简介
本章节详细介绍昇腾模型压缩工具量化场景,以及每个场景下的功能。
- 训练后量化
量化根据是否需要重训练,分为训练后量化(Post-Training Quantization)和量化感知训练(Quantization-Aware Training)。当前仅支持训练后量化,其中:
- 数据(activation)量化和权重(weight)量化
训练后量化根据量化对象不同,又分为数据(activation)量化和权重(weight)量化。
当前昇腾AI处理器支持数据(Activation)做对称/非对称量化,权重(weights)仅支持做对称量化(量化根据量化后数据中心点是否为0可以分为对称量化、非对称量化,详细的量化算法原理请参见量化算法原理)。
- 模型适配
如果用户对ONNX原始模型已经做了量化功能(以下简称QAT模型),但是该模型无法使用ATC工具转成适配昇腾AI处理器的离线模型,则需要借助昇腾模型压缩工具提供的convert_qat_model接口,将该QAT模型转成CANN量化模型格式。然后才能使用ATC工具,将CANN量化模型转成适配昇腾AI处理器的离线模型。
各功能以及功能实现过程中所使用的术语解释如下:
训练后量化
训练后量化(Post-Training Quantization,简称PTQ)是指在模型训练结束之后进行的量化,对训练后模型中的权重由浮点数(当前支持float32)量化到低比特整数(当前支持int8),并通过少量校准数据基于推理过程对数据(activation)进行校准量化,进而加速模型推理速度。训练后量化简单易用,只需少量校准数据,适用于追求高易用性和缺乏训练资源的场景。
通常,训练后的模型权重已经确定,因此可以根据权重的数值离线计算得到权重的量化参数。而通常数据是在线输入的,因此无法准确获取数据的数值范围,通常需要一个较小的有代表性的数据集来模拟在线数据的分布,利用该数据集执行前向推理,得到对应的中间浮点结果,并根据这些浮点结果离线计算出数据的量化参数。
其原理如图1所示。

数据(activation)量化
数据量化是指根据数据的数值分布情况,将输入的数据(activation)处理到低比特。每一层的数据分布是未知且巨大的,只能在前向过程(推理或者训练)中确定,因此数据量化是基于推理或者训练过程的。
而训练后量化场景通过在线量化的方式,通过修改用户推理模型,在待量化层位置插入旁路量化节点,采集待量化层输入数据,然后校准得到数据量化因子scale、offset。在推理时一般使用少量数据集,代表所有数据集的分布,简单快速。
权重(weight)量化
权重量化是指根据权重的数值分布情况,将权重处理到低比特。
训练后量化场景通过离线量化的方式,直接从用户推理模型中读取权重数据,然后调用量化算法对权重进行量化,并将量化后数据写回到模型当中,并参与数据量化。
测试数据集
数据集的子集,用于最终测试模型的效果。
校准
训练后量化场景中,做前向推理获取数据量化因子的过程。
校准数据集
训练后量化场景中,做前向推理使用的数据集。该数据集的分布代表着所有数据集的分布,获取校准集时应该具有代表性,推荐使用测试集的子集作为校准数据集。如果数据集不是模型匹配的数据集或者代表性不够,则根据校准集计算得到的量化因子,在全数据集上表现较差,量化损失大,量化后精度低。
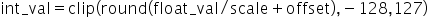
Scale
量化因子,浮点数的缩放因子,该参数又分为:
- scale_d:数据量化scale因子,仅支持对数据进行统一量化。
- scale_w:权重量化scale因子,支持标量(对当前层的权重进行统一量化),向量(对当前层的权重按channel_wise方式进行量化)两种模式。关于参数的更多说明请参见量化因子记录文件。
Offset
量化因子,偏移量,该参数又分为:
- offset_d:数据量化offset因子,仅支持对数据进行统一量化。
- offset_w:权重量化offset因子,同scale_w一样支持标量和向量两种模式,且需要同scale_w维度一致。关于参数的更多说明请参见量化因子记录文件。
