样例介绍
功能描述
该样例主要实现矩阵-矩阵相乘的运算:C = αAB + βC,A、B、C都是16*16的矩阵,即:m=16,n=16,k=16。矩阵乘的结果是一个16*16的矩阵。
图1 Sample示例
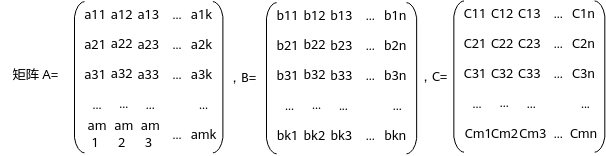
原理介绍
在该样例中,涉及的关键功能点,如下表所示。
初始化 |
|
|---|---|
Device管理 |
|
Stream管理 |
|
内存管理 |
|
数据传输 |
如果在Host上运行应用,则需调用aclrtMemcpy接口:
如果在板端环境上运行应用,则无需进行数据传输。 |
单算子调用 |
|
目录结构
样例代码结构如下所示。
├── inc
│ ├── common.h //定义公共函数(例如:文件读取函数)的头文件
│ ├── gemm_runner.h //定义矩阵乘运算相关函数的头文件
├── run
│ ├── out
│ │ ├──test_data
│ │ │ ├── config
│ │ │ │ ├── acl.json //系统初始化的配置文件
│ │ │ │ ├── gemm.json //矩阵乘算子的算子描述信息
│ │ │ ├── data
│ │ │ │ ├── generate_data.py //用于生成矩阵A、矩阵B的数据
├── src
│ ├── CMakeLists.txt //编译脚本
│ ├── common.cpp //公共函数(例如:文件读取函数)的实现文件
│ ├── gemm_main.cpp //主函数的实现文件
│ ├── gemm_runner.cpp //执行矩阵乘运算相关函数的实现文件
父主题: 实现矩阵-矩阵乘运算