分解流程
本节给出张量分解的接口调用流程和调用示例。
接口调用流程
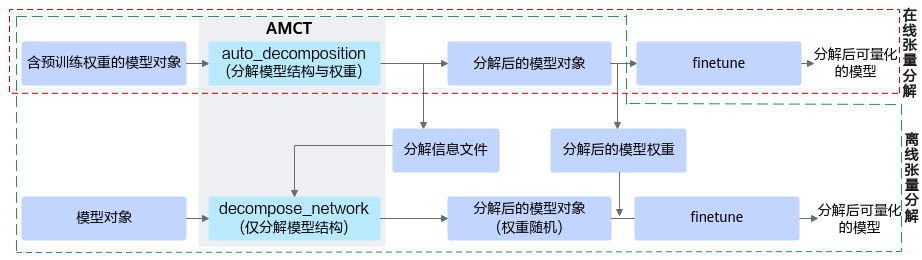
- 在线分解流程
在训练脚本中,准备好含有预训练权重的torch.nn.Module模型对象,在将模型参数传递给优化器之前,将模型对象传递给auto_decomposition接口进行张量分解,得到分解后的模型对象,即可直接对其进行finetune。
- 离线分解流程
- 在任意脚本中,准备好含有预训练权重的torch.nn.Module模型对象,将模型对象和分解信息文件保存路径传递给auto_decomposition接口进行张量分解,得到分解后的模型对象和保存的分解信息文件,并对分解后的模型权重进行保存。
- finetune时,在训练脚本中,在将模型参数传递给优化器之前,将模型对象和2.a中得到的分解信息文件路径传递给decompose_network接口,该接口会将模型结构修改为分解后的结构,然后加载2.a保存的分解后的模型权重,对模型进行finetune。

离线分解时,2.a步骤在调用auto_decomposition接口后,用户需要自行保存分解后模型权重;2.b步骤在调用完成decompose_network后,用户需自行加载所保存的分解后的模型权重。
此方案设计目的是方便用户自由控制权重文件的存取,例如在权重文件中存储自定义信息。
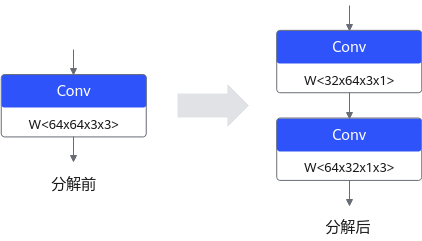
张量分解后会将1个卷积分解为2个串联的卷积,模型的其中一层卷积分解前后情况如图2所示。
调用示例
以下示例中,(*)表示用户已有的代码,...表示用户已有代码的省略,此处仅为示例,实际用户代码可能不同,请根据实际情况进行调整。
- 在线张量分解
在训练脚本中,调用auto_decomposition分解含有预训练权重的PyTorch模型,然后直接finetune。
1 2 3 4 5 6
from amct_pytorch.tensor_decompose import auto_decomposition net = Net() # (*) 构建模型对象 net.load_state_dict(torch.load("src_path/net.pth")) # (*) 加载模型权重 net, changes = auto_decomposition(model=net) # 执行张量分解 optimizer = build_optimizer(net, ...) # (*) 构建优化器(将模型参数传递给优化器) train(net, optimizer, ...) # (*) finetune
- 离线张量分解
- 在任意脚本中,调用auto_decomposition分解含有预训练权重的PyTorch模型,保存分解信息文件和分解后的模型权重。
1 2 3 4 5 6 7 8
from amct_pytorch.tensor_decompose import auto_decomposition net = Net() # (*) 构建模型对象 net.load_state_dict(torch.load("src_path/weights.pth")) # (*) 加载模型权重 net, changes = auto_decomposition( # 执行张量分解,并保存分解信息文件 model=net, decompose_info_path="decomposed_path/decompose_info.json" # 分解信息文件保存路径 ) torch.save(net.state_dict(), "decomposed_path/decomposed_weights.pth") # 保存分解后的模型权重
- 在训练脚本中,调用decompose_network,根据2.a得到的分解信息文件将模型结构修改为分解后的结构,再加载2.a保存的分解后的模型权重,进行finetune。
1 2 3 4 5 6 7 8 9
from amct_pytorch.tensor_decompose import decompose_network net = Net() # (*) 构建用户模型对象 net, changes = decompose_network( # 加载分解信息文件,将模型结构修改为张量分解后的结构 model=net, decompose_info_path="decomposed_path/decompose_info.json" # 上一步保存的分解信息文件路径 ) net.load_state_dict(torch.load("decomposed_path/decomposed_weights.pth")) # 加载上一步保存的分解后模型权重 optimizer = build_optimizer(net, ...) # (*) 构建优化器(将模型参数传递给优化器) train(net, optimizer, ...) # (*) finetune
- 在任意脚本中,调用auto_decomposition分解含有预训练权重的PyTorch模型,保存分解信息文件和分解后的模型权重。
父主题: 张量分解