'%20fill='%23C31D20'%20fill-rule='nonzero'%3e%3cpath%20d='M7.55269822,13.7609409%20C10.8552199,9.97176134%2014.2271223,7.63452926%2017.1034483,6.5677512%20L17.0816429,0.884990191%20C17.0593112,0.508963963%2016.8188535,0.182653682%2016.4703158,0.055395956%20C16.1217781,-0.0718617705%2015.7322263,0.0244201241%2015.4799397,0.300178022%20L12.9584465,3.07097775%20L0.368821458,17.4916392%20C0.0232151224,17.8857306%20-0.0894678188,18.437454%200.0732192079,18.9389805%20C0.235906234,19.4405071%200.649247199,19.815643%201.15754056,19.9230783%20C1.66583392,20.0305135%202.19185783,19.853926%202.53746417,19.4598346%20L7.5467513,13.7690073%20L7.55269822,13.7609409%20Z'%20id='路径'%3e%3c/path%3e%3cpath%20d='M10.6896552,12.0927463%20L15.1004089,17.5535201%20C15.4511303,17.8402432%2015.9409156,17.8973222%2016.3502521,17.6991755%20C16.7595885,17.5010287%2017.0117165,17.0848129%2016.993637,16.6370685%20L17.1034483,10.0202479%20C14.5615201,9.75868982%2012.477139,10.7130773%2010.6896552,12.0927463%20Z'%20id='路径'%3e%3c/path%3e%3c/g%3e%3crect%20id='矩形'%20x='0'%20y='0'%20width='24'%20height='24'%3e%3c/rect%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
快速入门
对于核函数直调工程算子开发场景,调测流程如图1所示,支持的调测功能有Tiling调测、CPU孪生调试、NPU编译生成kernel bin文件、NPU上板精度比对、NPU上板Profiling数据采集、性能仿真流水图等。
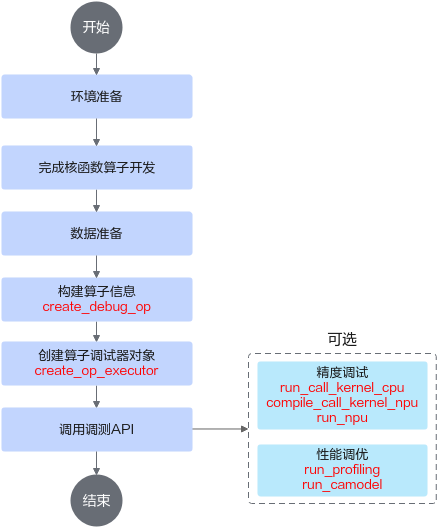
- 环境准备的具体步骤参见环境准备。
- 完成核函数代码开发。
- 准备好输入数据和标杆数据。可使用现成的bin格式数据文件,也可使用torch/numpy生成Tensor数据(具体参见API方式下数据准备说明)。
- 构建算子信息。
调用ascendebug.create_debug_op接口构造算子DebugOp对象 ,并设置输入/输出信息,示例如下:
import torch import numpy as np import ascendebug # 生成输入/标杆数据,并构建算子信息 x = torch.rand(size=(1, 16384), dtype=torch.float16) y = torch.rand(size=(1, 16384), dtype=torch.float16) z = x + y debug_op = ascendebug.create_debug_op('add_custom', 'VectorCore', 'Ascendxxx') \ .scalar_input('tileNumIn', 'uint32', 10) \ .tensor_input('x', x) \ .tensor_input('y', y) \ .tensor_output('z', z) - 创建算子调试器对象,示例如下:
op_executor = ascendebug.create_op_executor(debug_op=debug_op, work_dir='./debug_workspace', install_path='/usr/local/Ascend')
- 构造输入参数,调用调测API,以NPU调测接口为例。
kernel_info = ascendebug.OpKernelInfo("/path_to/add_custom.cpp", 'add_custom', []) npu_option = ascendebug.CompileNpuOptions() kernel_name, kernel_file, extern = op_executor.compile_call_kernel_npu(kernel_info, npu_option) run_npu_options = ascendebug.RunNpuOptions(block_num=32) npu_compile_info = ascendebug.NpuCompileInfo(syncall=extern['cross_core_sync'], task_ration=extern['task_ration']) op_executor.run_npu(kernel_file, npu_options=run_npu_options, npu_compile_info=npu_compile_info)
使用的API接口列表
本场景涉及的所有调测API如表1所示。
父主题: 核函数直调工程场景的算子调测示例
