Duplicate
功能说明
将一个变量或一个立即数,复制多次并填充到向量,其中PAR表示矢量计算单元一个迭代能够处理的元素个数:
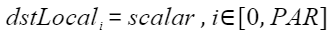
函数原型
- tensor前n个数据计算
template <typename T> void Duplicate(const LocalTensor<T>& dstLocal, const T& scalarValue, const int& calCount);
- tensor高维切分计算
- mask逐bit模式
template <typename T> void Duplicate(const LocalTensor<T>& dstLocal, const T& scalarValue, uint64_t mask[2], const uint8_t repeatTimes, const uint16_t dstBlockStride, const uint8_t dstRepeatStride);
- mask连续模式
template <typename T> void Duplicate(const LocalTensor<T>& dstLocal, const T& scalarValue, uint64_t mask, const uint8_t repeatTimes, const uint16_t dstBlockStride, const uint8_t dstRepeatStride);
- mask逐bit模式
参数说明
参数名称 |
输入/输出 |
含义 |
|---|---|---|
dstLocal |
输出 |
目的操作数。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 Atlas 训练系列产品,支持的数据类型为:uint16_t/int16_t/half/uint32_t/int32_t/float Atlas推理系列产品AI Core,支持的数据类型为:uint16_t/int16_t/half/uint32_t/int32_t/float Atlas A2训练系列产品/Atlas 800I A2推理产品,支持的数据类型为:uint16_t/int16_t/half/uint32_t/int32_t/float/bfloat16_t |
scalarValue |
输入 |
被复制的源操作数,支持输入变量和立即数,数据类型需与dstLocal中元素的数据类型保持一致。 |
calCount |
输入 |
输入数据元素个数。 |
mask |
输入 |
mask用于控制每次迭代内参与计算的元素。
|
repeatTimes |
输入 |
矢量计算单元,每次读取连续的8个block(每个block32 Bytes,共256 Bytes)数据进行计算,为完成对输入数据的处理,必须通过多次迭代(repeat)才能完成所有数据的读取与计算。Repeat times表示迭代的次数。 |
dstBlockStride |
输入 |
单次迭代内,矢量目的操作数不同block间地址步长。 |
dstRepeatStride |
输入 |
相邻迭代间,矢量目的操作数相同block地址步长。 |
支持的型号
Atlas 训练系列产品
Atlas推理系列产品AI Core
Atlas A2训练系列产品/Atlas 800I A2推理产品
Atlas 200/500 A2推理产品
注意事项
- 操作数地址偏移对齐要求请参见通用约束。
- 用户输入立即数需自行保证不超出dstLocal中元素数据类型对应的大小范围。
返回值
无
调用示例
本样例中只展示Compute流程中的部分代码。如果您需要运行样例代码,请将该代码段拷贝并替换样例模板中的Compute函数粗体部分即可。
- tensor高维切分计算样例-mask连续模式
uint64_t mask = 128; half scalar = 18.0; // repeatTimes = 2, 128 elements one repeat, 256 elements total // dstBlkStride = 1, no gap between blocks in one repeat // dstRepStride = 8, no gap between repeats Duplicate(dstLocal, scalar, mask, 2, 1, 8 );
- tensor高维切分计算样例-mask逐bit模式
uint64_t mask[2] = { UINT64_MAX, UINT64_MAX }; half scalar = 18.0; // repeatTimes = 2, 128 elements one repeat, 256 elements total // dstBlkStride = 1, no gap between blocks in one repeat // dstRepStride = 8, no gap between repeats Duplicate(dstLocal, scalar, mask, 2, 1, 8 );
- tensor前n个数据计算样例
half inputVal(18.0); Duplicate<half>(dstLocal, inputVal, srcDataSize);
输入数据:[0 1.0 2.0 ... 254.0 255.0] // 不关心输入数据,会被Duplicate盖掉 输出数据:[18.0 18.0 18.0 ... 18.0 18.0]
更多样例
您可以参考以下样例,了解如何使用Duplicate指令的tensor高维切分计算接口,进行更灵活的操作、实现更高级的功能。本样例中只展示Compute流程中的部分代码。如果您需要运行样例代码,请将该代码段拷贝并替换下方样例模板的Compute函数中粗体部分即可(需自行注意数据类型)。
- 通过tensor高维切分计算接口中的mask连续模式,实现数据非连续计算。
uint64_t mask = 64; // 每个迭代内只计算前64个数 half scalar = 18.0; // repeatTimes = 2, 128 elements one repeat, 256 elements total // dstBlkStride = 2, dstRepStride = 8 Duplicate(dstLocal, scalar, mask, 2, 1, 8 );
结果示例如下:
[18.0 18.0 18.0 ... 18.0 undefined ... undefined 18.0 18.0 18.0 ... 18.0 undefined ... undefined ](每段计算结果或undefined数据长64)
- 通过tensor高维切分计算接口中的mask逐bit模式,实现数据非连续计算。
uint64_t mask[2] = { UINT64_MAX, 0 }; // mask[0]满,mask[1]空,每次只计算前64个数 half scalar = 18.0; // repeatTimes = 2, 128 elements one repeat, 512 elements total // dstBlkStride = 1, no gap between blocks in one repeat // dstRepStride = 8, no gap between repeats Duplicate(dstLocal, scalar, mask, 2, 1, 8);结果示例:输入数据(src0Local): [1.0 2.0 3.0 ... 256.0] 输入数据(src1Local): half scalar = 18.0; 输出数据(dstLocal): [18.0 18.0 18.0 ... 18.0 undefined ... undefined 18.0 18.0 18.0 ... 18.0 undefined ... undefined](每段计算结果或undefined数据长64)
- 通过控制tensor高维切分计算接口的Block Stride参数,实现数据非连续计算。
uint64_t mask = 128; half scalar = 18.0; // repeatTimes = 1, 128 elements one repeat, 256 elements total // dstBlkStride = 2, 1 block gap between blocks in one repeat // dstRepStride = 0, repeatTimes = 1 Duplicate(dstLocal, scalar, mask, 1, 2, 0);
结果示例:输入数据(src0Local): [1.0 2.0 3.0 ... 256.0] 输入数据(src1Local): half scalar = 18.0; 输出数据(dstLocal): [18.0 18.0 18.0 ... 18.0 undefined ... undefined 18.0 18.0 18.0 ... 18.0 undefined ... undefined 18.0 18.0 18.0 ... 18.0 undefined ... undefined 18.0 18.0 18.0 ... 18.0 undefined ... undefined 18.0 18.0 18.0 ... 18.0 undefined ... undefined 18.0 18.0 18.0 ... 18.0 undefined ... undefined 18.0 18.0 18.0 ... 18.0 undefined ... undefined 18.0 18.0 18.0 ... 18.0 undefined ... undefined](每段计算结果长16)
- 通过控制tensor高维切分计算接口的Repeat Stride参数,实现数据非连续计算。
uint64_t mask = 64; half scalar = 18.0; // repeatTimes = 2, 128 elements one repeat, 256 elements total // dstBlkStride = 1, no gap between blocks in one repeat // dstRepStride = 12, 4 blocks gap between repeats Duplicate(dstLocal, scalar, mask, 2, 1, 12);
结果示例:输入数据(src0Local): [1.0 2.0 3.0 ... 256.0] 输入数据(src1Local): half scalar = 18.0; 输出数据(dstLocal): [18.0 18.0 18.0 ... 18.0 undefined ... undefined 18.0 18.0 18.0 ... 18.0](每段计算结果长64,undefined长128)
样例模板
#include "kernel_operator.h"
namespace AscendC {
class KernelDuplicate {
public:
__aicore__ inline KernelDuplicate() {}
__aicore__ inline void Init(__gm__ uint8_t* src, __gm__ uint8_t* dstGm)
{
srcGlobal.SetGlobalBuffer((__gm__ half*)src);
dstGlobal.SetGlobalBuffer((__gm__ half*)dstGm);
pipe.InitBuffer(inQueueSrc, 1, srcDataSize * sizeof(half));
pipe.InitBuffer(outQueueDst, 1, dstDataSize * sizeof(half));
}
__aicore__ inline void Process()
{
CopyIn();
Compute();
CopyOut();
}
private:
__aicore__ inline void CopyIn()
{
LocalTensor<half> srcLocal = inQueueSrc.AllocTensor<half>();
DataCopy(srcLocal, srcGlobal, srcDataSize);
inQueueSrc.EnQue(srcLocal);
}
__aicore__ inline void Compute()
{
LocalTensor<half> srcLocal = inQueueSrc.DeQue<half>();
LocalTensor<half> dstLocal = outQueueDst.AllocTensor<half>();
half inputVal(18.0);
Duplicate<half>(dstLocal, inputVal, srcDataSize);
outQueueDst.EnQue<half>(dstLocal);
inQueueSrc.FreeTensor(srcLocal);
}
__aicore__ inline void CopyOut()
{
LocalTensor<half> dstLocal = outQueueDst.DeQue<half>();
DataCopy(dstGlobal, dstLocal, dstDataSize);
outQueueDst.FreeTensor(dstLocal);
}
private:
TPipe pipe;
TQue<QuePosition::VECIN, 1> inQueueSrc;
TQue<QuePosition::VECOUT, 1> outQueueDst;
GlobalTensor<half> srcGlobal, dstGlobal;
int srcDataSize = 256;
int dstDataSize = 256;
};
} // namespace AscendC
extern "C" __global__ __aicore__ void duplicate_kernel(__gm__ uint8_t* src, __gm__ uint8_t* dstGm)
{
AscendC::KernelDuplicate op;
op.Init(src, dstGm);
op.Process();
}
