使用说明
Ascend C提供一组Matmul高阶API,方便用户快速实现Matmul矩阵乘法的运算操作。
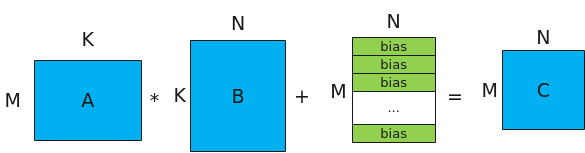
Matmul的计算公式为:C = A * B + Bias,其示意图如下。
- A、B为源操作数,A为左矩阵,形状为[M, K];B为右矩阵,形状为[K, N]。
- C为目的操作数,存放矩阵乘结果的矩阵,形状为[M, N]。
- Bias为矩阵乘偏置,形状为[1, N]。对A*B结果矩阵的每一行都采用该Bias进行偏置。
除Matmul的基本功能外,对Matmul的特性场景说明如下。您可以根据实际应用场景,选择性了解Matmul特性场景的内容。
- Matmul Tiling常量化
Matmul Tiling常量化为在编译期期间获取常量化的Matmul Tiling参数并进行算子编译,从而减少Scalar计算开销,提升算子整体性能。具体为,在获取Matmul模板时,可以确定MatmulConfig的singleCore Shape(MatmulConfig中的singleCoreM/singleCoreN/singleCoreK)和Base Shape(MatmulConfig中的basicM/basicN/basicK)参数,或者只确定Base Shape参数;通过指定获取模板的接口中的singleCore Shape和Base Shape参数,或者只指定Base Shape参数,获取自定义模板;然后通过调用GetMatmulApiTiling接口,得到常量化的Matmul Tiling参数。

下文中提及的M轴方向,即为A矩阵纵向;K轴方向,即为A矩阵横向或B矩阵纵向;N轴方向,即为B矩阵横向;尾轴,即为矩阵最后一个维度。
实现Matmul矩阵乘运算的具体步骤如下:
- 创建Matmul对象。
- 初始化操作。
- 设置左矩阵A、右矩阵B、Bias。
- 完成矩阵乘操作。
- 结束矩阵乘操作。
- 创建Matmul对象
创建Matmul对象的示例如下:
- 默认为MIX模式(包含矩阵计算和矢量计算),该场景下,不能定义ASCENDC_CUBE_ONLY宏。
- 纯Cube模式(只有矩阵计算)场景下,需要在代码中定义ASCENDC_CUBE_ONLY宏。
1 2 3 4 5 6 7 8 9
// 纯cube模式(只有矩阵计算)场景下,需要设置该代码宏,并且必须在#include "lib/matmul_intf.h"之前设置 // #define ASCENDC_CUBE_ONLY #include "lib/matmul_intf.h" typedef matmul::MatmulType<AscendC::TPosition::GM, CubeFormat::ND, half> aType; typedef matmul::MatmulType<AscendC::TPosition::GM, CubeFormat::ND, half> bType; typedef matmul::MatmulType<AscendC::TPosition::GM, CubeFormat::ND, float> cType; typedef matmul::MatmulType<AscendC::TPosition::GM, CubeFormat::ND, float> biasType; matmul::Matmul<aType, bType, cType, biasType> mm;
创建对象时需要传入A、B、C、Bias的参数类型信息, 类型信息通过MatmulType来定义,包括:内存逻辑位置、数据格式、数据类型。
1 2 3 4 5 6 7 8
template <AscendC::TPosition POSITION, CubeFormat FORMAT, typename TYPE, bool ISTRANS = false, LayoutMode LAYOUT = LayoutMode::NONE, bool IBSHARE = false> struct MatmulType { constexpr static AscendC::TPosition pos = POSITION; constexpr static CubeFormat format = FORMAT; using T = TYPE; constexpr static bool isTrans = ISTRANS; constexpr static LayoutMode layout = LAYOUT; constexpr static bool ibShare = IBSHARE; };
表1 MatmulType参数说明 参数
说明
POSITION
内存逻辑位置
针对
Atlas A2 训练系列产品/Atlas 800I A2 推理产品 :- A矩阵可设置为TPosition::GM,TPosition::VECOUT,TPosition::TSCM
- B矩阵可设置为TPosition::GM,TPosition::VECOUT,TPosition::TSCM
- Bias可设置为TPosition::GM,TPosition::VECOUT,TPosition::TSCM
- C矩阵可设置为TPosition::GM,TPosition::VECIN
针对
Atlas 推理系列产品AI Core :- A矩阵可设置为TPosition::GM,TPosition::VECOUT
- B矩阵可设置为TPosition::GM,TPosition::VECOUT
- Bias可设置为TPosition::GM,TPosition::VECOUT
- C矩阵可设置为TPosition::GM,TPosition::VECIN
针对
Atlas 200I/500 A2 推理产品 :- A矩阵可设置为TPosition::GM,TPosition::VECOUT,TPosition::TSCM
- B矩阵可设置为TPosition::GM,TPosition::VECOUT,TPosition::TSCM
- Bias可设置为TPosition::GM,TPosition::VECOUT
- C矩阵可设置为TPosition::GM,TPosition::VECIN
CubeFormat
针对
Atlas A2 训练系列产品/Atlas 800I A2 推理产品 :- A矩阵可设置为CubeFormat::ND,CubeFormat::NZ
- B矩阵可设置为CubeFormat::ND,CubeFormat::NZ
- Bias可设置为CubeFormat::ND
- C矩阵可设置为CubeFormat::ND,CubeFormat::NZ,CubeFormat::ND_ALIGN
针对
Atlas 推理系列产品AI Core :- A矩阵可设置为CubeFormat::ND,CubeFormat::NZ
- B矩阵可设置为CubeFormat::ND,CubeFormat::NZ
- Bias可设置为CubeFormat::ND
- C矩阵可设置为CubeFormat::ND,CubeFormat::NZ,CubeFormat::ND_ALIGN
TYPE
数据类型。
针对Atlas A2 训练系列产品/Atlas 800I A2 推理产品 :- A矩阵可设置为half、float、bfloat16_t 、int8_t、int4b_t
- B矩阵可设置为half、float、bfloat16_t 、int8_t、int4b_t
- Bias可设置为half、float、int32_t
- C矩阵可设置为half、float、bfloat16_t、int32_t、int8_t
针对
Atlas 推理系列产品AI Core :- A矩阵可设置为half、int8_t
- B矩阵可设置为half、int8_t
- Bias可设置为float、int32_t
- C矩阵可设置为half、float、int8_t、int32_t
针对
Atlas 200I/500 A2 推理产品 :- A矩阵可设置为half、float、bfloat16_t 、int8_t
- B矩阵可设置为half、float、bfloat16_t 、int8_t
- Bias矩阵可设置为half、float、int32_t
- C矩阵可设置为half、float、bfloat16_t、int32_t
注意:除B矩阵为int8_t数据类型外,A矩阵和B矩阵数据类型需要一致,具体数据类型组合关系请参考表2。
ISTRANS
是否开启使能矩阵转置的功能。
- true为开启使能矩阵转置的功能,开启后,分别通过SetTensorA和SetTensorB中的isTransposeA、isTransposeB参数设置A、B矩阵是否转置。若设置A、B矩阵转置,Matmul会认为A矩阵形状为[K, M],B矩阵形状为[N, K]。
- false为不开启使能矩阵转置的功能,通过SetTensorA和SetTensorB不能设置A、B矩阵的转置情况。Matmul会认为A矩阵形状为[M, K],B矩阵形状为[K, N]。
默认为false不使能转置。
LAYOUT
表征数据的排布
NONE:默认值,表示不使用BatchMatmul;其他选项表示使用BatchMatmul。
NORMAL:BMNK的数据排布格式,具体可参考IterateBatch中对该数据排布的介绍。
BSNGD:原始BSH shape做reshape后的数据排布,具体可参考IterateBatch中对该数据排布的介绍。
SBNGD:原始SBH shape做reshape后的数据排布,具体可参考IterateBatch中对该数据排布的介绍。
BNGS1S2:一般为前两种数据排布进行矩阵乘的输出,S1S2数据连续存放,一个S1S2为一个batch的计算数据,具体可参考IterateBatch中对该数据排布的介绍。
IBSHARE
是否使能IBShare(IntraBlock Share)。IBShare的功能是能够复用L1 Buffer上相同的A矩阵或B矩阵数据。当A矩阵和B矩阵同时使能IBShare时,表示L1 Buffer上的A矩阵和B矩阵同时复用,此时只支持Norm模板(该场景的参数使用样例请参考matmulABshare样例)。
注意,A矩阵和B矩阵同时使能IBShare的场景,需要满足:
- 同一算子中其它Matmul对象的A矩阵和B矩阵也必须同时使能IBShare;
- 获取矩阵计算结果时,只支持调用IterateAll接口输出到GlobalTensor,即计算结果放置于Global Memory的地址,不能调用GetTensorC等接口。
除A、B矩阵同时复用的场景外,与IBShare模板配合使用,使用IBShare模板的要求是复用的矩阵必须在L1 Buffer上全载,具体参数设置详见表2。
表2 Matmul输入输出数据类型的组合说明 A矩阵
B矩阵
Bias
C矩阵
支持平台
float
float
float/half
float
Atlas A2 训练系列产品/Atlas 800I A2 推理产品 Atlas 200I/500 A2 推理产品
half
half
float
float
Atlas A2 训练系列产品/Atlas 800I A2 推理产品 Atlas 推理系列产品AI Core Atlas 200I/500 A2 推理产品
half
half
half
float
Atlas A2 训练系列产品/Atlas 800I A2 推理产品 Atlas 200I/500 A2 推理产品
int8_t
int8_t
int32_t
int32_t/half
Atlas A2 训练系列产品/Atlas 800I A2 推理产品 Atlas 推理系列产品AI Core Atlas 200I/500 A2 推理产品
int4b_t
int4b_t
int32_t
int32_t/half
Atlas A2 训练系列产品/Atlas 800I A2 推理产品
bfloat16_t
bfloat16_t
float
float
Atlas A2 训练系列产品/Atlas 800I A2 推理产品 Atlas 200I/500 A2 推理产品
bfloat16_t
bfloat16_t
half
float
Atlas A2 训练系列产品/Atlas 800I A2 推理产品
half
half
float
int8_t
Atlas A2 训练系列产品/Atlas 800I A2 推理产品
bfloat16_t
bfloat16_t
float
int8_t
Atlas A2 训练系列产品/Atlas 800I A2 推理产品
int8_t
int8_t
int32_t
int8_t
Atlas A2 训练系列产品/Atlas 800I A2 推理产品 Atlas 推理系列产品AI Core
half
half
float
half
Atlas A2 训练系列产品/Atlas 800I A2 推理产品 Atlas 推理系列产品AI Core Atlas 200I/500 A2 推理产品
half
half
half
half
Atlas A2 训练系列产品/Atlas 800I A2 推理产品 Atlas 200I/500 A2 推理产品
bfloat16_t
bfloat16_t
float
bfloat16_t
Atlas A2 训练系列产品/Atlas 800I A2 推理产品 Atlas 200I/500 A2 推理产品
half
int8_t
float
float
Atlas 推理系列产品AI Core
- 初始化操作。
1REGIST_MATMUL_OBJ(&pipe, GetSysWorkSpacePtr(), mm, &tiling); // 初始化matmul对象,参数含义请参考REGIST_MATMUL_OBJ章节
- 设置左矩阵A、右矩阵B、Bias。
1 2 3 4 5 6
mm.SetTensorA(gm_a); // 设置左矩阵A mm.SetTensorB(gm_b); // 设置右矩阵B mm.SetBias(gm_bias); // 设置Bias // Atlas 推理系列产品AI Core上需要额外调用SetLocalWorkspace接口设置计算所需的UB空间 mm.SetLocalWorkspace(usedUbBufLen);
- 完成矩阵乘操作。用户可以选择以下两种调用方式之一。
- 调用Iterate完成单次迭代计算,叠加while循环完成单核全量数据的计算。Iterate方式,可以自行控制迭代次数,完成所需数据量的计算,方式比较灵活。
1 2 3 4
// API接口内部会进行循环结束条件判断处理 while (mm.Iterate()) { mm.GetTensorC(gm_c); }
- 调用IterateAll完成单核上所有数据的计算。IterateAll方式,无需循环迭代,使用比较简单。
1mm.IterateAll(gm_c);
- 调用Iterate完成单次迭代计算,叠加while循环完成单核全量数据的计算。Iterate方式,可以自行控制迭代次数,完成所需数据量的计算,方式比较灵活。
- 结束矩阵乘操作。
1mm.End();
实现原理
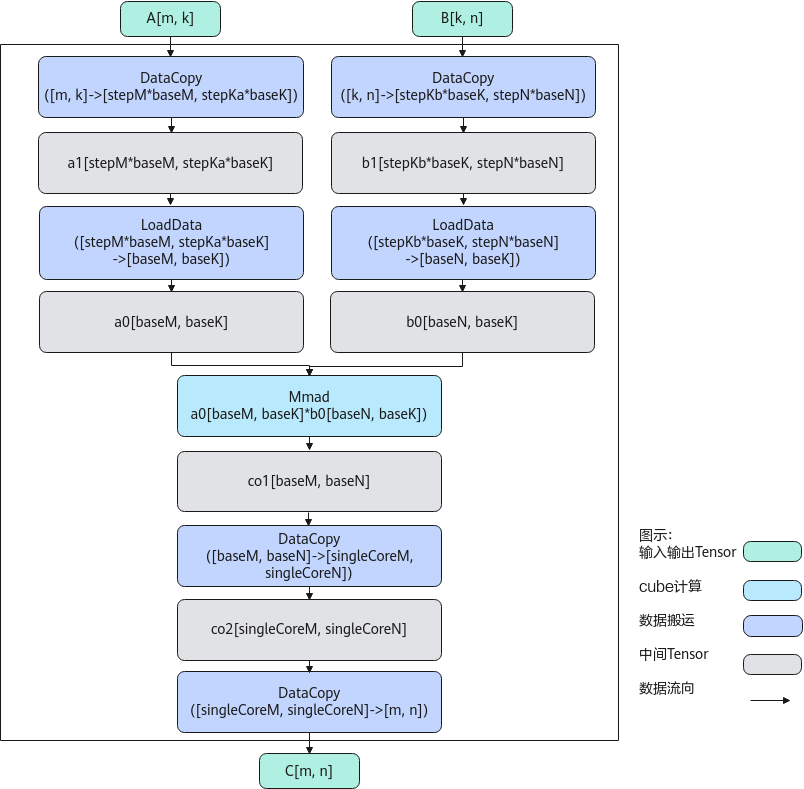
计算过程分为如下几步:
- 数据从GM搬到A1:DataCopy每次从矩阵A,搬出一个stepM*baseM*stepKa*baseK的矩阵块a1,循环多次完成矩阵A的搬运;数据从GM搬到B1:DataCopy每次从矩阵B,搬出一个stepKb*baseK*stepN*baseN的矩阵块b1,循环多次完成矩阵B的搬运;
- 数据从A1搬到A2:LoadData每次从矩阵块a1,搬出一个baseM * baseK的矩阵块a0;数据从B1搬到B2,并完成转置:LoadData每次从矩阵块b1,搬出一个baseK * baseN的矩阵块,并将其转置为baseN * baseK的矩阵块b0;
- 矩阵乘:每次完成一个矩阵块a0 * b0的计算,得到baseM * baseN的矩阵块co1;
- 数据从矩阵块co1搬到矩阵块co2: DataCopy每次搬运一块baseM * baseN的矩阵块co1到singleCoreM * singleCoreN的矩阵块co2中;
- 重复2-4步骤,完成矩阵块a1 * b1的计算;
- 数据从矩阵块co2搬到矩阵块C:DataCopy每次搬运一块singleCoreM * singleCoreN的矩阵块co2到矩阵块C中;
- 重复1-6步骤,完成矩阵A * B = C的计算。