TIK矢量计算
接口原型
TIK提供了大量计算类API以调用Vector计算资源展开计算,用户需要关注API参数的合理设置以及背后的原理。考虑到API参数的共通性,以下仅以矢量单目运算API为例进行阐述。矢量单目运算的函数原型如下所示:
instruction(mask, dst, src, repeat_times, dst_rep_stride, src_rep_stride)
- 参数mask表示Vector的每个计算单元是否参与运算。若数据充分,Vector一次最多可计算8个block(256Byte),此时mask值取得对应数据类型的最大值;若数据不足,只能让部分Vector计算单元参与运算时,则根据实际数据量对mask进行取值。值得注意的是,TIK提供了连续模式和逐bit两种模式对mask进行赋值。其中,连续模式使用简单,而逐bit模式更灵活且复杂,用户可根据使用习惯和实际场景选择使用。
- 参数dst、src分别表示目的操作数和源操作数,也是Vector读取的数据起始地址。
- 参数repeat_times、dst_rep_stride、src_rep_stride是计算类API中需要着重注意的参数。在当前版本的TIK API中,Vector每次读取连续的256 Bytes数据进行计算;为完成对输入数据的处理,Vector必须通过多次迭代(repeat)才能完成所有数据的读取与计算。
- 参数repeat_times表示单次API调用中执行的迭代次数。考虑到每次API启动都有固定时延,将多次迭代放入单次API调用中,可大幅减少不必要的启动开销,从而提升整体执行效率。顾及昇腾AI处理器本身的硬件限制,repeat_times取值上限为255。
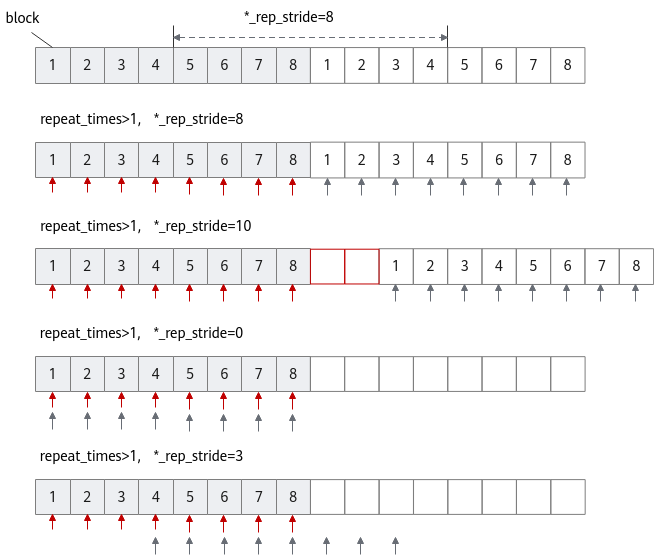
- 参数dst_rep_stride、src_rep_stride分别表示目的操作数和源操作数在相邻迭代间相同block间的地址步长,如图1所示;为方便起见,这类参数以下记为*_rep_stride。
假设定义一个Tensor供目的操作数和源操作数同时使用(即地址重叠),*_rep_stride取值为8。此时,Vector第一轮迭代读取连续8个block,第二轮迭代紧接着读取下一个连续的8个block,则Vector通过多轮迭代即可完成所有输入数据的计算。详细介绍请参见连续地址计算。
需要注意的是,*_rep_stride有一些特殊的取值,在一些特殊场景可能有用:
- 当repeat_times大于1,且*_rep_stride取值大于8(如取10)时,则相邻迭代间Vector读取的数据在地址上不连续,出现间隔(红色方框),详细介绍请参考非连续地址计算。
- 当repeat_times大于1,且*_rep_stride取值为0时,Vector会对首个连续的8个block进行反复读取和计算。
- 当repeat_times大于1,且*_rep_stride取值大于0且小于8时,相邻迭代间部分数据会被Vector重复读取和计算,此种情形一般场景不涉及。
综上,用户必须根据实际算子的数据访问模式,进行合适的参数设置,以保证获得正确的计算结果。
连续地址计算
from tbe import tik
tik_instance = tik.Tik()
data_input_gm = tik_instance.Tensor("float32", (256,), name="data_input_gm", scope=tik.scope_gm)
data_input_ub = tik_instance.Tensor("float32", (256,), name="data_input_ub", scope=tik.scope_ubuf)
tik_instance.data_move(data_input_ub, data_input_gm, 0, 1, 32, 0, 0)
# 使用vec_abs对data_input_ub进行单目操作
tik_instance.vec_abs(64, data_input_ub, data_input_ub, 256//64, 8, 8)
# 后续的搬出操作
在上述案例中,我们使用了vec_abs,它的作用是按每个元素取绝对值,总共对256个float32都取了绝对值。
- 第1个参数mask:共128bits,每一个bit位用来表示进行vector计算的向量中的每个元素是否参与操作,bit位的值为1表示参与计算,0表示不参与计算。可以使用数值来表示向量中从头连续多少个元素操作有效。在前几章学过,Vector计算单元的并行度为256Bytes,所以可以同时计算128个16位数值(mask最大为128)或64个32位数值(mask最大为64),例如mask=16,表示前16个elements参与计算。mask应用于每个迭代的源操作数,这里因为数据类型是float32,又全都参与计算,所以mask填64。
- 第4个参数repeat_times:计算重复的次数,每次计算最多计算256B,这里因为要计算256个float32,一个迭代可一次计算64个float32,即256B,所以需要重复迭代4次。
- 第5个参数dst_rep_stride:在相邻迭代间,迭代开始时目的操作数写入Block起始地址之间的步长,从每个迭代开始的第一个Block的起始地址开始算,如果连续,那相邻迭代就差256(Vector并行度) ÷ 32(Block的大小) = 8,填8即可。
- 第6个参数src_rep_stride:在相邻迭代间,同上,如果连续,填8即可。
如下数据计算图:

一个Block记录了8个float32,256个float32刚好是32个Block。一次计算可以算256Byte,所以一次Vector操作计算8个Block(红色粗框),计算重复迭代4次,直观地看出,rep_stride是相邻两个迭代的Block起始地址的距离,单位是Block;像上述的这种连续计算的情形,rep_stride为8。
注意:这里的dst和src是同一个Tensor,用户在使用时需要查阅具体接口说明,是否支持dst和src是同一个Tensor。
非连续地址计算
from tbe import tik
tik_instance = tik.Tik()
data_input_gm = tik_instance.Tensor("float32", (256,), name="data_input_gm", scope=tik.scope_gm)
data_input_ub = tik_instance.Tensor("float32", (256,), name="data_input_ub", scope=tik.scope_ubuf)
data_output_ub = tik_instance.Tensor("float32", (272,), name="data_output_ub", scope=tik.scope_ubuf)
tik_instance.data_move(data_input_ub, data_input_gm, 0, 1, 32, 0, 0)
# 使用vec_abs对data_input_ub进行单目操作
tik_instance.vec_abs(32, data_output_ub, data_input_ub, 2, 18, 16)
# 后续的搬出操作
vec_abs接口的作用是按每个元素取绝对值,其中:
- 第一个参数mask:共128bit,可同时计算64个32位数值,此处mask值配置为了32,所以一次repeat只会计算前32个float32,即4个Block。
- 第四个参数repeat_times:计算重复的次数,2代表需要重复迭代2次。
- 第五个参数dst_rep_stride:表示目的操作数迭代间Block起始地址之间相差18个Block,结合一次计算最多会涉及到8个Block的写入(Vector一次最多计算256Byte,即8个block),所以前后两次写入会间隔18 - 8 = 10个Block(如图2中dst红框间隔的10个Block)。
- 第六个参数src_rep_stride:表示源操作数迭代间Block起始地址之间相差16个Block,所以容易得到中间间隔16 - 8 =8个Block(如图2中src红框间隔的8个Block)。
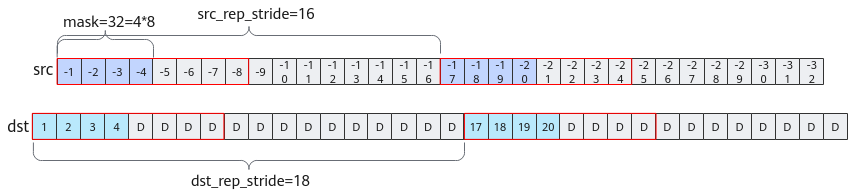
给定src中每个Block里的8个float32数值都是一样的(如src中第一个标-1的block块记录了8个-1),红框所示为一次repeat计算所涉及的内容,灰色表示不改变的内容,dst中D表示Default数值,即Tensor中原先存储的值。
注意:当UB有offset的情形时,处理方式和data_move类似,详情可参见有偏移的连续地址搬运,当前主要需要关注AI处理器是否要求UB的32B地址对齐。
课后练习
请各位读者按照之前所学的内容,回答如下TIK算子的预期结果:
from tbe import tik
tik_instance = tik.Tik()
data_input_gm_1 = tik_instance.Tensor("int32", (256,), name="data_input_gm_1", scope=tik.scope_gm)
data_input_ub_1 = tik_instance.Tensor("int32", (192,), name="data_input_ub_1", scope=tik.scope_ubuf)
data_input_gm_2 = tik_instance.Tensor("int32", (288,), name="data_input_gm_2", scope=tik.scope_gm)
data_input_ub_2 = tik_instance.Tensor("int32", (256,), name="data_input_ub_2", scope=tik.scope_ubuf)
data_output_ub = tik_instance.Tensor("int32", (256,), name="data_output_ub", scope=tik.scope_ubuf)
data_output_gm = tik_instance.Tensor("int32", (192,), name="data_output_ub", scope=tik.scope_gm)
tik_instance.vec_dup(64, data_input_ub_1, 0, 3, 1, 8)
tik_instance.data_move(data_input_ub_1, data_input_gm_1, 0, 4, 4, 4, 2)
tik_instance.data_move(data_input_ub_2, data_input_gm_2[32], 0, 1, 32, 8, 8)
tik_instance.vec_add(64, data_output_ub, data_input_ub_1, data_input_ub_2, 3, 8, 8, 8)
tik_instance.data_move(data_output_gm, data_output_ub, 0, 1, 24, 8, 8)
输入数据(int32):
data_input_gm_1 = {1,2,3,...,256}
data_input_gm_2 = {1,2,3,...,288}
1. 求搬出去的数据data_output_gm的前40个数值?
2. 想一想data_output_gm全部的值会是多少?
【参考答案】:
# 192个全部赋值为0
tik_instance.vec_dup(64, data_input_ub_1, 0, 3, 8)
# 按照规定的数据排布方式进行数据搬运,前40个值为{1,2,3,4,...,31,32,0,0,0,0,0,0,0,0}
tik_instance.data_move(data_input_ub_1, data_input_gm_1, 0, 4, 4, 4, 2)
# 按照规定的数据排布方式进行数据搬运,前40个值为{33,34,35,36,...,70,71,72}
tik_instance.data_move(data_input_ub_2, data_input_gm_2[32], 0, 1, 32, 8, 8)
# 全部连续地相加,mask是满的,最常见的情形
tik_instance.vec_add(64, data_output_ub, data_input_ub_1, data_input_ub_2, 3, 8, 8, 8)
# 全部连续地搬运数据,结果为{34,36,38,40,...,92,94,96,65,66,67,68,69,70,71,72}
tik_instance.data_move(data_output_gm, data_output_ub, 0, 1, 24, 8, 8)
# 全部192个数值是:{34,36,38,40,42,44,46,48,50,52,54,56,58,60,62,64,66,68,70,72,74,76,78,80,82,84,86,88,90,92,94,96,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,146,148,150,152,154,156,158,160,162,164,166,168,170,172,174,176,178,180,182,184,186,188,190,192,194,196,198,200,202,204,206,208,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127,128,258,260,262,264,266,268,270,272,274,276,278,280,282,284,286,288,290,292,294,296,298,300,302,304,306,308,310,312,314,316,318,320,161,162,163,164,165,166,167,168,169,170,171,172,173,174,175,176,370,372,374,376,378,380,382,384,386,388,390,392,394,396,398,400,402,404,406,408,410,412,414,416,418,420,422,424,426,428,430,432,209,210,211,212,213,214,215,216,217,218,219,220,221,222,223,224}