Matmul模板参数
功能说明
创建Matmul对象时需要传入:
- A、B、C、Bias的参数类型信息, 类型信息通过MatmulType来定义,包括:内存逻辑位置、数据格式、数据类型、是否转置、数据排布和是否使能L1复用。
- MatmulConfig信息(可选),用于配置Matmul模板信息以及相关的配置参数。不配置默认使能Norm模板。
- MatmulCallBack回调函数信息(可选),用于配置左右矩阵从GM拷贝到L1、计算结果从CO1拷贝到GM的自定义函数。当前支持如下产品型号:
- MatmulPolicy信息(可选),预留参数。
针对Atlas 200/500 A2推理产品,当前只支持使能默认的Norm模板。
实现原理
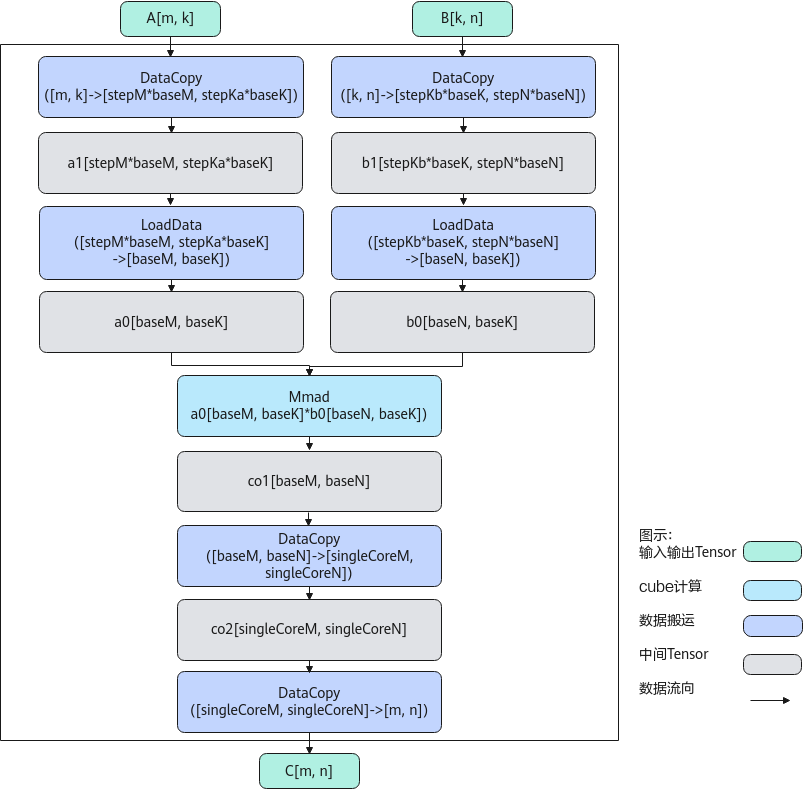
计算过程分为如下几步:
- 数据从GM搬到A1:DataCopy每次从矩阵A,搬出一个stepM*baseM*stepKa*baseK的矩阵块a1,循环多次完成矩阵A的搬运;数据从GM搬到B1:DataCopy每次从矩阵B,搬出一个stepKb*baseK*stepN*baseN的矩阵块b1,循环多次完成矩阵B的搬运;
- 数据从A1搬到A2:LoadData每次从矩阵块a1,搬出一个baseM * baseK的矩阵块a0;数据从B1搬到B2,并完成转置:LoadData每次从矩阵块b1,搬出一个baseK * baseN的矩阵块,并将其转置为baseN * baseK的矩阵块b0;
- 矩阵乘:每次完成一个矩阵块a0 * b0的计算,得到baseM * baseN的矩阵块co1;
- 数据从矩阵块co1搬到矩阵块co2: DataCopy每次搬运一块baseM * baseN的矩阵块co1到singleCoreM * singleCoreN的矩阵块co2中;
- 重复2-4步骤,完成矩阵块a1 * b1的计算;
- 数据从矩阵块co2搬到矩阵块C:DataCopy每次搬运一块singleCoreM * singleCoreN的矩阵块co2到矩阵块C中;
- 重复1-6步骤,完成矩阵A * B = C的计算。
函数原型
1 2 |
template <class A_TYPE, class B_TYPE, class C_TYPE, class BIAS_TYPE = C_TYPE, const MatmulConfig& MM_CFG = CFG_NORM, class MM_CB = MatmulCallBackFunc<nullptr, nullptr, nullptr>, MATMUL_POLICY_DEFAULT_OF(MatmulPolicy)> using Matmul = matmul::MatmulImpl<A_TYPE, B_TYPE, C_TYPE, BIAS_TYPE, MM_CFG, MM_CB, MATMUL_POLICY>; |
其中A_TYPE、B_TYPE、C_TYPE类型信息通过MatmulType来定义;
MatmulConfig参数说明见表2,MM_CFG可选取提供的模板默认值之一,也可以通过如下获取模板的接口,自定义模板参数配置。提供的MatmulConfig模板取值范围为【CFG_NORM、CFG_MDL、CFG_IBSHARE_NORM、MM_CFG_BB】,分别对应默认的Norm、MDL、IBShare、BasicBlock模板,即通过以下对应接口的默认参数得到的模板,各模板介绍请参考表3。
- 获取Norm模板的接口
1__aicore__ constexpr MatmulConfig GetNormalConfig(const bool intrinsicsLimit = false, const bool batchLoop = false, const bool isVecND2NZ = false, const BatchMode bmmMode = BatchMode::BATCH_LESS_THAN_L1, const bool isMsgReuse = true, const IterateOrder iterateOrder = IterateOrder::UNDEF, const ScheduleType scheduleType = ScheduleType::INNER_PRODUCT, const bool enUnitFlag = true)
- 获取MDL模板的接口
1__aicore__ constexpr MatmulConfig GetMDLConfig(const bool intrinsicsLimit = false, const bool batchLoop = false, const uint32_t doMTE2Preload = 0, const bool isVecND2NZ = false, bool isPerTensor = false, bool hasAntiQuantOffset = false, const bool enUnitFlag = false, const bool isMsgReuse = true, const bool enableUBReuse = true, const bool enableL1CacheUB = false, const IterateOrder iterateOrder = IterateOrder::UNDEF, const ScheduleType scheduleType = ScheduleType::INNER_PRODUCT)
- 获取SpecialMDL的接口
1__aicore__ constexpr MatmulConfig GetSpecialMDLConfig(const bool intrinsicsLimit = false, const bool batchLoop = false, const uint32_t doMTE2Preload = 0, const bool isVecND2NZ = false, bool isPerTensor = false, bool hasAntiQuantOffset = false)
- 获取IBShare模板的接口
1__aicore__ constexpr MatmulConfig GetIBShareNormConfig(const bool intrinsicsLimit = false, const bool batchLoop = false, const bool isVecND2NZ = false, const BatchMode bmmMode = BatchMode::BATCH_LESS_THAN_L1, const bool isDoubleCache = false, const bool enUnitFlag = true)
- 获取BasicBlock模板的接口
1__aicore__ constexpr MatmulConfig GetBasicConfig(const uint32_t basicM, const uint32_t basicN, const uint32_t basicK, const bool intrinsicsLimit = false, const bool batchLoop = false, const BatchMode bmmMode = BatchMode::BATCH_LESS_THAN_L1)
- 获取SpecialBasicBlock模板的接口(预留接口)
1__aicore__ constexpr MatmulConfig GetSpecialBasicConfig(const uint32_t basicM, const uint32_t basicN, const uint32_t basicK, const uint32_t singleCoreM, const uint32_t singleCoreN, const uint32_t singleCoreK, const uint32_t stepM, const uint32_t stepN, const bool intrinsicsLimit = false, const bool batchLoop = false, const BatchMode bmmMode = BatchMode::BATCH_LESS_THAN_L1)
MM_CB用于支持不同的搬入搬出需求,实现定制化的搬入搬出功能,如非连续搬入或针对搬出设置不同的数据片段间隔等。MM_CB中3个函数指针分别对应计算结果从CO1拷贝到GM、左矩阵从GM拷贝到L1、右矩阵从GM拷贝到L1的回调函数指针,各个功能回调函数接口定义及参数释义见表9。
MATMUL_POLICY_DEFAULT_OF(MatmulPolicy),当前为预留参数,无须配置。
#define MATMUL_POLICY_DEFAULT_OF(DEFAULT) \ template <const auto& = MM_CFG, typename ...> class MATMUL_POLICY = DEFAULT
参数说明
|
参数 |
说明 |
|---|---|
|
POSITION |
内存逻辑位置 针对Atlas A2训练系列产品/Atlas 800I A2推理产品:
针对Atlas推理系列产品AI Core:
针对Atlas 200/500 A2推理产品:
|
|
CubeFormat |
针对Atlas A2训练系列产品/Atlas 800I A2推理产品:
针对Atlas推理系列产品AI Core:
|
|
TYPE |
针对Atlas A2训练系列产品/Atlas 800I A2推理产品:
针对Atlas推理系列产品AI Core:
针对Atlas 200/500 A2推理产品:
注意:A矩阵和B矩阵数据类型需要一致,具体数据类型组合关系请参考表2。 |
|
ISTRANS |
是否开启使能矩阵转置的功能。
默认为false不使能转置。 |
|
LAYOUT |
表征数据的排布 NONE:默认值,表示不使用BatchMatmul;其他选项表示使用BatchMatmul。 NORMAL:BMNK的数据排布格式。 BSNGD:原始BSH shape做reshape后的数据排布,具体可参考IterateBatch中对该数据排布的介绍。 SBNGD:原始SBH shape做reshape后的数据排布,具体可参考IterateBatch中对该数据排布的介绍。 BNGS1S2:一般为前两种数据排布进行矩阵乘的输出,S1S2数据连续存放,一个S1S2为一个batch的计算数据。 |
|
IBSHARE |
是否使能IBShare。IBShare的功能是能够复用L1上相同的A矩阵或B矩阵数据。当A矩阵和B矩阵同时使能IBShare时,表示L1上的A矩阵和B矩阵同时复用,此时只支持Norm模板。 除A、B矩阵同时复用的场景外,与Matmul模板参数中的IBShare模板配合使用,具体参数设置详见表2。 |
|
参数 |
说明 |
支持模板:Norm, MDL, SpecialMDL, IBShare, BasicBlock |
|---|---|---|
|
doNorm |
使能Norm模板。参数取值如下:
不指定模板的情况默认使能Norm模板。 |
Norm |
|
doMultiDataLoad |
使能MDL模板。参数取值如下:
|
MDL |
|
doSpecialMDL |
使能SpecialMDL模板。参数取值如下:
本质上也是MDL模板。MDL模板Matmul K方向不全载时(singleCoreK/baseK > stepKb),仅支持stepN设置为1,开启后支持stepN=2。 |
SpecialMDL |
|
doIBShareNorm |
使能IBShare模板。参数取值如下:
IBShare的功能是能够复用L1上相同的A矩阵或B矩阵数据,开启后在数据复用场景能够避免重复搬运数据到L1。 |
IBShare |
|
intrinsicsLimit |
当左矩阵或右矩阵在单核上内轴(即尾轴)大于等于65535时,是否使能循环执行数据的搬入。例如,左矩阵A[M, K],单核上的内轴数据singleCoreK大于65535,配置该参数为true后,API内部通过循环执行数据的搬入。参数取值如下:
|
所有模板 |
|
batchLoop |
是否多Batch输入多Batch输出。参数取值如下:
仅对BatchMatmul有效。 |
所有模板 |
|
isVecND2NZ |
使能通过vector进行ND2NZ。参数取值如下:
使能时需要设置SetLocalWorkspace。 针对Atlas推理系列产品AI Core,在UB空间足够的条件下(UB空间大于2*TCubeTiling的transLength参数),建议优先使能该参数,搬运性能更好。 |
所有模板 |
|
enableInit |
是否启用Init函数,不使能Init函数能够提升常量传播效果,优化性能。默认使能。 |
所有模板 |
|
bmmMode |
Layout类型为NORMAL时,设置BatchMatmul输入A/B矩阵的多batch数据总和与L1 Buffer的大小关系。参数取值如下:
|
Norm, IBShare |
|
enUnitFlag |
使能unitflag功能,使计算与搬运流水并行,提高性能。Norm, IBShare下默认使能,MDL下默认不使能。参数取值如下:
|
MDL, Norm, IBShare |
|
isPerTensor |
A矩阵half类型输入且B矩阵int8类型输入场景,使能B矩阵量化时是否为per tensor,true为per tensor,false为per channel。 |
MDL, SpecialMDL |
|
hasAntiQuantOffset |
A矩阵half类型输入且B矩阵int8类型输入场景,使能B矩阵量化时是否使用offset系数。 |
MDL, SpecialMDL |
|
doMTE2Preload |
在MTE2流水间隙较大,且M/N数值较大时可通过该参数开启对应M/N方向的预加载功能,开启后能减小MTE2间隙,提升性能。预加载功能仅在MDL模板有效。参数取值如下:
注意,开启M/N预加载功能时需保证K全载,且M/N开启Double Buffer。 |
MDL, SpecialMDL |
|
enableReuse |
SetSelfDefineData函数设置的回调函数中的dataPtr是否直接传递计算数据。参数取值如下:
|
Norm, MDL |
|
enableUBReuse |
是否使能UB复用。参数取值如下:
Atlas A2训练系列产品/Atlas 800I A2推理产品不支持该参数。 Atlas推理系列产品AI Core支持该参数。 Atlas 200/500 A2推理产品不支持该参数。 |
MDL |
|
enableL1CacheUB |
是否使能L1缓存UB计算块。参数取值如下:
若要使能L1缓存UB计算块,必须在tiling实现中调用SetMatmulConfigParams接口配置相关信息。 Atlas A2训练系列产品/Atlas 800I A2推理产品不支持该参数。 Atlas推理系列产品AI Core支持该参数。 Atlas 200/500 A2推理产品不支持该参数。 |
MDL |
|
enableDoubleCache |
开启IBShare模板后,在L1上是否同时缓存两块数据。注意,需要控制base块大小,防止两块缓存超过L1大小限制。参数取值如下:
|
IBShare |
|
IterateOrder |
Matmul做矩阵运算的循环迭代顺序,与表1中的iterateOrder参数含义相同。当ScheduleType参数取值为ScheduleType::OUTER_PRODUCT或1时,本参数生效。参数取值如下: enum class IterateOrder {
ORDER_M = 0, // 先往M轴方向偏移再往N轴方向偏移
ORDER_N, // 先往N轴方向偏移再往M轴方向偏移
UNDEF, // 当前无效
};
注:MDL模板使用时,若IterateOrder取值ORDER_M,TCubeTiling结构中的stepN需要大于1,IterateOrder取值ORDER_N时,TCubeTiling结构中的stepM需要大于1。 Atlas A2训练系列产品/Atlas 800I A2推理产品支持该参数。 Atlas推理系列产品AI Core不支持该参数。 Atlas 200/500 A2推理产品不支持该参数。 |
Norm、MDL |
|
ScheduleType |
配置Matmul数据搬运模式。参数取值如下:
注:
Atlas A2训练系列产品/Atlas 800I A2推理产品支持该参数。 Atlas推理系列产品AI Core不支持该参数。 Atlas 200/500 A2推理产品不支持该参数。 |
Norm、MDL |
|
isBiasBatch |
批量多Batch的Matmul场景,即BatchMatmul场景,Bias的大小是否带有Batch轴。参数取值如下: |
Norm |
|
doBasicBlock |
是否使能BasicBlock模板。模板参数取值如下:
调用GetBasicConfig接口获取BasicBlock模板时,该参数被置为true。注意:
Atlas A2训练系列产品/Atlas 800I A2推理产品支持该参数。 Atlas推理系列产品AI Core不支持设置为true。 Atlas 200/500 A2推理产品不支持设置为true。 |
BasicBlock |
|
basicM |
相当于baseM |
BasicBlock |
|
basicN |
相当于baseN |
BasicBlock |
|
basicK |
相当于baseK |
BasicBlock |
|
doSpecialBasicBlock |
使能SpecialBasicBlock模板。参数取值如下:
本质上也是BasicBlock模板,但消除了头开销scalar计算。 |
预留参数 |
|
singleCoreM |
单核内M轴shape大小,以元素为单位。 |
预留参数 |
|
singleCoreN |
单核内N轴shape大小,以元素为单位。 |
预留参数 |
|
singleCoreK |
单核内K轴shape大小,以元素为单位。 |
预留参数 |
|
stepM |
左矩阵在A1中缓存的bufferM方向上baseM的倍数。 |
预留参数 |
|
stepN |
右矩阵在B1中缓存的bufferN方向上baseN的倍数。 |
预留参数 |
|
baseMN |
baseM*baseN的大小。 |
预留参数 |
|
singleCoreMN |
singleCoreM*singleCoreN的大小。 |
预留参数 |
|
模板 |
实现 |
优点 |
推荐使用场景 |
|---|---|---|---|
|
Norm |
支持L1缓存多个基本块,MTE2分多次从GM搬运基本块到L1,每次搬运一份基本块,已搬的基本块不清空。(举例说明:depthA1=6,代表搬入6份A矩阵基本块到L1,1次搬运一份基本块,MTE2进行6次搬运) |
可以提前启动MTE1流水(因为搬1份基本块就可以做MTE1后面的运算) |
默认使能Norm模板 |
|
MDL,SpecialMDL |
支持L1缓存多个基本块,MTE2从GM到L1的搬运为一次性"大包"搬运。(举例说明:depthA1=6,代表一次性搬入6份A矩阵基本块到L1,MTE2进行1次搬运) |
对于一般的大shape场景,可以减少MTE2的循环搬运,提升性能 |
大shape场景 |
|
IBShare |
MIX场景下,多个AIV的A矩阵或B矩阵GM地址相同的时候,通过共享L1 Buffer,减少MTE2搬运 |
减少MTE2搬运,提升性能 |
MIX场景多个AIV的A矩阵或B矩阵GM地址相同 |
|
BasicBlock |
在无尾块的场景,base块大小确定的情况下,通过GetBasicConfig接口配置输入的基本块大小,固定MTE1每次搬运的矩阵大小及MMAD每次计算的矩阵大小,减少参数计算量 |
减少MTE1矩阵搬运和MMAD矩阵计算过程中的参数计算开销 |
无尾块,base块(baseM,baseN)大小确定 |
|
参数 |
说明 |
|---|---|
|
CONFIG_NORM |
表示设置MatmulConfig默认值为Norm模板 |
|
CONFIG_MDL |
表示设置MatmulConfig默认值为MDL模板 |
|
CONFIG_SPECIALMDL |
表示设置MatmulConfig默认值为SpecialMDL模板 |
|
CONFIG_IBSHARE |
表示设置MatmulConfig默认值为IBShare模板 |
|
参数 |
数据类型 |
说明 |
|---|---|---|
|
singleCoreM |
uint32_t |
单核内M轴shape大小,以元素为单位 |
|
singleCoreN |
uint32_t |
单核内N轴shape大小,以元素为单位 |
|
singleCoreK |
uint32_t |
单核内K轴shape大小,以元素为单位 |
|
basicM |
uint32_t |
相当于baseM |
|
basicN |
uint32_t |
相当于baseN |
|
basicK |
uint32_t |
相当于baseK |
|
参数 |
数据类型 |
说明 |
|---|---|---|
|
isPerTensor |
bool |
A矩阵half类型输入且B矩阵int8类型输入场景,使能B矩阵量化时是否为per tensor,true为per tensor,false为per channel。 |
|
hasAntiQuantOffset |
bool |
A矩阵half类型输入且B矩阵int8类型输入场景,使能B矩阵量化时是否使用offset系数。 |
|
参数 |
数据类型 |
说明 |
|---|---|---|
|
batchLoop |
bool |
是否多Batch输入多Batch输出。参数取值如下:
仅对BatchMatmul有效。 |
|
bmmMode |
BatchMode |
Layout类型为NORMAL时,设置BatchMatmul输入A/B矩阵的多batch数据总和与L1 Buffer的大小关系。参数取值如下:
|
|
isBiasBatch |
bool |
批量多Batch的Matmul场景,即BatchMatmul场景,Bias的大小是否带有Batch轴。参数取值如下:
|
|
参数 |
数据类型 |
说明 |
|---|---|---|
|
intrinsicsLimit |
bool |
进行芯片指令搬运地址偏移量校验,影响性能。参数取值如下:
|
|
enVecND2NZ |
bool |
使能通过vector进行ND2NZ。参数取值如下:
使能时需要设置SetLocalWorkspace。 |
|
doMTE2Preload |
uint32_t |
在MTE2流水间隙较大,且M/N数值较大时可通过该参数开启对应M/N方向的预加载功能,开启后能减小MTE2间隙,提升性能。预加载功能仅在MDL模板有效。参数取值如下:
注意,开启M/N预加载功能时需保证K全载,且M/N开启Double Buffer。 |
|
enableReuse |
bool |
SetSelfDefineData函数设置的回调函数中的dataPtr是否直接传递计算数据。参数取值如下:
|
|
enableUBReuse |
bool |
是否使能UB复用。参数取值如下:
Atlas A2训练系列产品/Atlas 800I A2推理产品不支持该参数。 Atlas推理系列产品AI Core支持该参数。 Atlas 200/500 A2推理产品不支持该参数。 |
|
enableL1CacheUB |
bool |
是否使能L1缓存UB计算块。参数取值如下:
若要使能L1缓存UB计算块,必须在tiling实现中调用SetMatmulConfigParams接口配置相关信息。 Atlas A2训练系列产品/Atlas 800I A2推理产品不支持该参数。 Atlas推理系列产品AI Core支持该参数。 Atlas 200/500 A2推理产品不支持该参数。 |
|
iterateOrder |
IterateOrder |
Matmul做矩阵运算的循环迭代顺序,与表1中的iterateOrder参数含义相同。当ScheduleType参数取值为ScheduleType::OUTER_PRODUCT或1时,本参数生效。参数取值如下: enum class IterateOrder {
ORDER_M = 0, // 先往M轴方向偏移再往N轴方向偏移
ORDER_N, // 先往N轴方向偏移再往M轴方向偏移
UNDEF, // 当前无效
};
注:MDL模板使用时,若IterateOrder取值ORDER_M,TCubeTiling结构中的stepN需要大于1,IterateOrder取值ORDER_N时,TCubeTiling结构中的stepM需要大于1。 Atlas A2训练系列产品/Atlas 800I A2推理产品支持该参数。 Atlas推理系列产品AI Core不支持该参数。 Atlas 200/500 A2推理产品不支持该参数。 |
|
scheduleType |
ScheduleType |
配置Matmul数据搬运模式。参数取值如下:
注:
Atlas A2训练系列产品/Atlas 800I A2推理产品支持该参数。 Atlas推理系列产品AI Core不支持该参数。 Atlas 200/500 A2推理产品不支持该参数。 |
|
enableDoubleCache |
bool |
开启IBShare模板后,在L1上是否同时缓存两块数据。注意,需要控制base块大小,防止两块缓存超过L1大小限制。参数取值如下:
|
|
回调函数功能 |
回调函数接口 |
参数说明 |
|---|---|---|
|
可自定义设置不同的搬出数据片段数目等参数,实现将Matmul计算结果从CO1搬出到GM的功能 |
void DataCopyOut(const __gm__ void *gm, const LocalTensor<int8_t> &co1Local, const void *dataCopyOutParams, const uint64_t tilingPtr, const uint64_t dataPtr) |
gm:输出的GM地址 co1Local: CO1上的计算结果 dataCopyOutParams: Matmul定义的 DataCopyOutParams结构体指针,供用户参考使用 struct DataCopyOutParams { uint16_t cBurstNum; //传输数据片段数目 uint16_t burstLen; //连续传输数据片段长度 uint16_t srcStride;//源tensor相邻连续数据片段间隔 uint32_t dstStride; // 目的tensor相邻连续数据片段间隔 uint16_t oriNSize; // NZ转ND时,源tensorN方向大小 bool enUnitFlag; // 是否使能UnitFlag uint64_t quantScalar; // 量化场景下量化Scalar的值 uint64_t cbufWorkspaceAddr; //量化场景下量化Tensor地址 } tilingPtr: 用户使用SetUserDefInfo设置的tiling参数地址 dataPtr: 用户使用SetSelfDefineData设置的计算数据地址 |
|
可自定义左矩阵搬入首地址、搬运块位置、搬运块大小,实现左矩阵从GM搬入L1的功能 |
void CopyA1(const LocalTensor<int8_t> &aMatrix, const __gm__ void *gm, int row, int col, int useM, int useK, const uint64_t tilingPtr, const uint64_t dataPtr) |
aMatrix: 目标L1Buffer地址 gm:左矩阵GM首地址 row、col:搬运块左上角坐标在左矩阵中的位置 useM、useK:搬运块M、K方向大小 tilingPtr: 用户使用SetUserDefInfo设置的tiling参数地址 dataPtr: 用户使用SetSelfDefineData设置的计算数据地址 |
|
可自定义右矩阵搬入首地址、搬运块位置、搬运块大小,实现右矩阵从GM搬入L1的功能 |
void CopyB1(const LocalTensor<int8_t> &bMatrix, const __gm__ void *gm, int row, int col, int useK, int useN, const uint64_t tilingPtr, const uint64_t dataPtr) |
bMatrix: 目标L1Buffer地址 gm:右矩阵GM首地址 row、col:搬运块左上角坐标在右矩阵中的位置 useK、useN:搬运块K、N方向大小 tilingPtr: 用户使用SetUserDefInfo设置的tiling参数地址 dataPtr: 用户使用SetSelfDefineData设置的计算数据地址 |
返回值
无
支持的型号
Atlas A2训练系列产品/Atlas 800I A2推理产品
Atlas推理系列产品AI Core
Atlas 200/500 A2推理产品
注意事项
无
调用示例
//用户自定义回调函数
void DataCopyOut(const __gm__ void *gm, const LocalTensor<int8_t> &co1Local, const void *dataCopyOutParams, const uint64_t tilingPtr, const uint64_t dataPtr);
void CopyA1(const AscendC::LocalTensor<int8_t> &aMatrix, const __gm__ void *gm, int row, int col, int useM, int useK, const uint64_t tilingPtr, const uint64_t dataPtr);
void CopyB1(const AscendC::LocalTensor<int8_t> &bMatrix, const __gm__ void *gm, int row, int col, int useK, int useN, const uint64_t tilingPtr, const uint64_t dataPtr);
typedef matmul::MatmulType<AscendC::TPosition::GM, CubeFormat::ND, half> aType;
typedef matmul::MatmulType<AscendC::TPosition::GM, CubeFormat::ND, half> bType;
typedef matmul::MatmulType<AscendC::TPosition::GM, CubeFormat::ND, float> cType;
typedef matmul::MatmulType<AscendC::TPosition::GM, CubeFormat::ND, float> biasType;
matmul::Matmul<aType, bType, cType, biasType, CFG_MDL> mm1;
matmul::MatmulConfig mmConfig{false, true, false, 128, 128, 64};
mmConfig.enUnitFlag = false;
matmul::Matmul<aType, bType, cType, biasType, mmConfig> mm2;
matmul::Matmul<aType, bType, cType, biasType, CFG_NORM, matmul::MatmulCallBackFunc<DataCopyOut, CopyA1, CopyB1>> mm3;