单算子调用流程
本节介绍调用单算子的两种方式、以及这两种方式下的接口调用流程。
开发应用时,如果涉及执行单个算子,请先参见AscendCL接口调用流程了解整体流程,再查看本节中的流程说明。
对于系统不支持的算子,用户需先参见《Ascend C算子开发指南》完成自定义算子开发。

单算子调用方式:单算子模型执行、单算子API执行
- 单算子API执行:基于C语言的API执行算子,无需提供IR(Intermediate Representation)定义,调用单算子API执行(当前版本不支持)下的算子接口,针对每个算子,都需要依次调用aclxxXxxGetWorkspaceSize接口获取算子执行需要的workspace内存大小、调用aclxxXxx接口执行算子。
- 单算子模型执行:基于图IR执行算子,先编译算子(例如,使用ATC工具将Ascend IR定义的单算子描述文件编译成算子om模型文件),再调用AscendCL接口加载算子模型(例如aclopSetModelDir接口),最后调用AscendCL接口执行算子(例如aclopExecuteV2接口)。
昇腾AI处理器对两种单算子调用方式的支持度如下表所示。
|
- |
单算子API执行 |
单算子模型执行 |
|---|---|---|
|
Atlas 200/300/500 推理产品 |
x |
√ |
|
Atlas 200I/500 A2推理产品 |
√(部分算子支持) |
√ |
|
Atlas 训练系列产品 |
√ |
√ |
|
Atlas A2训练系列产品/Atlas 800I A2推理产品 |
√ |
√ |
|
Atlas 推理系列产品 |
√(部分算子支持) |
√ |
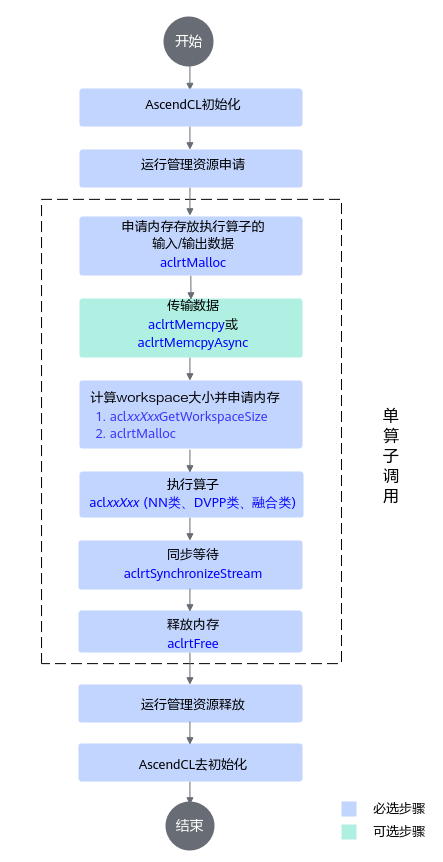
单算子API执行接口调用流程
-
依次申请运行管理资源,具体流程请参见运行管理资源申请与释放。
- 数据内存申请和传输。
- 调用aclrtMalloc接口申请Device上的内存,存放待执行算子的输入、输出数据。
- 调用aclCreateTensor、aclCreateIntArray等接口构造算子的输入、输出数据,如aclTensor、aclIntArray等,详细接口请参见公共接口。
如果需要将Host上数据传输到Device,则需要调用aclrtMemcpy接口(同步接口)或aclrtMemcpyAsync接口(异步接口)通过内存复制的方式实现数据传输。
- 计算workspace并执行算子。
- 调用aclrtSynchronizeStream接口阻塞应用运行,直到指定Stream中的所有任务都完成。
- 调用aclrtFree接口释放内存。
如果需要将Device上的算子执行结果数据传输到Host,则需要调用aclrtMemcpy接口(同步接口)或aclrtMemcpyAsync接口(异步接口)通过内存复制的方式实现数据传输,然后再释放内存。
- 运行管理资源释放。
- 调用aclDestroyTensor、aclDestroyIntArray等接口释放算子的输入、输出,相关接口请参见公共接口。
- 所有数据释放后,需要依次释放运行管理资源,具体流程请参见运行管理资源申请与释放。
- AscendCL去初始化。
单算子模型执行接口调用流程
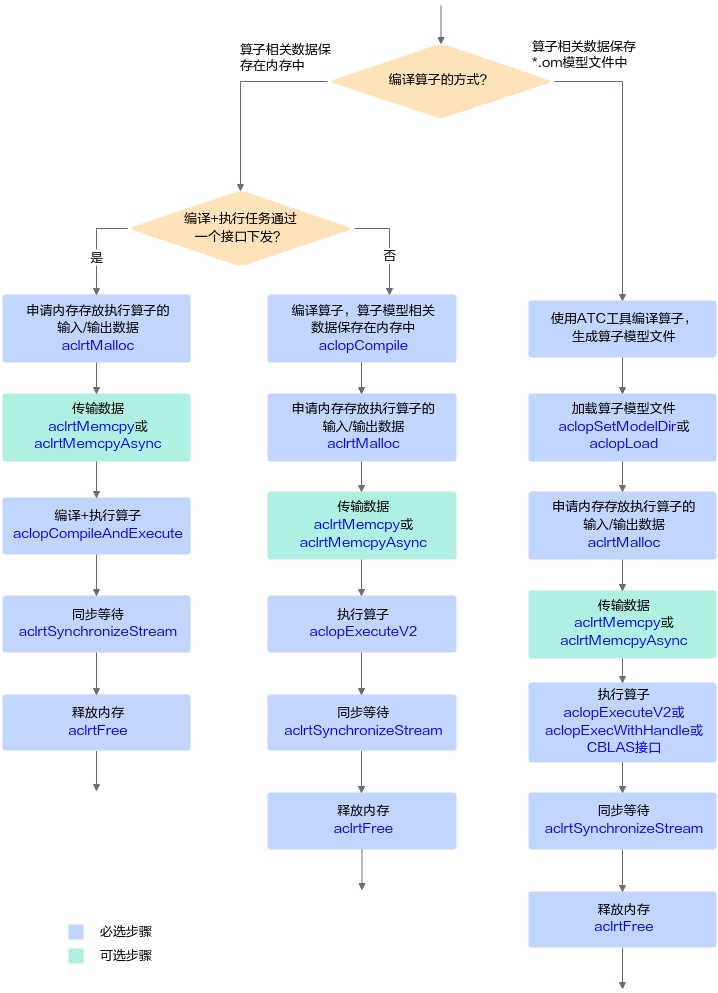
- 编译算子。
根据算子编译的方式,可分为以下两种:
- 加载算子模型文件。
- 调用aclrtMalloc接口申请Device上的内存,存放执行算子的输入、输出数据。
如果需要将Host上数据传输到Device,则需要调用aclrtMemcpy接口(同步接口)或aclrtMemcpyAsync接口(异步接口)通过内存复制的方式实现数据传输。
- 动态Shape场景,如果无法明确算子的输出Shape时,在执行算子前,还需推导或预估算子的输出Shape。
需用户调用aclopInferShape接口、aclGetTensorDescNumDims接口、aclGetTensorDescDimV2接口、aclGetTensorDescDimRange等接口,推导或预估算子的输出Shape,作为算子执行接口aclopExecuteV2的输入。
- 执行算子。
- 调用aclrtSynchronizeStream接口阻塞应用运行,直到指定Stream中的所有任务都完成。
- 调用aclrtFree接口释放内存。
如果需要将Device上的算子执行结果数据传输到Host,则需要调用aclrtMemcpy接口(同步接口)或aclrtMemcpyAsync接口(异步接口)通过内存复制的方式实现数据传输,然后再释放内存。