'%20fill='%23C31D20'%20fill-rule='nonzero'%3e%3cpath%20d='M7.55269822,13.7609409%20C10.8552199,9.97176134%2014.2271223,7.63452926%2017.1034483,6.5677512%20L17.0816429,0.884990191%20C17.0593112,0.508963963%2016.8188535,0.182653682%2016.4703158,0.055395956%20C16.1217781,-0.0718617705%2015.7322263,0.0244201241%2015.4799397,0.300178022%20L12.9584465,3.07097775%20L0.368821458,17.4916392%20C0.0232151224,17.8857306%20-0.0894678188,18.437454%200.0732192079,18.9389805%20C0.235906234,19.4405071%200.649247199,19.815643%201.15754056,19.9230783%20C1.66583392,20.0305135%202.19185783,19.853926%202.53746417,19.4598346%20L7.5467513,13.7690073%20L7.55269822,13.7609409%20Z'%20id='路径'%3e%3c/path%3e%3cpath%20d='M10.6896552,12.0927463%20L15.1004089,17.5535201%20C15.4511303,17.8402432%2015.9409156,17.8973222%2016.3502521,17.6991755%20C16.7595885,17.5010287%2017.0117165,17.0848129%2016.993637,16.6370685%20L17.1034483,10.0202479%20C14.5615201,9.75868982%2012.477139,10.7130773%2010.6896552,12.0927463%20Z'%20id='路径'%3e%3c/path%3e%3c/g%3e%3crect%20id='矩形'%20x='0'%20y='0'%20width='24'%20height='24'%3e%3c/rect%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
session配置参数说明
基础功能
配置项 |
说明 |
使用场景 |
|---|---|---|
graph_run_mode |
图执行模式,取值:
配置示例: custom_op.parameter_map["graph_run_mode"].i = 1 |
训练/在线推理 |
session_device_id |
当用户需要将不同的模型通过同一个脚本在不同的Device上执行,可以通过该参数指定Device的逻辑ID。 通常可以为不同的图创建不同的Session,并且传入不同的session_device_id。 配置示例: config_0 = tf.ConfigProto()
custom_op = config_0.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
custom_op.parameter_map["session_device_id"].i = 0
config_0.graph_options.rewrite_options.remapping = RewriterConfig.OFF
config_0.graph_options.rewrite_options.memory_optimization = RewriterConfig.OFF
with tf.Session(config=config_0) as sess_0:
sess_0.run(...)
config_1 = tf.ConfigProto()
custom_op = config_1.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
custom_op.parameter_map["session_device_id"].i = 1
config_1.graph_options.rewrite_options.remapping = RewriterConfig.OFF
config_1.graph_options.rewrite_options.memory_optimization = RewriterConfig.OFF
with tf.Session(config=config_1) as sess_1:
sess_1.run(...)
config_7 = tf.ConfigProto()
custom_op = config_7.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
custom_op.parameter_map["session_device_id"].i = 7
config_7.graph_options.rewrite_options.remapping = RewriterConfig.OFF
config_7.graph_options.rewrite_options.memory_optimization = RewriterConfig.OFF
with tf.Session(config=config_7) as sess_7:
sess_7.run(...) |
训练/在线推理 |
deterministic |
是否开启确定性计算,开启确定性开关后,算子在相同的硬件和输入下,多次执行将产生相同的输出。 此配置项有以下两种取值:
默认情况下,无需开启确定性计算。因为开启确定性计算后,算子执行时间会变慢,导致性能下降。在不开启确定性计算的场景下,多次执行的结果可能不同。这个差异的来源,一般是因为在算子实现中,存在异步的多线程执行,会导致浮点数累加的顺序变化。 但当发现模型执行多次结果不同,或者精度调优时,可以通过此配置开启确定性计算辅助进行调试调优。需要注意,如果希望有完全确定的结果,在训练脚本中需要设置确定的随机数种子,保证程序中产生的随机数也都是确定的。 配置示例: custom_op.parameter_map["deterministic"].i = 1 |
训练/在线推理 |
内存管理
动态分档
请注意动态分档场景下,以下三个参数需要配合使用。
配置项 |
说明 |
使用场景 |
|---|---|---|
input_shape |
输入的shape信息。 配置示例: custom_op.parameter_map["input_shape"].s = tf.compat.as_bytes("data:1,1,40,-1;label:1,-1;mask:-1,-1") 上面示例中表示网络中有三个输入,输入的name分别为data,label,mask,各输入的shape分别为(1,1,40,-1),(1,-1),(-1,-1),name和shape之间以英文冒号分隔。其中-1表示该维度上为动态档位,需要通过dynamic_dims设置动态档位参数。 配置注意事项:
|
在线推理 |
dynamic_dims |
输入的对应维度的档位信息。档位中间使用英文分号分隔,每档中的dim值与input_shape参数中的-1标识的参数依次对应,input_shape参数中有几个-1,则每档必须设置几个维度。并且要求档位信息必须大于1组。 input_shape和dynamic_dims这两个参数的分档信息能够匹配,否则报错退出。 配置示例: custom_op.parameter_map["dynamic_dims"].s = tf.compat.as_bytes("20,20,1,1;40,40,2,2;80,60,4,4") 结合上面举例的input_shape信息,表示支持输入的shape为:
|
在线推理 |
dynamic_node_type |
指定动态输入的节点类型。
当前不支持dataset和placeholder输入同时为动态输入。
配置示例:
custom_op.parameter_map["dynamic_node_type"].i = 0 |
在线推理 |
混合计算
配置项 |
说明 |
使用场景 |
|---|---|---|
mix_compile_mode |
是否开启混合计算模式。
计算全下沉模式即所有的计算类算子全部在Device侧执行,混合计算模式作为计算全下沉模式的补充,将部分不可离线编译下沉执行的算子留在前端框架中在线执行,提升昇腾AI处理器支持TensorFlow的适配灵活性。 配置示例: custom_op.parameter_map["mix_compile_mode"].b = True |
训练/在线推理 |
in_out_pair_flag |
混合计算场景下,指定in_out_pair中的算子是否下沉到昇腾AI处理器,取值:
配置示例: custom_op.parameter_map['in_out_pair_flag'].b = False |
在线推理 |
in_out_pair |
混合计算场景下,配置下沉/不下沉部分的首尾算子名。 配置示例: # 开启混合计算
custom_op.parameter_map["mix_compile_mode"].b = True
# 如下配置,将in_nodes, out_nodes范围内的算子全部下沉到昇腾AI处理器执行
in_nodes.append('import/conv2d_1/convolution')
out_nodes.append('import/conv2d_59/BiasAdd')
out_nodes.append('import/conv2d_67/BiasAdd')
out_nodes.append('import/conv2d_75/BiasAdd')
all_graph_iop.append([in_nodes, out_nodes])
custom_op.parameter_map['in_out_pair'].s = tf.compat.as_bytes(str(all_graph_iop))
# 或者通过如下配置,将in_nodes, out_nodes范围内的算子不下沉,全部留在前端框架执行
in_nodes.append('import/conv2d_1/convolution')
out_nodes.append('import/conv2d_59/BiasAdd')
out_nodes.append('import/conv2d_67/BiasAdd')
out_nodes.append('import/conv2d_75/BiasAdd')
all_graph_iop.append([in_nodes, out_nodes])
custom_op.parameter_map['in_out_pair_flag'].b = False
custom_op.parameter_map['in_out_pair'].s = tf.compat.as_bytes(str(all_graph_iop)) |
在线推理 |
功能调试
精度调优
配置项 |
说明 |
使用场景 |
|---|---|---|
precision_mode |
算子精度模式,配置要求为string类型。
训练场景下,针对Atlas 训练系列产品,默认值为“allow_fp32_to_fp16”。 训练场景下,针对Atlas A2 训练系列产品,默认值为“must_keep_origin_dtype”。 在线推理场景下,默认值为“force_fp16”。 配置示例: custom_op.parameter_map["precision_mode"].s = tf.compat.as_bytes("allow_mix_precision")
说明:
|
训练/在线推理 |
precision_mode_v2 |
算子精度模式,配置要求为string类型。
训练场景下:针对Atlas 训练系列产品,该配置项无默认取值,以“precision_mode”参数的默认值为准,即“allow_fp32_to_fp16”。针对Atlas A2 训练系列产品,该配置项默认值为“origin”。 在线推理场景下:该配置项默认值为“fp16”。 配置示例: custom_op.parameter_map["precision_mode_v2"].s = tf.compat.as_bytes("origin")
说明:
|
训练/在线推理 |
modify_mixlist |
开启混合精度的场景下,开发者可通过此参数指定混合精度黑白灰名单的路径以及文件名,自行指定哪些算子允许降精度,哪些算子不允许降精度。 用户可以在脚本中通过配置“precision_mode”参数或者“precision_mode_v2”参数开启混合精度。
黑白灰名单存储文件为json格式,配置示例如下:
custom_op.parameter_map["modify_mixlist"].s = tf.compat.as_bytes("/home/test/ops_info.json")
ops_info.json中可以指定算子类型,多个算子使用英文逗号分隔,样例如下: {
"black-list": { // 黑名单
"to-remove": [ // 黑名单算子转换为灰名单算子
"Xlog1py"
],
"to-add": [ // 白名单或灰名单算子转换为黑名单算子
"Matmul",
"Cast"
]
},
"white-list": { // 白名单
"to-remove": [ // 白名单算子转换为灰名单算子
"Conv2D"
],
"to-add": [ // 黑名单或灰名单算子转换为白名单算子
"Bias"
]
}
} 说明:上述配置文件样例中展示的算子仅作为参考,请基于实际硬件环境和具体的算子内置优化策略进行配置。 混合精度场景下算子的内置优化策略可在“OPP安装目录/opp/built-in/op_impl/ai_core/tbe/config/<soc_version>/aic-<soc_version>-ops-info.json”文件中查询,例如: "Conv2D":{
"precision_reduce":{
"flag":"true"
},
|
训练/在线推理 |
customize_dtypes |
使用precision_mode参数设置整个网络的精度模式时,可能会存在个别算子存在精度问题,此种场景下,可以使用customize_dtypes参数配置个别算子的精度模式,而模型中的其他算子仍以precision_mode指定的精度模式进行编译。需要注意,当precision_mode取值为“must_keep_origin_dtype”时,customize_dtypes参数不生效。 该参数需要配置为配置文件路径及文件名,例如:/home/test/customize_dtypes.cfg。 配置示例: custom_op.parameter_map["customize_dtypes"].s = tf.compat.as_bytes("/home/test/customize_dtypes.cfg") 配置文件中列举需要自定义计算精度的算子名称或算子类型,每个算子单独一行,且算子类型必须为基于Ascend IR定义的算子的类型。对于同一个算子,如果同时配置了算子名称和算子类型,编译时以算子名称为准。 配置文件格式要求: # 按照算子名称配置 Opname1::InputDtype:dtype1,dtype2,…OutputDtype:dtype1,… Opname2::InputDtype:dtype1,dtype2,…OutputDtype:dtype1,… # 按照算子类型配置 OpType::TypeName1:InputDtype:dtype1,dtype2,…OutputDtype:dtype1,… OpType::TypeName2:InputDtype:dtype1,dtype2,…OutputDtype:dtype1,… 配置文件配置示例: # 按照算子名称配置 resnet_v1_50/block1/unit_3/bottleneck_v1/Relu::InputDtype:float16,int8,OutputDtype:float16,int8 # 按照算子类型配置 OpType::Relu:InputDtype:float16,int8,OutputDtype:float16,int8
说明:
|
在线推理/训练 |
精度比对
配置项 |
说明 |
使用场景 |
|---|---|---|
enable_dump |
是否开启Data Dump功能,默认值:False。
配置示例:
custom_op.parameter_map["enable_dump"].b = True |
训练/在线推理 |
dump_mode |
Data Dump模式,用于指定dump算子输入还是输出数据。取值如下:
配置示例: custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all") |
训练/在线推理 |
enable_dump_debug |
溢出检测场景下,是否开启溢出数据采集功能,默认值:False。
说明:
不能同时开启Data Dump与溢出数据采集功能,即不同时将enable_dump和enable_dump_debug参数配置为“True”。 配置示例: custom_op.parameter_map["enable_dump_debug"].b = True |
训练 |
dump_debug_mode |
溢出检测模式,取值如下:
配置示例: custom_op.parameter_map["dump_debug_mode"].s = tf.compat.as_bytes("all") |
训练 |
dump_path |
Dump文件保存路径。enable_dump或enable_dump_debug为true时,该参数必须配置。 该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限,支持配置绝对路径或相对路径(相对执行命令行时的当前路径)。
配置示例: custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output") |
训练/在线推理 |
dump_step |
指定采集哪些迭代的Data Dump数据。默认值:None,表示所有迭代都会产生dump数据。 多个迭代用“|”分割,例如:0|5|10;也可以用"-"指定迭代范围,例如:0|3-5|10。 配置示例: custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10") |
训练 |
dump_data |
指定算子dump内容类型,取值:
大规模训练场景下,通常dump数据量太大并且耗时长,可以先dump所有算子的统计数据,根据统计数据识别可能异常的算子,然后再指定dump异常算子的input或output数据。 配置示例: custom_op.parameter_map["dump_data"].s = tf.compat.as_bytes("stats") |
训练/在线推理 |
dump_layer |
指定需要dump的算子。取值为算子名,多个算子名之间使用空格分隔。若不配置此字段,默认dump全部算子。 配置示例: custom_op.parameter_map["dump_layer"].s = tf.compat.as_bytes("nodename1 nodename2 nodename3") |
训练/在线推理 |
fusion_switch_file |
融合开关配置文件路径以及文件名。 格式要求:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、中划线(-)、句点(.)、中文字符。 系统内置了一些图融合和UB融合规则,均为默认开启,可以根据需要关闭指定的融合规则。 配置文件样例fusion_switch.cfg如下所示,on表示开启,off表示关闭。 {
"Switch":{
"GraphFusion":{
"RequantFusionPass":"on",
"ConvToFullyConnectionFusionPass":"off",
"SoftmaxFusionPass":"on",
"NotRequantFusionPass":"on",
"SplitConvConcatFusionPass":"on",
"ConvConcatFusionPass":"on",
"MatMulBiasAddFusionPass":"on",
"PoolingFusionPass":"on",
"ZConcatv2dFusionPass":"on",
"ZConcatExt2FusionPass":"on",
"TfMergeSubFusionPass":"on"
},
"UBFusion":{
"TbePool2dQuantFusionPass":"on"
}
}
} 同时支持用户一键关闭融合规则: {
"Switch":{
"GraphFusion":{
"ALL":"off"
},
"UBFusion":{
"ALL":"off"
}
}
} 需要注意的是:
配置示例: custom_op.parameter_map["fusion_switch_file"].s = tf.compat.as_bytes("/home/test/fusion_switch.cfg") |
训练/在线推理 |
buffer_optimize |
高级开关,是否开启buffer优化。
配置示例: custom_op.parameter_map["buffer_optimize"].s = tf.compat.as_bytes("l2_optimize") |
在线推理 |
use_off_line |
是否在昇腾AI处理器执行训练。
配置示例: custom_op.parameter_map["use_off_line"].b = True |
训练/在线推理 |
性能调优
- 基础配置
配置项
说明
使用场景
iterations_per_loop
sess.run模式下通过set_iteration_per_loop配置小循环次数,即每次sess.run(),在Device侧执行训练迭代的次数。
此处的配置参数和set_iteration_per_loop设置的iterations_per_loop值保持一致,用于功能校验。
配置示例:
custom_op.parameter_map["iterations_per_loop"].i = 10
训练
- 高级配置
配置项
说明
使用场景
hcom_parallel
分布式训练场景下,可通过此开关控制是否启用Allreduce梯度更新和前后向并行执行。
- True:开启Allreduce并行。
- False:关闭Allreduce并行。
默认值为“True”,针对小网络(例如:Resnet18),可配置为False。
配置示例:
custom_op.parameter_map["hcom_parallel"].b = True
训练
enable_small_channel
是否使能small channel的优化,使能后在channel<=4的卷积层会有性能收益。
- 0:关闭。训练(graph_run_mode为1)场景下默认关闭,且训练场景下不建议用户开启。
- 1:使能。在线推理(graph_run_mode为0)场景下不支持用户配置,默认使能。
说明:
该参数使能后,当前只在Resnet50、Resnet101、Resnet152网络模型能获得性能收益。其他网络模型性能可能会下降,用户根据实际情况决定是否使能该参数。
配置示例:
custom_op.parameter_map["enable_small_channel"].i = 1
在线推理/训练
op_precision_mode
设置具体某个算子的高精度或高性能模式,通过该参数传入自定义的模式配置文件op_precision.ini,可以为不同的算子设置不同的模式。
支持按照算子类型或者按照节点名称设置,按节点名称设置的优先级高于算子类型,样例如下:[ByOpType] optype1=high_precision optype2=high_performance optype3=support_out_of_bound_index [ByNodeName] nodename1=high_precision nodename2=high_performance nodename3=support_out_of_bound_index
- high_precision:表示高精度。
- high_performance:表示高性能。
- support_out_of_bound_index:表示对gather、scatter和segment类算子的indices输入进行越界校验, 校验会降低算子的执行性能。
具体某个算子支持配置的精度/性能模式取值,可通过CANN软件安装后文件存储路径的opp/built-in/op_impl/ai_core/tbe/impl_mode/all_ops_impl_mode.ini 文件查看。
该参数不能与op_select_implmode、optypelist_for_implmode参数同时使用,若三个参数同时配置,则只有op_precision_mode参数指定的模式生效。
一般场景下该参数无需配置。若使用高性能或者高精度模式,网络性能或者精度不是最优,则可以使用该参数,通过配置ini文件调整某个具体算子的精度模式。
配置示例:
custom_op.parameter_map["op_precision_mode"].s = tf.compat.as_bytes("/home/test/op_precision.ini")训练/在线推理
enable_scope_fusion_passes
指定编译时需要生效的Scope融合规则列表。此处传入注册的融合规则名称,允许传入多个,用“,”隔开。
无论是内置还是用户自定义的Scope融合规则,都分为如下两类:
- 通用融合规则(General):各网络通用的Scope融合规则;默认生效,不支持用户指定失效。
- 定制化融合规则(Non-General):特定网络适用的Scope融合规则;默认不生效,用户可以通过enable_scope_fusion_passes指定生效的融合规则列表。
配置示例:
custom_op.parameter_map["enable_scope_fusion_passes"].s = tf.compat.as_bytes("ScopeLayerNormPass,ScopeClipBoxesPass")训练/在线推理
stream_max_parallel_num
此配置项仅适用于NMT网络。
用于指定AI CPU/AI Core引擎的并行度,从而实现AI CPU/AI Core算子间的并行执行。
DNN_VM_AICPU为AI CPU引擎名称,本示例指定了AI CPU引擎的并发数为10;
AIcoreEngine为AI Core引擎名称,本示例指定了AI Core引擎的并发数为1。
AI CPU/AI Core引擎的并行度默认为1,取值不能超过AI Core的最大核数。
配置示例:
custom_op.parameter_map["stream_max_parallel_num"].s = tf.compat.as_bytes("DNN_VM_AICPU:10,AIcoreEngine:1")训练/在线推理
is_tailing_optimization
此配置项仅适用于Bert网络。
分布式训练场景下,是否开启通信拖尾优化,用于提升训练性能。通信拖尾优化即,通过计算依赖关系的改变,将不依赖于最后一个AR(梯度聚合分片)的计算操作调度到和最后一个AR并行进行,以达到优化通信拖尾时间的目的。取值:
- True:开启通信拖尾优化。
- False:不开启通信拖尾优化,默认为False。
必须和NPUOptimizer配合使用,且要求和NPUOptimizer中的is_tailing_optimization值保持一致。
配置示例:
custom_op.parameter_map["is_tailing_optimization"].b = True
训练
variable_placement
若网络的权重较大,Device侧可能存在内存不足导致网络执行失败的场景,此种情况下可通过此配置将variable的部署位置调整到Host,以降低Device的内存占用。- Device:Variable部署在Device。
- Host:Variable部署在Host。
默认值为:Device
约束说明:- 如果此配置项取值为“Host”,需要开启混合计算(即mix_compile_mode取值为“True”)。
- 若训练脚本中存在类似tf.case/tf.cond/tf.while_loop等TensorFlow V1版本控制流算子对应的API,此种场景下,如果将“variable_placement”配置为“Host”,可能会导致网络运行失败。为避免此问题,需要在训练脚本中添加如下接口,将TensorFlow V1版本的控制流算子转换为V2版本,并启用资源变量。
tf.enable_control_flow_v2() tf.enable_resource_variables()
配置示例:
custom_op.parameter_map["variable_placement"].s = tf.compat.as_bytes("Device")训练/在线推理
frozen_variable
当开发者需要将权重保存为checkpoint时,可通过此配置将variable转换为const,以减少Host到Device之间的数据拷贝,从而提升推理性能。- True:开启variable到const的转换
- False:不进行variable到const的转换
默认值为:False
配置示例:
custom_op.parameter_map["frozen_variable"].b = True
在线推理
Profiling
AOE
算子编译
数据增强
配置项 |
说明 |
使用场景 |
|---|---|---|
local_rank_id |
该参数用于推荐网络场景的数据并行场景,在主进程中对于数据进行去重操作,去重之后的数据再分发给其他进程的Device进行前后向计算。
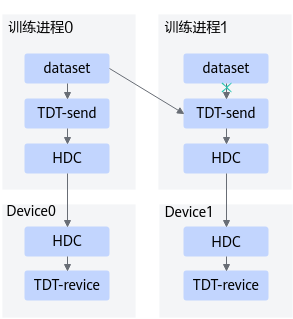
该模式下,一个主机上多Device共用一个进程做数据预处理,但实际还是多进程的场景,在主进程上进行数据预处理,其他进程不在接受本进程上的Dataset,而是接收主进程预处理后的数据。 具体使用方法一般是通过集合通信的get_local_rank_id()接口获取当前进程在其所在Server内的rank编号,用来判断哪个进程是主进程。 配置示例: custom_op.parameter_map["local_rank_id"].i = 0 |
训练/在线推理 |
local_device_list |
该参数配合local_rank_id使用,用来指定主进程给哪些其他进程的Device发送数据。 custom_op.parameter_map["local_device_list"].s = tf.compat.as_bytes("0,1") |
训练/在线推理 |
异常补救
配置项 |
说明 |
使用场景 |
|---|---|---|
hccl_timeout |
集合通信超时时间,单位为s,默认值1800s。 当默认时长不满足需求时(例如出现通信失败的错误),可通过此配置项延长超时时间。
配置示例: custom_op.parameter_map["hccl_timeout"].i = 1800 |
训练 |
op_wait_timeout |
算子等待超时时间,单位为s,默认值为120s。 当默认时长不满足需求时,可通过此配置项延长超时时间。 配置示例: custom_op.parameter_map["op_wait_timeout"].i = 120 |
训练 |
op_execute_timeout |
算子执行超时时间,单位为s。 配置示例: custom_op.parameter_map["op_execute_timeout"].i = 90 |
训练 |
stream_sync_timeout |
图执行时,stream同步等待超时时间,超过配置时间时报同步失败。单位:ms 默认值-1,表示无等待时间,出现同步失败不报错。 说明:集群训练场景下,此配置的值(即stream同步等待超时时间)需要大于集合通信超时时间,即“hccl_timeout”配置项的值或者环境变量“HCCL_EXEC_TIMEOUT”的值。 配置示例: custom_op.parameter_map["stream_sync_timeout"].i = 60000 |
训练 |
event_sync_timeout |
图执行时,event同步等待超时时间,超过配置时间时报同步失败。单位:ms 默认值-1,表示无等待时间,出现同步失败不报错。 配置示例: custom_op.parameter_map["event_sync_timeout"].i = 60000 |
训练 |
量化压缩
配置项 |
说明 |
使用场景 |
|---|---|---|
enable_compress_weight |
使能全局weight压缩。 AICore支持Weight压缩功能,通过该参数,可以对Weight进行数据压缩,在进行算子计算时,对Weight进行解压缩,从而达到减少带宽、提高性能的目的。 该参数不能与compress_weight_conf同时使用。
配置示例: custom_op.parameter_map["enable_compress_weight"].b = True |
在线推理 |
compress_weight_conf |
要压缩的node节点列表配置文件路径以及文件名。node节点主要为conv算子、fc算子。 格式要求:支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、中划线(-)、句点(.)、中文字符。 该参数不能与enable_compress_weight参数同时使用。 weight压缩配置文件中的算子列表由AMCT输出(输出路径为非均匀量化结果路径下记录非均匀量化层名的文件,例如:module/results/calibration_results/module_nuq_layer_record.txt),文件内容即为node名称列表, 配置文件compress_weight_nodes.cfg样例如下所示,node名称之间以“;”间隔开。 conv1;fc1;conv2_2/x1;fc2;conv5_32/x2;fc6 配置示例: custom_op.parameter_map["compress_weight_conf"].s = tf.compat.as_bytes("/home/test/compress_weight_nodes.cfg") |
在线推理 |
试验参数
试验参数为调试功能扩展参数,后续版本可能会存在变更,不支持应用于商用产品中。
配置项 |
说明 |
使用场景 |
|---|---|---|
jit_compile |
模型编译时,选择是优先在线编译算子,还是优先使用已编译好的算子二进制文件。
默认值:auto。
须知:
配置示例: custom_op.parameter_map["jit_compile"].s = tf.compat.as_bytes( "auto") |
训练/在线推理 |
experimental_accelerate_train_mode |
针对超过1小时以上的训练场景,开发者可以通过此配置触发训练加速,提升训练性能。 软件内部会根据开发者配置的加速类型、加速触发模式以及低精度训练流程占比,对相应比例的训练流程降精度编译运行,剩余的训练流程仍按照原始精度编译运行。
该配置项取值类型为字符串,由“|”符号分割为三个字段,例如:fast|step|0.9。
配置示例:
需要注意:
|
训练 |
后续版本废弃配置
以下参数在后续版本将过期,建议开发者不再使用。
配置项 |
说明 |
使用场景 |
|---|---|---|
op_debug_level |
功能调试配置项。 算子debug功能开关,取值:
默认值为空,代表不使能此配置。 配置示例: custom_op.parameter_map["op_debug_level"].i = 0 |
训练/在线推理 |
enable_data_pre_proc |
性能调优配置项。 getnext算子是否下沉到昇腾AI处理器侧执行,getnext算子下沉是使能训练迭代循环下沉的必要条件。
配置示例:
custom_op.parameter_map["enable_data_pre_proc"].b = True |
训练 |
variable_format_optimize |
性能调优配置项。 是否开启变量格式优化。
为了提高训练效率,在网络执行的变量初始化过程中,将变量转换成更适合在昇腾AI处理器上运行的数据格式,例如进行NCHW到NC1HWC0的数据格式转换。但在用户特殊要求场景下,可以选择关闭该功能开关。 默认值为空,代表不使能此配置。 配置示例: custom_op.parameter_map["variable_format_optimize"].b = True |
训练 |
op_select_implmode |
性能调优配置项。 昇腾AI处理器部分内置算子有高精度和高性能实现方式,用户可以通过该参数配置模型编译时选择哪种算子。取值包括:
默认值为空,代表不使能此配置。 配置示例: custom_op.parameter_map["op_select_implmode"].s = tf.compat.as_bytes("high_precision") |
训练/在线推理 |
optypelist_for_implmode |
性能调优配置项。 列举算子optype的列表,该列表中的算子使用op_select_implmode参数指定的模式,当前支持的算子为Pooling、SoftmaxV2、LRN、ROIAlign,多个算子以英文逗号分隔。 该参数需要与op_select_implmode参数配合使用,例如: op_select_implmode配置为high_precision。 optypelist_for_implmode配置为Pooling。 默认值为空,代表不使能此配置。 配置示例: custom_op.parameter_map["optypelist_for_implmode"].s = tf.compat.as_bytes("Pooling,SoftmaxV2") |
训练/在线推理 |
dynamic_input |
当前网络的输入是否为动态输入,取值包括:
配置示例: custom_op.parameter_map["dynamic_input"].b = True |
训练/在线推理 |
dynamic_graph_execute_mode |
对于动态输入场景,需要通过该参数设置执行模式,即dynamic_input为True时该参数生效。取值为: dynamic_execute:动态图编译模式。该模式下获取dynamic_inputs_shape_range中配置的shape范围进行编译。 配置示例: custom_op.parameter_map["dynamic_graph_execute_mode"].s = tf.compat.as_bytes("dynamic_execute") |
训练/在线推理 |
dynamic_inputs_shape_range |
动态输入的shape范围。例如全图有3个输入,两个为dataset输入,一个为placeholder输入,则配置示例为: custom_op.parameter_map["dynamic_inputs_shape_range"].s = tf.compat.as_bytes("getnext:[128 ,3~5, 2~128, -1],[64 ,3~5, 2~128, -1];data:[128 ,3~5, 2~128, -1]") 使用注意事项:
|
训练/在线推理 |
graph_memory_max_size |
历史版本,该参数用于指定网络静态内存和最大动态内存的大小。 当前版本,该参数不再生效。系统会根据网络使用的实际内存大小动态申请。 |
训练/在线推理 |
variable_memory_max_size |
历史版本,该参数用于指定变量内存的大小。 当前版本,该参数不再生效。系统会根据网络使用的实际内存大小动态申请。 |
训练/在线推理 |
