了解开发工程
为了更好的匹配开发者的多种开发调用场景,Ascend C提供如下两种算子工程对算子实现中的算子核心实现(host侧tiling实现、device侧kernel实现等)进行组织,开发者基于算子工程进行算子的开发和调用。
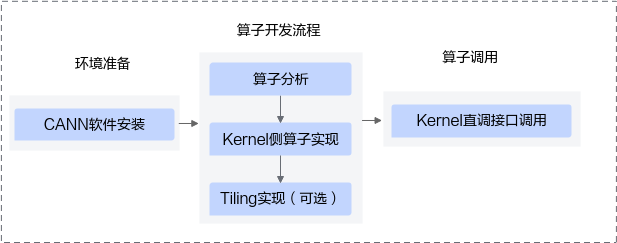
- Kernel直调工程:基于该工程,开发者完成算子核函数的开发和tiling实现后,即可通过AscendCL运行时接口,完成算子的调用。是简单直接的开发方式,tiling开发不受CANN框架的限制。
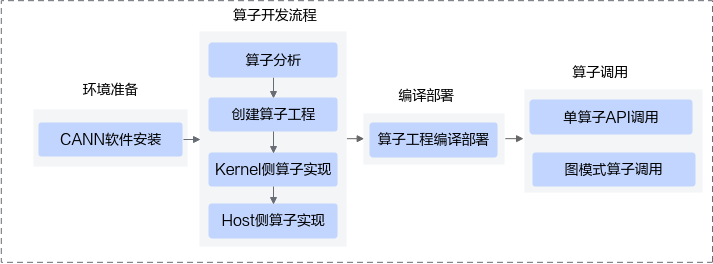
- 自定义算子工程:按照工程创建->算子实现->编译部署>算子调用的流程完成算子开发和调用。基于工程代码框架完成算子核函数的开发和tiling实现,通过工程编译脚本完成算子的编译部署。tiling开发基于CANN提供的编程框架进行,后续更易于借助框架功能实现单算子API调用、图模式算子调用等。
基于kernel直调工程的算子开发流程图如下:
基于自定义算子工程的算子开发流程图如下:
下面具体介绍两种开发工程的对比:主要的差异体现在算子的调用方式、开发过程和发布方式,其中自定义算子工程可以支持单算子API调用、图模式调用,而kernel直调工程只支持kernel直调接口调用。
差异点 |
自定义算子工程 |
Kernel直调工程 |
|
|---|---|---|---|
调用方式 |
单算子API执行(aclnn)调用 |
支持 |
不支持 |
图模式调用 |
支持 |
不支持 |
|
kernel直调接口调用 |
不支持 |
支持 |
|
开发过程 |
算子原型定义 |
需要 |
不需要 |
tiling实现 |
需要 |
可选 tiling开发不受CANN框架的限制。 |
|
shape、data type推导等入图所需函数实现 |
可选,入图需要 |
不需要 |
|
kernel侧算子实现 |
需要 |
需要 |
|
发布形式 |
.run包 |
.a/.so/bin |
|
调用方式对比
- 基于自定义算子工程开发的算子,支持多种调用方式,这里以单算子API(aclnn接口)调用为例:需要创建aclTensor,并调用两段式接口完成。
size_t workspace_size = 0; aclOpExecutor *handle; int32_t ret; int64_t shape_1[] = {1024, 1024}; void *data; aclTensor *tensors[3]; aclrtMalloc(&data, shape_1[0] * shape_1[1] * 2, ACL_MEM_MALLOC_HUGE_FIRST) tensors[0] = aclCreateTensor(shape_1, 2, ACL_FLOAT16, NULL, 0, ACL_FORMAT_ND, shape_1, 2, data); aclrtMalloc(&data, shape_1[0] * shape_1[1] * 2, ACL_MEM_MALLOC_HUGE_FIRST) tensors[1] = aclCreateTensor(shape_1, 2, ACL_FLOAT16, NULL, 0, ACL_FORMAT_ND, shape_1, 2, data); aclrtMalloc(&data, shape_1[0] * shape_1[1] * 2, ACL_MEM_MALLOC_HUGE_FIRST) tensors[2] = aclCreateTensor(shape_1, 2, ACL_FLOAT16, NULL, 0, ACL_FORMAT_ND, shape_1, 2, data); // 两段式接口:1、获取workspace大小 ret = aclnnMyAddGetWorkspaceSize(tensors[0], tensors[1], tensors[2], &workspace_size, &handle); void *workspace = NULL; if (workspace_size != 0) { if (aclrtMalloc(&workspace, workspace_size, ACL_MEM_MALLOC_HUGE_FIRST) != ACL_SUCCESS) { printf("Malloc device memory failed\n"); } } // 两段式接口:2、执行算子 ret = aclnnMyAdd(workspace, workspace_size, handle, stream); if (aclrtSynchronizeStreamWithTimeout(stream, 5000) != ACL_SUCCESS) { printf("Synchronize stream failed\n"); } - Kernel直调工程开发的算子,支持直接使用device指针进行kernel调用。
int64_t shape_1[] = {1024, 1024}; void *data[3]; aclrtMalloc(&data[0], shape_1[0] * shape_1[1] * 2, ACL_MEM_MALLOC_HUGE_FIRST); aclrtMalloc(&data[1], shape_1[0] * shape_1[1] * 2, ACL_MEM_MALLOC_HUGE_FIRST); aclrtMalloc(&data[2], shape_1[0] * shape_1[1] * 2, ACL_MEM_MALLOC_HUGE_FIRST); // kernel调用 ACLRT_LAUNCH_KERNEL(my_add)(blockDim, stream, data[0], data[1], data[2]); if (aclrtSynchronizeStreamWithTimeout(stream, 5000) != ACL_SUCCESS) { printf("Synchronize stream failed\n"); }
开发过程对比
自定义算子工程含分离的host/kernel开发目录,以及整体编译入口脚本、代码生成、打包脚本等,kernel直调工程只有一个CMakeLists入口和kernel源码、测试代码目录。
- 自定义算子工程
AddCustom ├── build.sh // 编译入口脚本 ├── cmake ├── CMakeLists.txt // 算子工程的CMakeLists.txt ├── CMakePresets.json // 编译配置项 ├── op_host // host侧实现文件 │ ├── add_custom_tiling.h // 算子tiling定义文件 │ ├── add_custom.cpp // 算子原型注册、shape推导、信息库、tiling实现等内容文件 │ ├── CMakeLists.txt ├── op_kernel // kernel侧实现文件 │ ├── CMakeLists.txt │ ├── add_custom.cpp // 算子代码实现文件 └── scripts // 自定义算子工程打包相关脚本所在目录
- Kernel直调工程
|-- cmake // CMake编译文件 |-- CMakeLists.txt // CMake编译配置文件 |-- my_add.cpp // kernel实现 |-- main.cpp // 测试程序调用kernel直调入口
自定义算子工程需要完整开发算子的实现文件,如算子原型定义、tiling函数、shape及data type推导函数(可选,入图时需要)、kernel函数;kernel直调工程只需要开发kernel函数。
代码文件 |
自定义算子工程 |
Kernel直调工程 |
|---|---|---|
算子原型定义 |
需要 |
不需要 |
tiling实现 |
需要 |
可选 tiling开发不受CANN框架的限制。 |
shape、data type推导等入图所需函数实现 |
可选,入图需要 |
不需要 |
kernel侧算子实现 |
需要 |
需要 |
发布形式
自定义算子工程当前以run包形式发布,内部包含了tiling函数库、入图接口库、aclnn库、device object等;kernel直调工程则最终只发布成静态库、动态库、可执行程序形式。