自动迁移与训练
简介
下面介绍如何通过工具迁移ResNet50网络。
下载原始模型和数据集
使用迁移工具进行模型迁移
- 阅读使用限制,需要在工具迁移前手工添加数据集分片操作:
1 2 3 4 5 6 7 8 9 10
dataset = tf.data.Dataset.from_tensor_slices(filenames) import npu_device as npu # NPU添加的shard逻辑,会根据集群数量,对数据集和全局batch进行切分 dataset, batch_size = npu.distribute.shard_and_rebatch_dataset(dataset, batch_size) #if input_context: # logging.info( # 'Sharding the dataset: input_pipeline_id=%d num_input_pipelines=%d', # input_context.input_pipeline_id, input_context.num_input_pipelines) # dataset = dataset.shard(input_context.num_input_pipelines, # input_context.input_pipeline_id)
- 在运行环境上安装工具依赖。
pip3 install pandas
pip3 install openpyxl
pip3 install google_pasta
- 执行命令进行工具自动迁移。
- 进行迁移工具所在目录。
cd <tfplugin安装目录>/tfplugin/latest/python/site-packages/npu_device/convert_tf2npu/
- 进行脚本迁移。
- 若后续执行单Device训练,执行如下命令:
python3 main.py -i /root/models/official/vision/image_classification/resnet/ -o /root/models/resnet50/ -r /root/models/resnet50/ –m /root/models/official/vision/image_classification/resnet/resnet_ctl_imagenet_main.py
- 若后续需要执行分布式训练,执行如下命令:
python3 main.py -i /root/models/official/vision/image_classification/resnet/ -o /root/models/resnet50/ -r /root/models/resnet50/ –m /root/models/official/vision/image_classification/resnet/resnet_ctl_imagenet_main.py -d tf_strategy
其中“-d”代表原始脚本使用的分布式策略,“tf_strategy”表示原始脚本使用的是tf.distribute.Strategy分布式策略。
- 若后续执行单Device训练,执行如下命令:
- 进行迁移工具所在目录。
- 在/root/models/resnet50/report_npu_***下查看迁移报告。
打开api_analysis_report.xlsx,查看ResNet50网络中的API支持度情况:
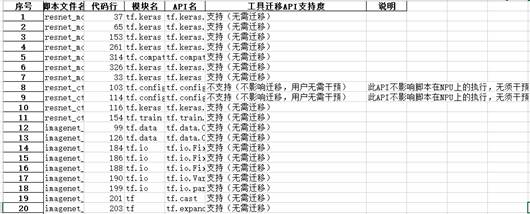
筛选“API支持度”这一列,发现所有接口分为如下几类:
- 支持:此类API在昇腾AI处理器上绝对支持,无需适配修改。
- 不支持(不影响迁移,无需干预):此类API在昇腾AI处理器上不支持,但不影响脚本执行,无需用户干预。
- 不支持(无迁移方案,建议不使用):此类API在昇腾AI处理器上不支持,且当前暂无具体迁移方案,建议您不要使用,否则会引起训练失败。
- 在/root/models/resnet50/output_npu_***下查看迁移后的脚本。
将原始脚本文件夹重命名,例如将/root/models/official/vision/image_classification/resnet重命名为resnet_org。
由于导入库文件依赖原始文件夹结构,要将迁移后的/root/models/resnet50/resnet_npu_***重命名为resnet,并拷贝回原始目录,命令示例如下:
cp -r /root/models/resnet50/resnet_npu_*** /root/models/official/vision/image_classification/resnet
执行单Device训练
- 由于原始脚本支持分布式训练,迁移后的脚本中使用了HCCL集合通信接口,则需要在单Device上执行训练前准备单Device的资源信息配置文件。否则请跳过此步。(本示例以配置文件的方式设置资源信息,您也可以参见训练执行(环境变量方式设置资源信息)通过环境变量的方式设置资源信息。)单Device的资源信息配置文件中需包含一个Device资源,文件名举例:rank_table_1p.json,配置文件举例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
{ "server_count":"1", "server_list": [ { "device":[ { "device_id":"0", "device_ip":"192.168.1.8", "rank_id":"0" } ], "server_id":"10.0.0.10" } ], "status":"completed", "version":"1.0" }
配置文件的详细介绍请参考准备ranktable资源配置文件。
- 配置训练进程启动依赖的环境变量。
安装CANN软件后,使用CANN运行用户进行编译、运行时,需要以CANN运行用户登录环境,执行source ${install_path}/set_env.sh命令设置环境变量。其中${install_path}为CANN软件的安装目录,例如:/usr/local/Ascend/ascend-toolkit。并进行如下配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
# 请依据实际在下列场景中选择一个训练依赖包安装路径的环境变量设置(以HwHiAiUser安装用户为例)。 # 场景一:昇腾设备安装部署开发套件包Ascend-cann-toolkit(此时开发环境可进行训练任务)。 . /home/HwHiAiUser/Ascend/ascend-toolkit/set_env.sh # 场景二:昇腾设备安装部署软件包Ascend-cann-nnae。 . /home/HwHiAiUser/Ascend/nnae/set_env.sh # tfplugin包依赖。 . /home/HwHiAiUser/Ascend/tfplugin/set_env.sh # 若运行环境中存在多个python3版本时,需要在环境变量中配置python的安装路径。如下配置以安装python3.7.5为例,可根据实际修改。 export PATH=/usr/local/python3.7.5/bin:$PATH export LD_LIBRARY_PATH=/usr/local/python3.7.5/lib:$LD_LIBRARY_PATH # 当前脚本所在路径,例如: export PYTHONPATH="$PYTHONPATH:/root/models" export JOB_ID=10086 # 训练任务ID,用户自定义,仅支持大小写字母,数字,中划线,下划线。不建议使用以0开始的纯数字 export ASCEND_DEVICE_ID=0 # 指定昇腾AI处理器的逻辑ID,单P训练也可不配置,默认为0,在0卡执行训练 export RANK_ID=0 # 指定训练进程在集合通信进程组中对应的rank标识序号,单P训练固定配置为0 export RANK_SIZE=1 # 指定当前训练进程对应的Device在本集群大小,单P训练固定配置为1 export RANK_TABLE_FILE=/root/rank_table_1p.json # 如果用户原始训练脚本中使用了hvd接口或tf.data.Dataset对象的shard接口,需要配置,否则无需配置,需要注意ranke_table中的参数“device_id”优先级高于环境变量“ASCEND_DEVICE_ID”。
- 执行训练脚本拉起训练进程:
python3 /root/models/official/vision/image_classification/resnet/resnet_ctl_imagenet_main.py
- 检查训练是否跑通。

执行分布式训练
下面以两个Device为例,说明如何使用迁移后的脚本在昇腾AI处理器上执行分布式训练。
- 准备包含两个Device的昇腾AI处理器资源信息配置文件,文件名举例:rank_table_2p.json,配置文件举例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
{ "server_count":"1", "server_list": [ { "device":[ { "device_id":"0", "device_ip":"192.168.1.8", "rank_id":"0" }, { "device_id":"1", "device_ip":"192.168.1.9", // 两个Device需要处于同一网段,0卡和1卡为同一网段 "rank_id":"1" } ], "server_id":"10.0.0.10" } ], "status":"completed", "version":"1.0" }
配置文件的详细介绍请参考准备ranktable资源配置文件。
- 在不同的shell窗口依次拉起不同的训练进程。
拉起训练进程0:
安装CANN软件后,使用CANN运行用户进行编译、运行时,需要以CANN运行用户登录环境,执行source ${install_path}/set_env.sh命令设置环境变量。其中${install_path}为CANN软件的安装目录,例如:/usr/local/Ascend/ascend-toolkit。并进行如下配置:
1 2 3 4 5
export PYTHONPATH="$PYTHONPATH:/root/models" export RANK_ID=0 export RANK_SIZE=2 export RANK_TABLE_FILE=/home/test/rank_table_2p.json python3 /root/models/official/vision/image_classification/resnet/resnet_ctl_imagenet_main.py
拉起训练进程1:
安装CANN软件后,使用CANN运行用户进行编译、运行时,需要以CANN运行用户登录环境,执行source ${install_path}/set_env.sh命令设置环境变量。其中${install_path}为CANN软件的安装目录,例如:/usr/local/Ascend/ascend-toolkit。并进行如下配置:
1 2 3 4 5 6
export PYTHONPATH="$PYTHONPATH:/root/models" export ASCEND_DEVICE_ID=1 export RANK_ID=1 export RANK_SIZE=2 export RANK_TABLE_FILE=/home/test/rank_table_2p.json python3 /root/models/official/vision/image_classification/resnet/resnet_ctl_imagenet_main.py
