量化流程
量化示例请参见获取更多样例。量化感知训练支持量化的层以及约束如下:
|
支持的层类型 |
约束 |
|---|---|
|
InnerProduct:全连接层 |
transpose属性为false,axis为1 |
|
Convolution:卷积层 |
filter维度为4 |
|
Deconvolution:反卷积层 |
group为1、dilation为1、filter维度为4 |
|
Pooling:平均下采样层 |
下采样方式为AVE,且非global pooling |
接口调用流程
量化感知训练接口调用流程如图1所示。
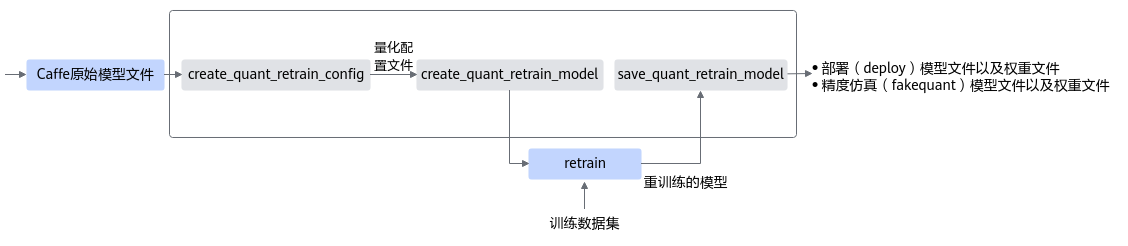
蓝色部分为用户实现,灰色部分为用户调用AMCT提供的API实现,用户在Caffe原始网络推理的代码中导入库,并在特定的位置调用相应API,即可实现量化功能:
- 用户首先构造Caffe的原始模型,然后使用create_quant_retrain_config生成量化配置文件。
- 调用create_quant_retrain_model接口对原始Caffe模型进行优化,修改后的模型中插入数据量化、权重量化等相关算子,用于计算量化相关参数;用户使用该模型借助AMCT提供的数据集和校准集,在Caffe环境中进行重训练,可以得到量化因子。
- 执行Caffe train流程,并配置solver,在训练过程中增加TEST过程,并配置TEST iteration数目大于量化配置文件中batch_num数目。
- 最后用户调用save_quant_retrain_model接口,插入AscendQuant、AscendDequant等量化算子,保存量化模型:包括可在Caffe环境中进行精度仿真的模型文件和权重文件,以及可部署在昇腾AI处理器的模型文件和权重文件。
调用示例

- 导入AMCT包,并通过环境变量设置日志级别。
1import amct_caffe as amct
- 设置设备运行模式。
AMCT支持CPU或GPU运行模式,若选择GPU模式,需要先设置Caffe的GPU运行设备模式,再设置AMCT的设备模式;另外因为此处已经指定了运行设备,模型推理函数中无需再次配置运行设备:
1 2 3 4 5 6
if 'gpu': caffe.set_mod_gpu() caffe.set_device(gpu_id) amct.set_gpu_mode() else: caffe.set_mode_cpu()
- (可选,由用户补充处理)使用原始待量化的模型和测试集,在Caffe环境下推理,验证环境、推理脚本是否正常。
推荐执行该步骤,请确保原始模型可以完成推理且精度正常;执行该步骤时,可以使用部分测试集,减少运行时间。
1user_test_model(ori_model_file, ori_weights_file, test_data, test_iterations)
- 调用AMCT,量化模型。
- 生成量化配置文件。
1 2 3 4
config_file = './tmp/config.json' amct_caffe.create_quant_retrain_config(config_file=config_file, model_file=ori_model_file, weights_file=ori_weights_file)
- 修改模型,插入伪量化层并存为新的模型文件。
根据量化配置文件对模型进行修改,插入数据量化、权重量化等相关算子,用于计算量化相关参数。
1 2 3 4 5 6 7 8 9
modified_model_file = './tmp/modified_model.prototxt' modified_weights_file = './tmp/modified_model.caffemodel' scale_offset_record_file = './tmp/record.txt' amct_caffe.create_quant_retrain_model(model_file=ori_model_file, weights_file=ori_weights_file, config_file=config_file, modified_model_file=modified_model_file, modified_weights_file=modified_weights_file, scale_offset_record_file=scale_offset_record_file)
- (由用户补充处理)使用修改后的模型,创建反向梯度,在训练集上做训练,训练量化因子。
- 在solver.prototxt中增加TEST phase(test_interval > 0,test_iter > 0),以触发在TEST phase中执行移位因子N的搜索动作,并且关闭预测test_initialization=false,避免误触发移位因子N的搜索计算。
test_iter: 1 test_interval: 4 base_lr: 9.999999747378752e-05 max_iter: 4 lr_policy: "step" gamma: 0.10000000149011612 momentum: 0.8999999761581421 weight_decay: 9.999999747378752e-05 stepsize: 10 snapshot: 4 net: "$HOME/amct_path/sample/resnet50/tmp/modified_model.prototxt" test_initialization: false
- test_iter:repeated参数,指定每次TEST执行的测试的迭代次数,由于移位因子N需要在该过程中执行,因此该数目需要大于等于移位因子N的参数batch_num,否则会由于数据不足,移位因子N计算失败。test_iter*batch_size为每次测试的图片数。
- test_interval:两次测试之间TEST的训练次数,每执行test_interval次训练迭代后会执行TEST过程,该参数默认为0,建议配置为max_iter的因子,sample中配置test_interval==max_iter,即仅完成训练后执行一次TEST。
- max_iter:训练最大迭代次数。
- net:训练使用的模型,Caffe支持配置一个net分别用于TRAIN,TEST(通过算子内phase来区 分不同模式需要执行的算子),也可以通过分别指定train_net,test_net来指定不同phase执行的模型;AMCT仅产生了一个模型,通过算子内部phase来区分不同模式,因子仅支持net,不支持配置train_net,test_net。
- test_initialization:是否要在训练之前执行原始模型的TEST,数据类型为bool型,默认为True,即执行一次预测试;若设置为True,初始化参数为0,计算出的移位因子N错误,因此需要关掉预测试, 即需要配置test_initialization = False。
- base_lr、lr_policy、gamma几个参数用于控制学习策略,即learning_rate如何变化。
- momentum:上一次梯度更新的权重。
- weight_decay:权重衰减项,防止过拟合的一个参数。
- snapshot:快照,将训练出来的model和solver状态进行保存,snapshot用于设置训练多少次后进行保存。
- 训练模型。
1user_train_model(modified_model_file, modified_weights_file, train_data)
训练过程中数据量化算子训练得到量化上下限clip_max, clip_min,保存到算子blob中,权重量化算子执行量化参数学习,并保存更新后的参数至模型中。
- 在solver.prototxt中增加TEST phase(test_interval > 0,test_iter > 0),以触发在TEST phase中执行移位因子N的搜索动作,并且关闭预测test_initialization=false,避免误触发移位因子N的搜索计算。
- 保存模型。
根据量化因子以及用户重训练好的模型,调用save_quant_retrain_model接口,插入AscendQuant、AscendDequant等算子,保存为deploy和fake-quant量化模型。
1 2 3 4 5 6 7
quant_model_path = './result/user_model' amct.save_quant_retrain_model(retrained_model_file=modified_model_file, retrained_weights_file=modified_weights_file, save_type='Both', save_path=quant_model_path, scale_offset_record_file=scale_offset_record_file, config_file=config_file)
- 生成量化配置文件。
- (可选,由用户补充处理)使用量化后模型fake_quant_model、fake_quant_weights和测试集,在Caffe环境下推理,测试量化后的仿真模型精度。使用量化后仿真模型精度与3中的原始精度做对比,可以观察量化对精度的影响。
1 2 3
fake_quant_model = './result/user_model_fake_quant_model.prototxt' fake_quant_weights = './result/user_model_fake_quant_weights.caffemodel' user_test_model(fake_quant_model, fake_quant_weights, test_data, test_iterations)
父主题: 量化感知训练