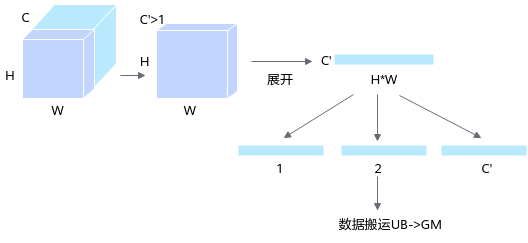
设计思路
本节以BatchNorm算子为例,介绍通过TIK方式进行算子开发的设计思路。
算子分析
BatchNorm算子主要包括以下两部分:
- 对输入进行归一化处理,xnorm = (x − μ) / σ,其中, μ和 σ是计算的均值和方差。
- 归一化后进行缩放和平移,得到输出y = γ * xnorm + β。
本样例重点关注的是算子动态shape场景,因此仅实现了归一化处理部分。
算子规格
参数 |
规格 |
|---|---|
支持框架 |
Caffe |
格式 |
单算子调用场景设计,采用NCHW格式。 |
输入数据类型 |
用户自行设计。当前样例为float16。 |
N |
用户自行设计。当前样例支持单Batch,即N=1。 |
C |
用户自行设计。当前样例为0~1024通道。 |
H |
用户自行设计。当前样例为0~1024像素。 |
W |
用户自行设计。当前样例为0~1024像素。 |
shape |
支持任意shape。 |
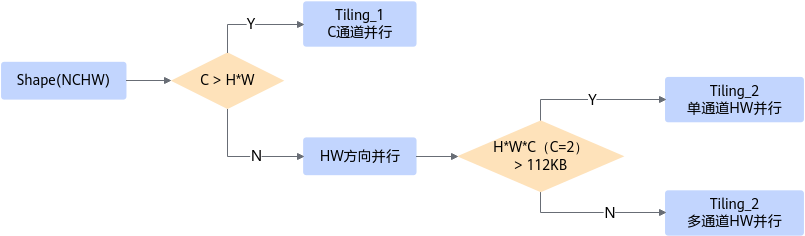
Tiling设计
场景划分 |
策略 |
|---|---|
C通道并行度占优,C > H*W |
Tiling_1:按照C通道方向并行逐像素点计算,通道设计需考虑32Byte对齐,采用Pingpong以及多核优化技术。 |
单通道HW并行度占优,C < H*W |
Tiling_2:单featuremap的H*W*C(C=2)>112KB时,则一次最多能搬运1个通道,按照单通道方向切分featmap来计算BN,考虑Global Memory与Unified Buffer间PingPong操作。 说明:112KB是结合pingpong流水线考虑后的Size值,为Unified Buffer空间的一半并保留一定大小的Buffer缓存空间,下文不再赘述。 |
Tiling_3:单featuremap的H*W*C(C>1) <= 112KB时,一次可搬运多个通道,Global Memory与Unified Buffer间pingpong操作,不同通道间可考虑多核优化。 |
下面分别介绍各种场景的详细设计思路:
- C通道并行场景设计思路。
对于C > HW场景,例如NCHW为1x1024x8x6时,C通道并行度占优,需要充分利用C通道并行逐像素计算每个点BatchNorm值。性能提升方面考虑pingpong流水线操作与多核并行技术,提高Unified Buffer利用率。
- Size(N*C*H*W) < 112KB, 只需1次Global Memory->Unified Buffer->Global Memory搬运,不需要考虑HW平面上的Tiling策略。
- Size(N*C*H*W) > 112KB, 需多次Global Memory->Unified Buffer->Global Memory搬运,需要考虑HW平面上的Tiling策略。当H*W或C不满足32Byte对齐时,需要补成32Byte对齐。
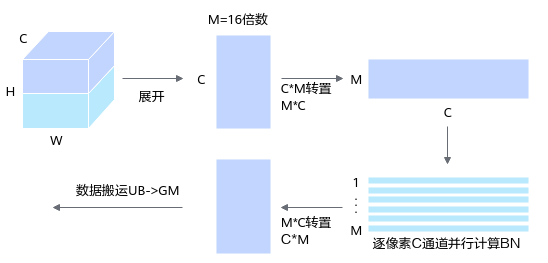
注:图中的M=16倍数,是针对当前例子的float16类型数据进行32Byte对齐。
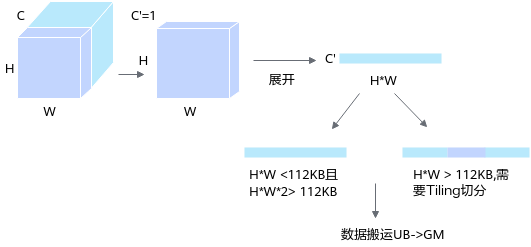
- 单通道HW并行场景设计思路。
- 当Size (H*W) < 112KB且Size (H*W*2) > 112KB时,仅考虑在单featuremap上逐像素计算每个点BatchNorm值。
- 当Size(H*W) > 112KB时,需考虑featuremap上Tiling策略。
设计时考虑Global Memory->Unified Buffer->Global Memory的PingPong操作,提高单位时间内Vector利用率,减少Vector等待时间。
- 多通道HW并行场景设计思路。
考虑Unified Buffer空间大小, 当Size (H*W*C) (C > 1) < 112KB时,可一次搬运多个通道的数据,C通道方向可以考虑多核并行计算。
设计时考虑Global Memory->Unified Buffer->Global Memory的PingPong操作,提高单位时间内Vector利用率,减少Vector等待时间。