint16_t C0 = 16; uint8_t dilationH = 2, dilationW = 2; uint8_t padTop = 1, padBottom = 1, padLeft = 1, padRight = 1; uint8_t strideH = 1, strideW = 1; uint16_t coutBlocks, ho, wo, howo, howoRound; uint32_t featureMapA1Size, weightA1Size, featureMapA2Size, weightB2Size, dstSize, dstCO1Size; uint16_t m, k, n; uint8_t fmRepeat, weRepeat; }; extern "C" __global__ __aicore__ void load_data_simple_kernel(__gm__ uint8_t* fmGm, __gm__ uint8_t* weGm, __gm__ uint8_t* dstGm) { KernelLoadData op; op.Init(fmGm, weGm, dstGm); op.Process(); } |