接口调用流程
开发应用时,如果涉及执行单个算子,则应用程序中必须包含执行单个算子的代码逻辑。关于执行单个算子的接口调用流程,请先参见pyACL接口调用流程了解整体流程,再查看本节中的流程说明。
对于系统不支持的算子,用户需先参见《Ascend C自定义算子开发指南》完成自定义算子开发。

图1 算子调用流程
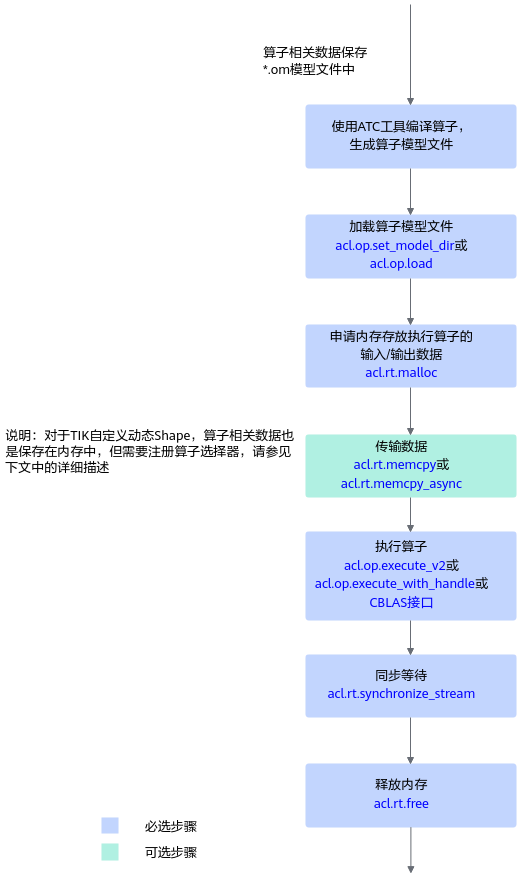
关键接口的说明如下:
- 加载算子模型文件。
- 调用acl.rt.malloc接口申请Device上的内存,存放执行算子的输入、输出数据。
如果需要将Host上数据传输到Device,则需要调用acl.rt.memcpy接口(同步接口)或acl.rt.memcpy_async接口(异步接口)通过内存复制的方式实现数据传输。
- 动态Shape场景,如果无法明确算子的输出Shape时,在执行算子前,还需推导或预估算子的输出Shape。
需用户调用acl.op.infer_shape接口、acl.get_tensor_desc_num_dims接口、acl.get_tensor_desc_dim_v2接口、acl.get_tensor_desc_dim_range等接口,推导或预估算子的输出Shape,作为算子执行接口acl.op.execute_v2的输入。
- 执行算子。
- 对于被封装成pyACL接口的算子(参见调用CBLAS接口),包括GEMM算子、Cast算子,目前支持以下两种执行方式:
- 对于未被封装成pyACL接口的算子,目前执行以下两种执行方式:
- 调用acl.rt.synchronize_stream接口阻塞应用运行,直到指定Stream中的所有任务都完成。
- 调用acl.rt.free接口释放内存。
如果需要将Device上的算子执行结果数据传输到Host,则需要调用acl.rt.memcpy接口(同步接口)或acl.rt.memcpy_async接口(异步接口)通过内存复制的方式实现数据传输,然后再释放内存。
父主题: 单算子调用