--precision_mode
功能说明
设置网络模型的精度模式。
关联参数
- 当取值为allow_mix_precision时,如果用户想要在内置优化策略基础上进行调整,自行指定哪些算子允许降精度,哪些算子不允许降精度,则需要参见--modify_mixlist参数设置。
- 推理场景下,使用--precision_mode参数设置整个网络模型的精度模式,可能会有个别算子存在性能或精度问题,该场景下可以使用--keep_dtype参数,使原始网络模型编译时保持个别算子的计算精度不变,但--precision_mode参数取值为must_keep_origin_dtype时,--keep_dtype不生效。
关联参数示意图如图1所示。
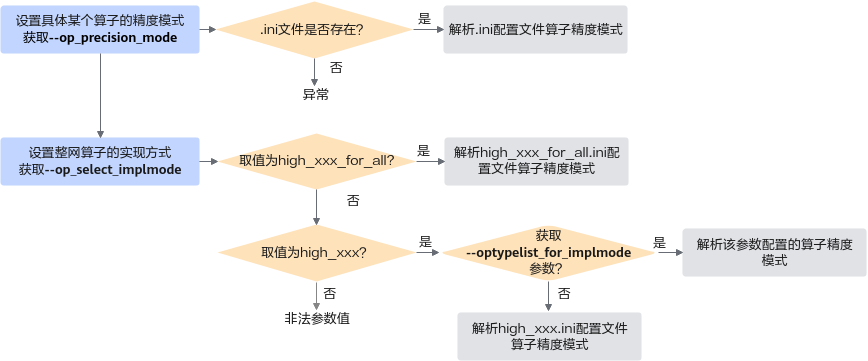
设置具体算子精度模式场景下:
- 首先读取--op_precision_mode参数,校验该参数的ini配置文件是否存在,若存在则解析文件并读取算子的精度模式,否则上报异常。
- --op_precision_mode不存在则读取--op_select_implmode参数:
- 首先检测是否配置为high_xxx_for_all参数,若是则解析high_xxx_for_all.ini文件并读取算子的精度模式。
- 若配置为high_xxx参数,则检测是否配置--optypelist_for_implmode参数,若是,则读取该参数配置的算子精度模式;否则解析high_xxx.ini文件并读取算子的精度模式。
参数取值
参数值:
- force_fp32/cube_fp16in_fp32out:
配置为force_fp32或cube_fp16in_fp32out,效果等同,系统内部都会根据矩阵类算子或矢量类算子,来选择不同的处理方式。cube_fp16in_fp32out为新版本中新增的,对于矩阵计算类算子,该选项语义更清晰。
- 对于矩阵计算类算子,系统内部会按算子实现的支持情况处理:
- 优先选择输入数据类型为float16且输出数据类型为float32;
- 如果1中的场景不支持,则选择输入数据类型为float32且输出数据类型为float32;
- 如果2中的场景不支持,则选择输入数据类型为float16且输出数据类型为float16;
- 如果3中的场景不支持,则报错。
- 对于矢量计算类算子,表示网络模型中算子支持float16和float32时,强制选择float32,若原图精度为float16,也会强制转为float32。
如果网络模型中存在部分算子,并且该算子实现不支持float32,比如某算子仅支持float16类型,则该参数不生效,仍然使用支持的float16;如果该算子不支持float32,且又配置了黑名单(precision_reduce = false),则会使用float32的AI CPU算子;如果AI CPU算子也不支持,则执行报错。
- 对于矩阵计算类算子,系统内部会按算子实现的支持情况处理:
- force_fp16:
表示网络模型中算子支持float16和float32时,强制选择float16。
- allow_fp32_to_fp16:
- 对于矩阵类算子,使用float16。
- 对于矢量类算子,优先保持原图精度,如果网络模型中算子支持float32,则保留原始精度float32,如果网络模型中算子不支持float32,则直接降低精度到float16。
- must_keep_origin_dtype:
保持原图精度。仅Atlas A2训练系列产品/Atlas 800I A2推理产品支持bfloat16类型。
- 如果原图中某算子精度为float16,AI Core中该算子的实现不支持float16、仅支持float32和bfloat16,则系统内部会自动采用高精度float32。
- 如果原图中某算子精度为float16,AI Core中该算子的实现不支持float16、仅支持bfloat16,则会使用float16的AI CPU算子;如果AI CPU算子也不支持,则执行报错。
- 如果原图中某算子精度为float32,AI Core中该算子的实现不支持float32类型、仅支持float16类型,则会使用float32的AI CPU算子;如果AI CPU算子也不支持,则执行报错。
- allow_mix_precision/allow_mix_precision_fp16:
配置为allow_mix_precision或allow_mix_precision_fp16,效果等同,均表示使用混合精度float16和float32数据类型来处理神经网络的过程。allow_mix_precision_fp16为新版本中新增的,语义更清晰,便于理解。
针对网络模型中float32数据类型的算子,按照内置的优化策略,自动将部分float32的算子降低精度到float16,从而在精度损失很小的情况下提升系统性能并减少内存使用。
若配置了该种模式,则可以在OPP软件包安装路径${INSTALL_DIR}/opp/built-in/op_impl/ai_core/tbe/config/<soc_version>/aic-<soc_version>-ops-info.json内置优化策略文件中查看“precision_reduce”参数的取值:
- 若取值为true(白名单),则表示允许将当前float32类型的算子,降低精度到float16。
- 若取值为false(黑名单),则不允许将当前float32类型的算子降低精度到float16,相应算子仍旧使用float32精度。
- 若网络模型中算子没有配置该参数(灰名单),当前算子的混合精度处理机制和前一个算子保持一致,即如果前一个算子支持降精度处理,当前算子也支持降精度;如果前一个算子不允许降精度,当前算子也不支持降精度。
- allow_mix_precision_bf16:仅Atlas A2训练系列产品/Atlas 800I A2推理产品场景支持此配置。
表示使用混合精度bfloat16和float32数据类型来处理神经网络的过程。针对原始模型中float32数据类型的算子,按照内置的优化策略,自动将部分float32的算子降低精度到bfloat16,从而在精度损失很小的情况下提升系统性能并减少内存使用;如果算子不支持bfloat16和float32,则使用AI CPU算子进行计算;如果AI CPU算子也不支持,则执行报错。
若配置了该种模式,则可以在OPP软件包安装路径${INSTALL_DIR}/opp/built-in/op_impl/ai_core/tbe/config/<soc_version>/aic-<soc_version>-ops-info.json内置优化策略文件中查看“precision_reduce”参数的取值:
- 若取值为true(白名单),则表示允许将当前float32类型的算子,降低精度到bfloat16。
- 若取值为false(黑名单),则不允许将当前float32类型的算子降低精度到bfloat16,相应算子仍旧使用float32精度。
- 若网络模型中算子没有配置该参数(灰名单),当前算子的混合精度处理机制和前一个算子保持一致,即如果前一个算子支持降精度处理,当前算子也支持降精度;如果前一个算子不允许降精度,当前算子也不支持降精度。
- allow_fp32_to_bf16:仅Atlas A2训练系列产品/Atlas 800I A2推理产品场景支持此配置。
- 对于矩阵计算类算子,使用bfloat16。
- 对于矢量计算类算子,优先保持原图精度,如果原始模型中算子支持float32,则保留原始精度float32;如果原始模型中算子不支持float32,则直接降低精度到bfloat16;如果算子不支持bfloat16和float32,则使用AI CPU算子进行计算;如果AI CPU算子也不支持,则执行报错。
参数默认值:force_fp16
推荐配置及收益
所配置的精度模式不同,网络模型精度以及性能有所不同,具体为:
精度高低排序:force_fp32>must_keep_origin_dtype>allow_fp32_to_fp16>allow_mix_precision>force_fp16
性能优劣排序:force_fp16>=allow_mix_precision>allow_fp32_to_fp16>must_keep_origin_dtype>force_fp32
示例
--precision_mode=force_fp16
支持的型号
Atlas 200/300/500 推理产品
Atlas 推理系列产品
Atlas 训练系列产品
Atlas 200I/500 A2推理产品
Atlas A2训练系列产品/Atlas 800I A2推理产品
依赖约束
无。