接口概述
Ascend C算子采用标准C++语法和一组类库API进行编程,您可以根据自己的需求选择合适的API。Ascend C编程类库API示意图如下所示,Ascend C API的操作数都是Tensor类型:GlobalTensor和LocalTensor;类库API分为基础API和高阶API。
基础API:实现对硬件能力的抽象,开放芯片的能力,保证完备性和兼容性。
高阶API:实现一些常用的计算算法,用于提高编程开发效率,通常会调用多种基础API实现。高阶API包括数学库、Matmul、Softmax等API。
图1 Ascend C编程类库API示意图
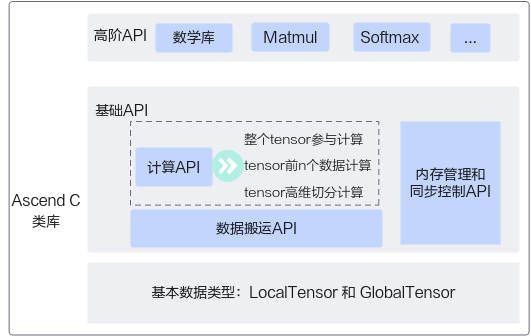
对于基础API,主要分为以下几类:
- 计算API,包括标量计算API、向量计算API、矩阵计算API,分别实现调用Scalar计算单元、Vector计算单元、Cube计算单元执行计算的功能。
- 数据搬运API,计算API基于Local Memory数据进行计算,所以数据需要先从Global Memory搬运至Local Memory,再使用计算API完成计算,最后从Local Memory搬出至Global Memory。执行搬运过程的接口称之为数据搬移API,比如DataCopy接口。
- 内存管理API,用于分配管理内存,比如AllocTensor、FreeTensor接口。
- 同步控制API,完成任务间的通信和同步,比如EnQue、DeQue接口。不同的API指令间有可能存在依赖关系,从AI Core内部并行计算架构抽象可知,不同的指令异步并行执行,为了保证不同指令队列间的指令按照正确的逻辑关系执行,需要向不同的组件发送同步指令。同步控制API内部即完成这个发送同步指令的过程,开发者无需关注内部实现逻辑,使用简单的API接口即可完成。
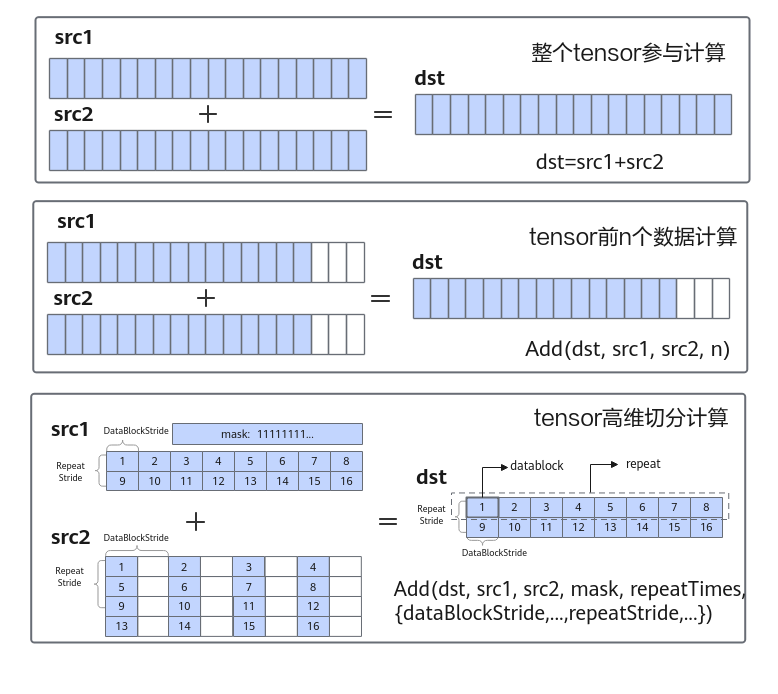
对于基础API中的计算API,根据对数据操作方法的不同,分为以下几种计算方式:
- 整个tensor参与计算:通过运算符重载的方式实现,支持+, -, *, /, |, &, <, >, <=, >=, ==, !=,实现计算的简化表达。例如:
dst=src1+src2
- tensor前n个数据计算:针对源操作数的连续n个数据进行计算并连续写入目的操作数,解决一维tensor的连续计算问题。例如:
Add(dst, src1, src2, n);
- tensor高维切分计算:功能灵活的计算API,充分发挥硬件优势,支持对每个操作数的DataBlock stride,Repeat stride,Mask等参数的操作。DataBlock stride,Repeat stride,Mask等参数的详细介绍请参见基础API通用说明。
下图以矢量加法为例,展示了几种计算方式的特点。
图2 计算API几种计算方式的特点

Ascend C API所在头文件目录为:
- 基础API:{install_path}/{arch-os}/tikcpp/tikcfw/interface
- 高阶API:(注意,如下目录头文件中包含的接口如果未在资料中声明,属于间接调用接口,开发者无需关注)
- {install_path}/{arch-os}/tikcpp/tikcfw/lib
- {install_path}/include/tiling
其中{install_path}表示CANN软件安装目录,{arch-os}为运行环境的架构和操作系统。
父主题: 通用概念和约束(必读)
