CAModel性能仿真
功能介绍
算子可以在仿真器上进行性能仿真,目前主要支持CAModel仿真器。CAModel性能调仿真时,根据输入的kernel.o文件,在仿真器上运行并生成运行log日志,通过解析过程日志生成算子仿真流水图(trace图)。

- 如果用户需要深入分析算子性能瓶颈,可使用CAModel调测生成算子指令流水图。
- 由于model本身存在准确性问题,CAModel建议只跑单核,仿真性能会比较准,多核一块跑比较慢,误差也大很多。
- 开启CAModel后,调测工具不会再进行精度比对。
使用方法(命令行)
- 完成环境搭建,并准备好输入/标杆数据文件。
- 执行如下命令进行CAModel性能仿真,仅提供关键参数项,其余参数请参考Simulator仿真参数按需设置。
ascendebug kernel --backend simulator --json-file ${op_config_json_file} --repo-type ${repo_type} --chip-version ${chip_version} --core-type ${core_type} --install-path ${cann_install_path} --work-dir ${work_dir} --block-num 1 --timeout 1200 ... {其他参数}一般情况下,CAModel仿真时运行比较慢,--timeout一般设置为1200秒,--block-num一般设置为1,用户需按实际情况设置。
- 查看性能仿真结果。CAModel仿真结果文件存放在--work-dir目录下,详细说明参见调测产物。
使用方法(API)
- 完成环境搭建,并准备好输入/标杆数据文件。
- 构建算子信息。调用DebugOp类里input系列接口(如tensor_input、custom_input等),设置算子的输入、输出、属性值等信息。
- 创建调试对象并初始化工作空间。调用create_op_executor接口,创建调试对象op_executor,用户可传入${work_dir}参数手动设置工作空间。
- (可选)参考Tiling调测功能 > 使用方法(API)章节,调用Tiling调测接口生成Tiling Info文件。
本步骤仅适用于没有Tiling Info文件的场景,需调用Tiling调测API生成Tiling Info。
- 调用NPU编译接口,进行算子源码编译,生成kernel.o文件。
- 标准自定义算子场景:调用compile_custom_npu接口。
- 核函数直调场景:调用compile_call_kernel_npu接口。
- ops_adv算子场景:调用compile_ops_adv_npu接口。
- 调用CAModel运行接口run_camodel,在仿真器上运行核函数,生成算子流水图。
- 查看调测产物。CAModel仿真结果文件存放在${work_dir}目录下,详细说明参见调测产物。
调测产物
无论是命令行方式或API方式,CAModel仿真结果存放在${root}/${work_dir}/simulator路径下,包含src、build、output、dump四个文件子目录。其中${root}表示当前操作路径,${work_dir}表示调测工作空间,默认为/debug_workspace/${op_type}目录,${op_type}为算子名。目录结构示例如下:
├ ${op_type}(算子名)
├── simulator
│ ├── build (存放NPU编译生成的中间文件)
│ ├── launch_args.so
│ ├── output (存放NPU编译运行的输出文件)
│ ├── y.bin (运行输出原始数据)
│ ├── src(存放NPU编译生成的临时代码文件)
│ ├── _gen_args_${op_type}.cpp
│ ├── dump(存放仿真运行的文件)
│ ├── camodel
│ ├──log(若为Atlas A2训练系列产品/Atlas 800I A2推理产品,其dump数据和波形数据文件如下)
│ ├──core0.cubecore0.ifu.icache_log.dump
│ ├──core0.cubecore0.instr_log.dump
│ ├──core0.cubecore0.instr_popped_log.dump
│ ├──core0.veccore0.ifu.icache_log.dump
│ ├──core0.veccore0.instr_log.dump
│ ├──core0.veccore0.instr_popped_log.dump
│ ├──core0.veccore1.ifu.icache_log.dump
│ ├──core0.veccore1.instr_log.dump
│ ├──core0.veccore1.instr_popped_log.dump
│ ├──core0.mte_log.dump
│ ├──core0_wave.vcd
│ ├──......
│ ├──log(若为Atlas 推理系列产品,其dump数据和波形数据文件如下)
│ ├──core0_icache_log.dump
│ ├──core0_instr_log.dump
│ ├──core0_instr_popped_log.dump
│ ├──core0_mte_biu_req_log.dump
│ ├──core0_wave.vcd
│ ├──......
│ ├── output(存放最终解析数据)
│ ├── core_0.0.json
│ ├── core_0.1.json
│ ├── core_0.2.json
- 检查dump数据和波形数据:在log目录下,查看是否生成指令集运行的dump数据(.dump)和波形数据(.vcd)文件。
本工具会根据icache_log.dump、instr_popped_log.dump、instr_log.dump、mte_log.dump文件解析生成性能仿真流水图json文件。
表1 性能仿真dump数据文件说明 Atlas A2训练系列产品/Atlas 800I A2推理产品对应的dump文件
Atlas 推理系列产品对应的dump文件
dump文件说明
core${core_id}.${core_type}${sub_core_id}.ifu.icache_log.dump
core${core_id}_icache_log.dump
记录cache指令执行时序情况,可用于分析cache性能。
core${core_id}.${core_type}${sub_core_id}.instr_popped_log.dump
core${core_id}_instr_popped_log.dump
记录指令发射后的日志,包含指令名、指令域段等参数信息
core${core_id}.${core_type}${sub_core_id}.instr_log.dump
core${core_id}_instr_log.dump
记录指令执行完成后的日志,包含指令名、指令域段等参数信息,需与instr_popped_log.dump配套使用。
core${core_id}.mte_log.dump
core${core_id}_mte_biu_req_log.dump
记录pipeline为MTE类(数据搬运)指令执行日志,日志中包含MTE指令的细节,可用于检查MTE类指令执行结果是否正确。
参数说明:
- ${core_id}:计算核id。
- ${core_type}:指令计算单元类型,如cubecore、veccore。
- ${sub_core_id}:计算单元对应的子核id。
- 检查仿真结果文件:在output目录下,查看是否生成仿真结果文件(.json)。
- 可视化界面呈现仿真结果:
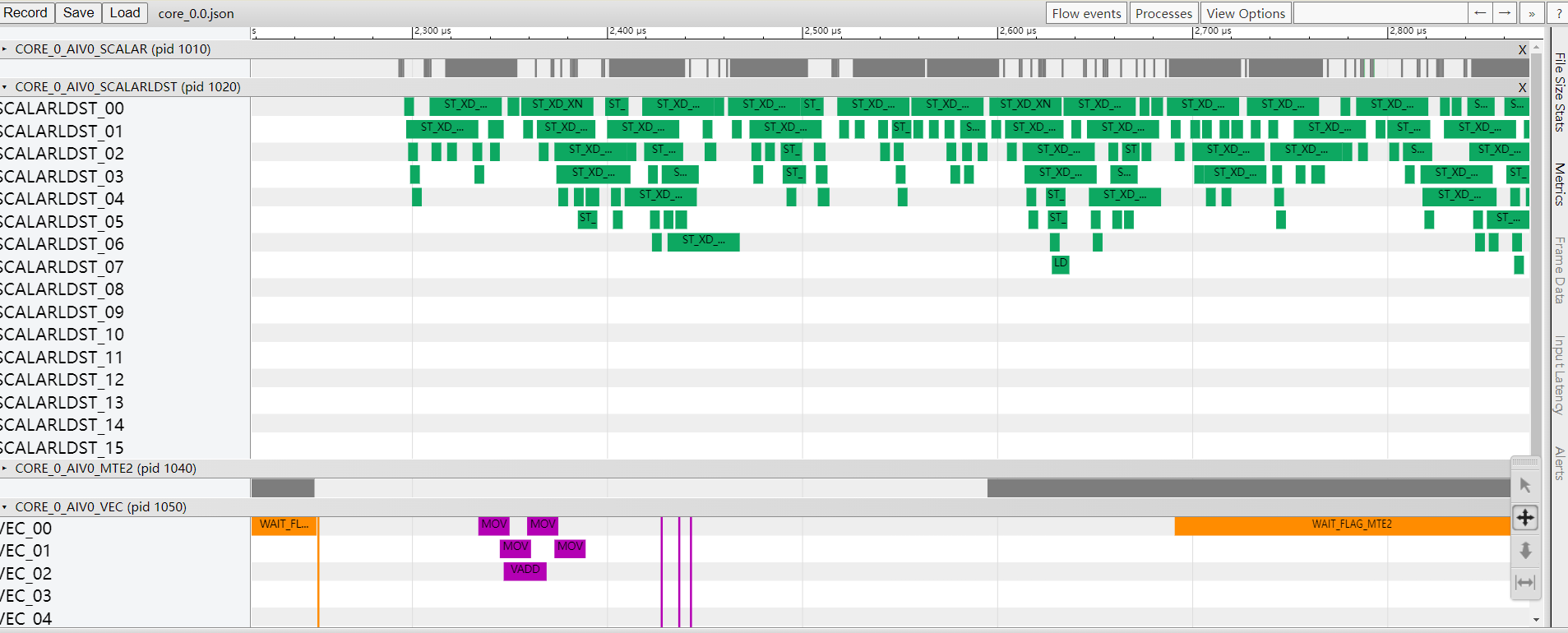
- 在Chrome浏览器中输入chrome://tracing,将生成的core_${core_id}.json文件拖到空白处打开,界面会呈现trace图。
通过键盘上的快捷键(w:放大,s:缩小,a:左移,d:右移)查看,如图1所示。
表2 常用流水图字段说明 字段名
字段含义
SCALAR
标量运算单元。
VECTOR
向量运算单元。
CUBE
矩阵乘运算单元。
MTE1
数据搬运流水,数据搬运方向为:L1 ->{L0A/L0B, UBUF}。
MTE2
数据搬运流水,数据搬运方向为:{GM, L2} ->{L1, L0A/B, UBUF}。
MTE3
数据搬运流水,数据搬运方向为:UBUF -> {GM, L2, L1}。
FIXP
数据搬运流水,数据搬运方向为:FIXPIPE L0C -> OUT/L1。(仅Atlas A2训练系列产品/Atlas 800I A2推理产品支持展示)
FLOWCTRL
控制流指令。
ICmiss
未命中icache。
- 单击各个timeline,可查看各算子指令的详细信息,包含耗时以及对应代码行等信息。
图2 指令详细信息
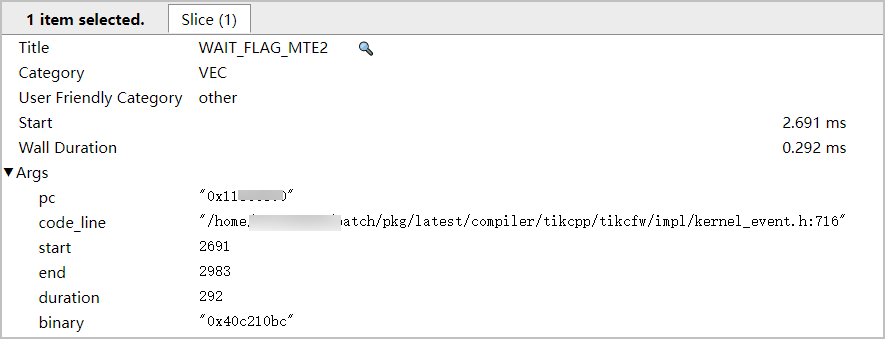
- 在Chrome浏览器中输入chrome://tracing,将生成的core_${core_id}.json文件拖到空白处打开,界面会呈现trace图。