调用NN类算子接口示例代码
本节介绍了单算子API执行方式下算子调用和编译运行样例。
基本原理
NN(Neural Network)类算子主要实现数学基础运算(如加、减、乘、除等)以及CNN相关的操作(如卷积、池化、激活函数)等,详细的算子API介绍参见单算子API执行,接口调用流程参见单算子API执行接口调用流程。
单算子API执行的算子接口一般定义为“两段式接口”,其中NN类算子接口示例如下:
aclnnStatus aclnnXxxGetWorkspaceSize(const aclTensor *src, ..., aclTensor *out, ..., uint64_t *workspaceSize, aclOpExecutor **executor); aclnnStatus aclnnXxx(void *workspace, uint64_t workspaceSize, aclOpExecutor *executor, aclrtStream stream);
其中aclnnXxxGetWorkspaceSize为第一段接口,主要用于计算本次NN类算子API调用计算过程中需要多少的workspace内存。获取到本次计算需要的workspace大小后,按照workspaceSize大小申请Device侧内存,然后调用第二段接口aclnnXxx执行计算。
示例代码
这里以Add算子调用过程为例,介绍算子调用的基本逻辑,其他算子的调用过程类似,请根据实际情况自行修改代码。
已知Add算子实现了张量加法运算,计算公式为:y=x1+αxx2。您可以获取如下示例代码,并将文件命名为“test_add.cpp”,代码如下:
#include <iostream>
#include <vector>
#include "acl/acl.h"
#include "aclnnop/aclnn_add.h"
#define CHECK_RET(cond, return_expr) \
do { \
if (!(cond)) { \
return_expr; \
} \
} while (0)
#define LOG_PRINT(message, ...) \
do { \
printf(message, ##__VA_ARGS__); \
} while (0)
int64_t GetShapeSize(const std::vector<int64_t>& shape) {
int64_t shape_size = 1;
for (auto i : shape) {
shape_size *= i;
}
return shape_size;
}
int Init(int32_t deviceId, aclrtStream* stream) {
// 固定写法,AscendCL初始化
auto ret = aclInit(nullptr);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclInit failed. ERROR: %d\n", ret); return ret);
ret = aclrtSetDevice(deviceId);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtSetDevice failed. ERROR: %d\n", ret); return ret);
ret = aclrtCreateStream(stream);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtCreateStream failed. ERROR: %d\n", ret); return ret);
return 0;
}
template <typename T>
int CreateAclTensor(const std::vector<T>& hostData, const std::vector<int64_t>& shape, void** deviceAddr,
aclDataType dataType, aclTensor** tensor) {
auto size = GetShapeSize(shape) * sizeof(T);
// 调用aclrtMalloc申请device侧内存
auto ret = aclrtMalloc(deviceAddr, size, ACL_MEM_MALLOC_HUGE_FIRST);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtMalloc failed. ERROR: %d\n", ret); return ret);
// 调用aclrtMemcpy将host侧数据拷贝到device侧内存上
ret = aclrtMemcpy(*deviceAddr, size, hostData.data(), size, ACL_MEMCPY_HOST_TO_DEVICE);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtMemcpy failed. ERROR: %d\n", ret); return ret);
// 计算连续tensor的strides
std::vector<int64_t> strides(shape.size(), 1);
for (int64_t i = shape.size() - 2; i >= 0; i--) {
strides[i] = shape[i + 1] * strides[i + 1];
}
// 调用aclCreateTensor接口创建aclTensor
*tensor = aclCreateTensor(shape.data(), shape.size(), dataType, strides.data(), 0, aclFormat::ACL_FORMAT_ND,
shape.data(), shape.size(), *deviceAddr);
return 0;
}
int main() {
// 1. (固定写法)device/stream初始化, 参考AscendCL对外接口列表
// 根据自己的实际device填写deviceId
int32_t deviceId = 0;
aclrtStream stream;
auto ret = Init(deviceId, &stream);
// check根据自己的需要处理
CHECK_RET(ret == 0, LOG_PRINT("Init acl failed. ERROR: %d\n", ret); return ret);
// 2. 构造输入与输出,需要根据API的接口自定义构造
std::vector<int64_t> selfShape = {4, 2};
std::vector<int64_t> otherShape = {4, 2};
std::vector<int64_t> outShape = {4, 2};
void* selfDeviceAddr = nullptr;
void* otherDeviceAddr = nullptr;
void* outDeviceAddr = nullptr;
aclTensor* self = nullptr;
aclTensor* other = nullptr;
aclScalar* alpha = nullptr;
aclTensor* out = nullptr;
std::vector<float> selfHostData = {0, 1, 2, 3, 4, 5, 6, 7};
std::vector<float> otherHostData = {1, 1, 1, 2, 2, 2, 3, 3};
std::vector<float> outHostData = {0, 0, 0, 0, 0, 0, 0, 0};
float alphaValue = 1.2f;
// 创建self aclTensor
ret = CreateAclTensor(selfHostData, selfShape, &selfDeviceAddr, aclDataType::ACL_FLOAT, &self);
CHECK_RET(ret == ACL_SUCCESS, return ret);
// 创建other aclTensor
ret = CreateAclTensor(otherHostData, otherShape, &otherDeviceAddr, aclDataType::ACL_FLOAT, &other);
CHECK_RET(ret == ACL_SUCCESS, return ret);
// 创建alpha aclScalar
alpha = aclCreateScalar(&alphaValue, aclDataType::ACL_FLOAT);
CHECK_RET(alpha != nullptr, return ret);
// 创建out aclTensor
ret = CreateAclTensor(outHostData, outShape, &outDeviceAddr, aclDataType::ACL_FLOAT, &out);
CHECK_RET(ret == ACL_SUCCESS, return ret);
// 3. 调用CANN算子库API,需要修改为具体的算子接口
uint64_t workspaceSize = 0;
aclOpExecutor* executor;
// 调用aclnnAdd第一段接口
ret = aclnnAddGetWorkspaceSize(self, other, alpha, out, &workspaceSize, &executor);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclnnAddGetWorkspaceSize failed. ERROR: %d\n", ret); return ret);
// 根据第一段接口计算出的workspaceSize申请device内存
void* workspaceAddr = nullptr;
if (workspaceSize > 0) {
ret = aclrtMalloc(&workspaceAddr, workspaceSize, ACL_MEM_MALLOC_HUGE_FIRST);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("allocate workspace failed. ERROR: %d\n", ret); return ret;);
}
// 调用aclnnAdd第二段接口
ret = aclnnAdd(workspaceAddr, workspaceSize, executor, stream);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclnnAdd failed. ERROR: %d\n", ret); return ret);
// 4.( 固定写法)同步等待任务执行结束
ret = aclrtSynchronizeStream(stream);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtSynchronizeStream failed. ERROR: %d\n", ret); return ret);
// 5. 获取输出的值,将device侧内存上的结果拷贝至host侧,需要根据具体API的接口定义修改
auto size = GetShapeSize(outShape);
std::vector<float> resultData(size, 0);
ret = aclrtMemcpy(resultData.data(), resultData.size() * sizeof(resultData[0]), outDeviceAddr, size * sizeof(float),
ACL_MEMCPY_DEVICE_TO_HOST);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("copy result from device to host failed. ERROR: %d\n", ret); return ret);
for (int64_t i = 0; i < size; i++) {
LOG_PRINT("result[%ld] is: %f\n", i, resultData[i]);
}
// 6. 释放aclTensor和aclScalar,需要根据具体API的接口定义修改
aclDestroyTensor(self);
aclDestroyTensor(other);
aclDestroyScalar(alpha);
aclDestroyTensor(out);
// 7. 释放device资源,需要根据具体API的接口定义修改
aclrtFree(selfDeviceAddr);
aclrtFree(otherDeviceAddr);
aclrtFree(outDeviceAddr);
if (workspaceSize > 0) {
aclrtFree(workspaceAddr);
}
aclrtDestroyStream(stream);
aclrtResetDevice(deviceId);
aclFinalize();
return 0;
}
CMakeLists文件(动态库)
这里以Add算子动态编译为例,其他算子的CMakeLists动态编译脚本类似,请根据实际情况自行修改脚本。
# CMake lowest version requirement
cmake_minimum_required(VERSION 3.14)
# 设置工程名
project(ACLNN_EXAMPLE)
# Compile options
add_compile_options(-std=c++11)
# 设置编译选项
set(CMAKE_RUNTIME_OUTPUT_DIRECTORY "./bin")
set(CMAKE_CXX_FLAGS_DEBUG "-fPIC -O0 -g -Wall")
set(CMAKE_CXX_FLAGS_RELEASE "-fPIC -O2 -Wall")
# 设置可执行文件名(如opapi_test),并指定待运行算子文件*.cpp所在目录
add_executable(opapi_test
test_add.cpp)
# 设置ASCEND_PATH(CANN软件包目录,请根据实际路径修改)和INCLUDE_BASE_DIR(头文件目录)
if(NOT "$ENV{ASCEND_CUSTOM_PATH}" STREQUAL "")
set(ASCEND_PATH $ENV{ASCEND_CUSTOM_PATH})
else()
set(ASCEND_PATH "/usr/local/Ascend/ascend-toolkit/latest")
endif()
set(INCLUDE_BASE_DIR "${ASCEND_PATH}/include")
include_directories(
${INCLUDE_BASE_DIR}
${INCLUDE_BASE_DIR}/aclnn
)
# 设置链接的动态库文件路径
target_link_libraries(opapi_test PRIVATE
${ASCEND_PATH}/lib64/libascendcl.so
${ASCEND_PATH}/lib64/libnnopbase.so
${ASCEND_PATH}/lib64/libopapi.so)
# 可执行文件在CMakeLists文件所在目录的bin目录下
install(TARGETS opapi_test DESTINATION ${CMAKE_RUNTIME_OUTPUT_DIRECTORY})
CMakeLists文件(静态库)
这里以Add算子动态编译为例,其他算子的CMakeLists静态编译脚本类似,请根据实际情况自行修改脚本。
# Copyright (c) Huawei Technologies Co., Ltd. 2019. All rights reserved.
# CMake lowest version requirement
cmake_minimum_required(VERSION 3.14)
# 设置工程名
project(ACLNN_EXAMPLE)
# Compile options
add_compile_options(-std=c++11)
# 设置编译选项
set(CMAKE_RUNTIME_OUTPUT_DIRECTORY "./bin")
set(CMAKE_CXX_FLAGS_DEBUG "-fPIC -O0 -g -Wall")
set(CMAKE_CXX_FLAGS_RELEASE "-fPIC -O2 -Wall")
# 设置可执行文件名(如opapi_test),并指定待运行算子文件*.cpp所在目录
add_executable(opapi_test
test_add.cpp)
# 设置ASCEND_PATH(CANN软件包目录,请根据实际路径修改)和INCLUDE_BASE_DIR(头文件目录)
if(NOT "$ENV{ASCEND_CUSTOM_PATH}" STREQUAL "")
set(ASCEND_PATH $ENV{ASCEND_CUSTOM_PATH})
else()
set(ASCEND_PATH "/usr/local/Ascend/ascend-toolkit/latest")
endif()
set(INCLUDE_BASE_DIR "${ASCEND_PATH}/include")
include_directories(
${INCLUDE_BASE_DIR}
${INCLUDE_BASE_DIR}/aclnn
)
# 设置链接的静态库文件路径
# 注意1:opmaster_static.a和aclnn_math_static.a必选,其余.a文件按需设置,支持设置1个或多个。
# 注意2:so文件是静态库.a文件依赖的动态库文件,必须设置。
target_link_directories(opapi_test PRIVATE ${ASCEND_PATH}/lib64/)
target_link_libraries(opapi_test PRIVATE
aclnn_rand_static aclnn_math_static aclnn_ops_infer_static aclnn_ops_train_static
opmaster_static
c_sec platform error_manager ascendalog profapi ascendcl ge_common_base graph_base
exe_graph graph register ascend_dump nnopbase)
# 可执行文件在CMakeLists文件所在目录的bin目录下
install(TARGETS opapi_test DESTINATION ${CMAKE_RUNTIME_OUTPUT_DIRECTORY})
编译与运行

- 根据前文提供的示例代码、CMakeLists文件(动态库)或CMakeLists文件(静态库),提前准备好算子的调用代码(*.cpp)和编译脚本(CMakeLists.txt)。
- 配置环境变量。
安装CANN软件后,使用CANN运行用户(如HwHiAiUser)登录环境,执行如下命令设置环境变量。其中${install_path}为CANN软件安装后文件存储路径,请根据实际情况替换该路径。
source ${install_path}/set_env.sh - 编译并运行。
- 进入CMakeLists.txt所在目录,执行如下命令,新建build目录存放生成的编译文件。
mkdir -p build
- 进入build所在目录,执行cmake命令编译,再执行make命令生成可执行文件。
cmake ./ -DCMAKE_CXX_COMPILER=g++ -DCMAKE_SKIP_RPATH=TRUE make
编译成功后,会在当前目录的bin目录下生成opapi_test可执行文件。
- 进入bin目录,运行可执行文件opapi_test。
./opapi_test
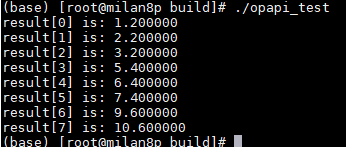
以Add算子的运行结果为例,运行后的结果如下:
- 进入CMakeLists.txt所在目录,执行如下命令,新建build目录存放生成的编译文件。
父主题: 单算子API执行