FlashAttentionScore
算子基础信息
FlashAttentionScore算子新增torch_npu接口,支持torch_npu接口调用。
算子名称 |
FlashAttentionScore |
|---|---|
torch_npu api接口 |
torch_npu.npu_fusion_attention |
支持的torch_npu版本 |
1.11.0, 2.1.0, 2.2.0, 2.3.1 |
支持的芯片类型 |
Atlas A2 训练系列产品 |
支持的数据类型 |
float16, bfloat16 |
算子名称 |
FlashAttentionScore |
|---|---|
torch_npu api接口 |
torch.nn.functional.scaled_dot_product_attention |
支持的torch_npu版本 |
2.1.0, 2.2.0, 2.3.1 |
支持的芯片类型 |
Atlas A2 训练系列产品 |
支持的数据类型 |
float16, bfloat16 |
算子IR及torch_npu接口参数
REG_OP(FlashAttentionScore)
.INPUT(query, TensorType({DT_FLOAT16, DT_BF16}))
.INPUT(key, TensorType({DT_FLOAT16, DT_BF16}))
.INPUT(value, TensorType({DT_FLOAT16, DT_BF16}))
.OPTIONAL_INPUT(real_shift, TensorType({DT_FLOAT16, DT_BF16}))
.OPTIONAL_INPUT(drop_mask, TensorType({DT_UINT8}))
.OPTIONAL_INPUT(padding_mask, TensorType({DT_FLOAT16, DT_BF16}))
.OPTIONAL_INPUT(atten_mask, TensorType({DT_BOOL, DT_UINT8}))
.OPTIONAL_INPUT(prefix, TensorType({DT_INT64}))
.OPTIONAL_INPUT(actual_seq_qlen, TensorType({DT_INT64}))
.OPTIONAL_INPUT(actual_seq_kvlen, TensorType({DT_INT64}))
.OUTPUT(softmax_max, TensorType({DT_FLOAT32}))
.OUTPUT(softmax_sum, TensorType({DT_FLOAT32}))
.OUTPUT(softmax_out, TensorType({DT_FLOAT16, DT_BF16}))
.OUTPUT(attention_out, TensorType({DT_FLOAT16, DT_BF16}))
.ATTR(scale_value, Float, 1.0)
.ATTR(keep_prob, Float, 1.0)
.ATTR(pre_tockens, Int, 2147483647)
.ATTR(next_tockens, Int, 2147483647)
.REQUIRED_ATTR(head_num, Int)
.REQUIRED_ATTR(input_layout, String)
.ATTR(inner_precise, Int, 0)
.ATTR(sparse_mode, Int, 0)
.OP_END_FACTORY_REG(FlashAttentionScore)
torch_npu.npu_fusion_attention(Tensor query, Tensor key, Tensor value, int head_num, str input_layout, Tensor? pse=None, Tensor? padding_mask=None, Tensor? atten_mask=None, float scale=1., float keep_prob=1., int pre_tockens=2147483647, int next_tockens=2147483647, int inner_precise=0, int[]? prefix=None, int[]? actual_seq_qlen=None, int[]? actual_seq_kvlen=None, int sparse_mode=0, bool gen_mask_parallel=True, bool sync=False) -> (Tensor, Tensor, Tensor, Tensor, int, int, int)

torch_npu接口中的问号表示这个输入参数是可选的。
实现“Transformer Attention Score”的融合计算,实现的计算公式如下:
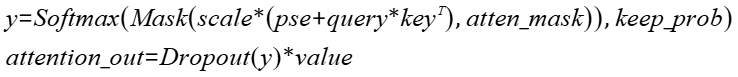
参数说明、输出说明和约束说明具体请参考《API 参考》中的“torch_npu.npu_fusion_attention”章节。
模型中替换代码
当前GPU模式下,调用FA算子的方式有多种,torch调用FA的接口scaled_dot_product_attention,通过flash-attention库中的flash_attn_func、flash_attn_varlen_func等接口调用。NPU模式下除了已经适配的sdpa接口,其余模式需要通过torch_npu接口——npu_fusion_attention接口实现调用。两者之间的适配可能涉及一些脚本迁移工作,以下通过范例说明接口适配方式。
torch原生接口
scaled_dot_product_attention:
- 不使能is_causal时,原调用接口代码:
res = torch.nn.functional.scaled_dot_product_attention(query, key, value, atten_mask=attention_mask, dropout_p=0.0, is_causal=False)替换为:
if atten_mask.dtype == torch.bool: atten_mask_npu = torch.logical_not(attention_mask.bool()).to(device) // atten_mask需要取反 else: atten_mask_npu = attention_mask.bool().to(device) head_num = query.shape[1] res = torch_npu.npu_fusion_attention( query, key, value, head_num, input_layout="BNSD", pse=None, atten_mask=atten_mask_npu, scale=1.0 / math.sqrt(query.shape[-1]), pre_tockens=2147483647, next_tockens=2147483647, keep_prob=1 )[0] - 使能is_causal时,原调用接口代码:
res = torch.nn.functional.scaled_dot_product_attention(query, key, value, atten_mask=None, dropout_p=0.0, is_causal=True)替换为:
atten_mask_npu = torch.triu(torch.ones([2048, 2048]), diagonal=1).bool().to(device) head_num = query.shape[1] res = torch_npu.npu_fusion_attention( query, key, value, head_num, input_layout="BNSD", pse=None, atten_mask=atten_mask_npu, scale=1.0 / math.sqrt(query.shape[-1]), pre_tockens=2147483647, next_tockens=2147483647, keep_prob=1, sparse_mode=2)[0]
- flash_attn_func
- 接口参数对应表格:
表3 接口参数替换 gpu参数名称
npu参数名称
说明
q
q
query;gpu、npu参数名一致且含义一致。
k
k
key;gpu、npu参数名一致且含义一致 。
v
v
value;gpu、npu参数名一致且含义一致。
dropout
keep_prob
keep_prob= 1 - dropout;gpu接口中dropout代表数据需要忽略的概率,npu接口中keep_prob代表数据需要保留的概率。
softmax_scale
scale
对QKT的缩放系数;gpu、npu参数名不一致,含义一致;npu接口参数的默认值为1.0,适配时查阅原实现的scale值。
causal
atten_mask
gpu接口参数causal=true时,npu接口需要传入下三角形式的atten mask;gpu接口参数causal=false时,npu接口不需要传入atten mask。
-
head_num
npu接口新增参数,表示query的头数。
-
layout
npu接口新增参数,表示qkv的layout,gpu接口默认layout为" BSND"。
-
sparse_mode
npu接口新增参数,表示稀疏计算模式。sparse_mode=2表示leftUp causal,sparse_mode=3表示rightDown causal;gpu接口在FA2.0版本及之前,causal场景默认是leftUp,在2.0版本之后,默认是rightDown。
- 接口参数替换实例:
out= flash_attn_func(q, k, v, dropout_p=0.0, softmax_scale=scale, causal=False)
替换为:
head_num = q.shape[2] out = torch_npu.npu_fusion_attention(q, k, v, head_num, "BSND", keep_prob=1.0, scale=scale)[0]使能causal时,模型中替换代码:
out= flash_attn_func(q, k, v, dropout_p=0.0, softmax_scale=scale, causal=True)
替换为:
atten_mask_npu = torch.triu(torch.ones([2048, 2048]), diagonal=1).bool().to(device) head_num = q.shape[2] out = torch_npu.npu_fusion_attention(q, k, v, head_num, "BSND", keep_prob=1.0, scale=scale, atten_mask=atten_mask_npu, sparse_mode=3)[0]
当替换flash-attention为2.0或之前版本时,应设置sparse_mode=2;当替换2.1或之后版本时,应设置sparse_mode=3。
- 接口参数对应表格:
- flash_attn_varlen_func
- 接口参数对应表格:
表4 接口参数替换 gpu参数名称
npu参数名称
说明
q
q
query;gpu、npu参数名一致且含义一致。
k
k
key;gpu、npu参数名一致且含义一致 。
v
v
value;gpu、npu参数名一致且含义一致。
dropout
keep_prob
keep_prob= 1 - dropout;gpu接口中dropout代表数据需要忽略的概率,npu接口中keep_prob代表数据需要保留的概率。
softmax_scale
scale
对QKT的缩放系数;gpu、npu参数名不一致,含义一致;npu接口参数的默认值为1.0,适配时查阅原实现的scale值。
causal
atten_mask
gpu接口参数causal=true时,npu接口需要传入下三角形式的atten mask;gpu接口参数causal=false时,npu接口不需要传入atten mask。
cu_seqlens_q
actual_seq_qlen
query 序列的累积长度;gpu、npu参数名不一致,含义一致;npu接口该参数需要转换为host侧的list格式。
cu_seqlens_k
ctual_seq_kvlen
key、value序列的累积长度 ;gpu、npu参数名不一致,含义一致;npu接口该参数需要转换为host侧的list格式。
max_seqlen_q
-
npu无需配置该参数; gpu接口中表示query 序列的最大长度,npu在接口内部计算。
max_seqlen_k
-
npu无需配置该参数; gpu接口中表示key、value序列的最大长度,npu在接口内部计算。
-
head_num
npu接口新增参数,表示query的头数。
-
layout
npu接口新增参数,表示qkv的layout,gpu接口默认layout为" BSND"。
-
sparse_mode
npu接口新增参数,表示稀疏计算模式。sparse_mode=2表示leftUp causal,sparse_mode=3表示rightDown causal;gpu接口在FA2.0版本及之前,causal场景默认是leftUp,在2.0版本之后,默认是rightDown。
- 接口参数替换实例:
out = flash_attn_varlen_func( q, k, v, cu_seqlens_q, cu_seqlens_k, max_seqlen_q, max_seqlen_k, dropout_p=0.0, softmax_scale=None, causal=False )替换为:
head_num = q.shape[1] output = torch_npu.npu_fusion_attention( q, k, v, head_num, pse=None, atten_mask=None, scale=1.0 / math.sqrt(q.shape[-1]), keep_prob=1, input_layout="TND", actual_seq_qlen=tuple(cu_seqlens_q[1:].cpu().numpy().tolist()), actual_seq_kvlen=tuple(cu_seqlens_k[1:].cpu().numpy().tolist()))[0]使能causal时,GPU调用接口代码:
out = flash_attn_varlen_func( q, k, v, cu_seqlens_q, cu_seqlens_k, max_seqlen_q, max_seqlen_k, dropout_p=0.0, softmax_scale=None, causal=True )替换为:
atten_mask_npu = torch.triu(torch.ones([2048, 2048]), diagonal=1).bool().to(device) head_num = q.shape[1] output = torch_npu.npu_fusion_attention( q, k, v, head_num, pse=None, padding_mask=None, atten_mask=atten_mask_npu, scale=1.0 / math.sqrt(q.shape[-1]), keep_prob=1, input_layout="TND", actual_seq_qlen=tuple(cu_seqlens_q[1:].cpu().numpy().tolist()), actual_seq_kvlen=tuple(cu_seqlens_k[1:].cpu().numpy().tolist()), sparse_mode=3)[0]
当替换flash-attention为2.0或之前版本时,应设置sparse_mode=2;当替换2.1或之后版本时,应设置sparse_mode=3。
- 接口参数对应表格:
xFormers库
memory_efficient_attention
def __init__(self, attention_op: Optional[Callable] = None):
self.attention_op = attention_op
def head_to_batch_dim(self, tensor):
tensor = tensor.reshape(batch_size * head_size, seq_len, dim // head_size)
return tensor
...
query = attn.head_to_batch_dim(query).contiguous()
key = attn.head_to_batch_dim(key).contiguous()
value = attn.head_to_batch_dim(value).contiguous()
hidden_states = xformers.ops.memory_efficient_attention(
query, key, value, attn_bias=attention_mask, op=self.attention_op, scale=attn.scale
)
def head_to_batch_dim(self, tensor, out_dim=3):
head_size = self.heads
batch_size, seq_len, dim = tensor.shape
tensor = torch_npu.npu_confusion_transpose(tensor, [0, 2, 1, 3], (batch_size, seq_len, head_size, dim // head_size), False)
if out_dim == 3:
tensor = tensor.reshape(batch_size * head_size, seq_len, dim // head_size)
return tensor
...
query = attn.head_to_batch_dim(query, out_dim=4)
key = attn.head_to_batch_dim(key, out_dim=4)
value = attn.head_to_batch_dim(value, out_dim=4)
hidden_states = torch_npu.npu_fusion_attention(
query, key, value, heads, input_layout="BNSD",
pse=None,
atten_mask=attention_mask,
scale=scale,
pre_tockens=2147483647,
next_tockens=2147483647,
keep_prob=1.,
sync=False
)[0]
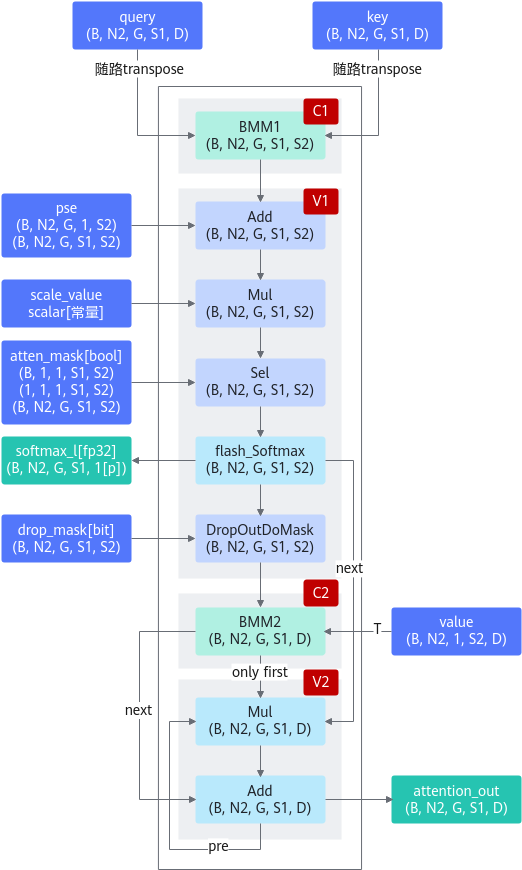
算子计算逻辑
def forward(q, k, v, drop_mask, atten_mask, pse, scale, keep_prob): if pse is None: qk = torch.matmul(q, k.permute(0, 1, 3, 2)).mul(scale) else: qk = (torch.matmul(q, k.permute(0, 1, 3, 2)) + pse).mul(scale) if atten_mask is None: qk = qk else: qk = qk + atten_mask * torch.finfo(torch.float32).min softmax_res, softmax_max, softmax_sum = softmax(qk) if drop_mask: drop_res = softmax_res else: drop_res = softmax_res * drop_mask * (1.0 / (keep_prob)) attention_out = torch.matmul(drop_res, v) return attention_out
已支持模型典型case
如下case均包含fp16、bf16。
id |
BNSD |
|---|---|
1 |
[1, 8, 4096, 128] |
2 |
[4, 32, 2048, 64] |
3 |
[8, 16, 512, 128] |
4 |
[8, 16, 512, 128] |
5 |
[8, 16, 512, 128] |
6 |
[8, 16, 512, 64] |
7 |
[8, 16, 512, 64] |
8 |
[4, 4, 2048, 64] |
torch原生接口调用FA算子使用限制
接口和参数说明:
使用限制:
- 参数输入符合规格:
- 输入query、key、value的N:batch size,当前只支持[N,head_num, S(L), E(Ev)]的排布方式,取值范围1~2K
- 输入query的head num和key/value的head num必须成比例关系,即Nq/Nkv必须是非0整数,取值范围1~256
- 输入query的L:Target sequence length,取值范围1~512K
- 输入key、value的S:Source sequence length,取值范围1~512K
- 输入query、key、value的E:Embedding dimension of the query and key,取值范围1~512
- 输入value的Ev:Embedding dimension of the value,必须与E相等
- 输入attn_mask:当前支持[N, 1, L, S]、[N, head_num, L, S]、[1, 1, L, S]、[L, S]共4种排布方式
- 在使能is_causal计算时,attn_mask必须为None;不使能is_causal时,若attn_mask输入有效数据,输入数据类型必须是Bool类型
- 与原接口除了规格限制之外存在差异点
- NPU用DSA硬件实现,算法在DSA引擎固化存在跟GPU算法实现差异,导致dropout功能和GPU结果不一致
- 当前接口支持输入query的head num和key/value的head num不等长,而原生PyTorch接口不支持
- 输入query、key、value的数据类型bf16、fp16、fp32并且使能requires_grad时,执行FA算子