'%20fill='%23C31D20'%20fill-rule='nonzero'%3e%3cpath%20d='M7.55269822,13.7609409%20C10.8552199,9.97176134%2014.2271223,7.63452926%2017.1034483,6.5677512%20L17.0816429,0.884990191%20C17.0593112,0.508963963%2016.8188535,0.182653682%2016.4703158,0.055395956%20C16.1217781,-0.0718617705%2015.7322263,0.0244201241%2015.4799397,0.300178022%20L12.9584465,3.07097775%20L0.368821458,17.4916392%20C0.0232151224,17.8857306%20-0.0894678188,18.437454%200.0732192079,18.9389805%20C0.235906234,19.4405071%200.649247199,19.815643%201.15754056,19.9230783%20C1.66583392,20.0305135%202.19185783,19.853926%202.53746417,19.4598346%20L7.5467513,13.7690073%20L7.55269822,13.7609409%20Z'%20id='路径'%3e%3c/path%3e%3cpath%20d='M10.6896552,12.0927463%20L15.1004089,17.5535201%20C15.4511303,17.8402432%2015.9409156,17.8973222%2016.3502521,17.6991755%20C16.7595885,17.5010287%2017.0117165,17.0848129%2016.993637,16.6370685%20L17.1034483,10.0202479%20C14.5615201,9.75868982%2012.477139,10.7130773%2010.6896552,12.0927463%20Z'%20id='路径'%3e%3c/path%3e%3c/g%3e%3crect%20id='矩形'%20x='0'%20y='0'%20width='24'%20height='24'%3e%3c/rect%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
SPMD模型
Ascend C算子编程是SPMD(Single-Program Multiple-Data)编程,SPMD是一种常用的并行计算的方法,是提高计算速度的有效手段。
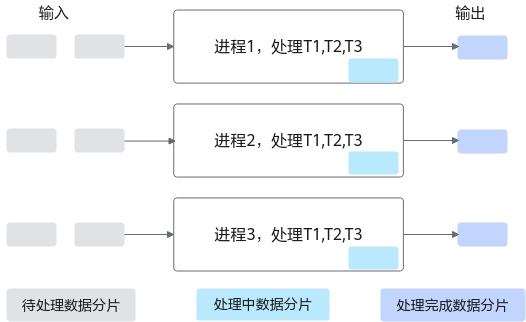
假设,从输入数据到输出数据需要经过3个阶段任务的处理(T1、T2、T3)。如下图所示,SPMD模式下,系统会启动一组进程,并行处理待处理的数据:首先待处理数据会被切分成多个数据分片,切分后的数据分片随后被分发给不同进程处理,每个进程接收到一个或多个数据分片,并独立地对这些分片进行3个任务的处理。
图1 SPMD数据并行示意图
具体到Ascend C编程模型中的应用,是将需要处理的数据被拆分并同时在多个计算核心(类比于上文介绍中的多个进程)上运行,从而获取更高的性能。多个AI Core共享相同的指令代码,每个核上的运行实例唯一的区别是block_idx不同,每个核通过不同的block_idx来识别自己的身份。block的概念类似于上文中进程的概念,block_idx就是标识进程唯一性的进程ID。并行计算过程如下图所示。
图2 SPMD并行计算示意图

下面的代码片段取自于Ascend C Add算子的实现代码,算子被调用时,所有的计算核心都执行相同的实现代码,入口函数的入参也是相同的。每个核上处理的数据地址需要在起始地址上增加GetBlockIdx()*BLOCK_LENGTH(每个block处理的数据长度)的偏移来获取。这样也就实现了多核并行计算的数据切分。
class KernelAdd {
public:
__aicore__ inline KernelAdd() {}
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z)
{
// get start index for current core, core parallel
xGm.SetGlobalBuffer((__gm__ half*)x + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH);
yGm.SetGlobalBuffer((__gm__ half*)y + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH);
zGm.SetGlobalBuffer((__gm__ half*)z + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH);
// pipe alloc memory to queue, the unit is Bytes
pipe.InitBuffer(inQueueX, BUFFER_NUM, TILE_LENGTH * sizeof(half));
pipe.InitBuffer(inQueueY, BUFFER_NUM, TILE_LENGTH * sizeof(half));
pipe.InitBuffer(outQueueZ, BUFFER_NUM, TILE_LENGTH * sizeof(half));
}
...
}
// 实现核函数
extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z)
{
// 初始化算子类,算子类提供算子初始化和核心处理等方法
KernelAdd op;
// 初始化函数,获取该核函数需要处理的输入输出地址,同时完成必要的内存初始化工作
op.Init(x, y, z);
// 核心处理函数,完成算子的数据搬运与计算等核心逻辑
op.Process();
}
父主题: 编程模型
