快速入门
本章节指导用户基于mxRec为用户提供的little-demo样例,快速理解一个使用TF.Session进行模型训练需要准备的相关文件和关键接口适配。little-demo仅是一个代码示例,并介绍了调用相关接口的逻辑,不包含具体的模型,没有实现具体的功能。
little-demo仅作参考学习,不支持在little-demo上适配用户自己的模型。little-demo存放路径为:链接。

如无权限获取代码,请联系华为技术支持申请加入“Ascend”组织。
在train_and_evaluate场景下不支持多轮eval。
文件名 |
说明 |
|---|---|
config.py |
模型相关配置。 |
dataset.py |
数据集预处理。 |
main.py |
模型训练入口。 |
model.py |
模型搭建。 |
op_impl_mode.ini |
算子配置文件。 |
optimizer.py |
优化器。 |
random_data_generator.py |
数据集随机生成。 |
run.sh |
模型训练启动脚本。 |
run_model.py |
训练、推理流程封装。 |
hccl_json_1p.json |
使用通过配置文件设置资源信息的方式启动训练任务(单卡配置样例)。 |
hccl_json_4p.json |
使用通过配置文件设置资源信息的方式启动训练任务(四卡配置样例)。 |
hccl_json_8p.json |
使用通过配置文件设置资源信息的方式启动训练任务。 |
接口调用介绍
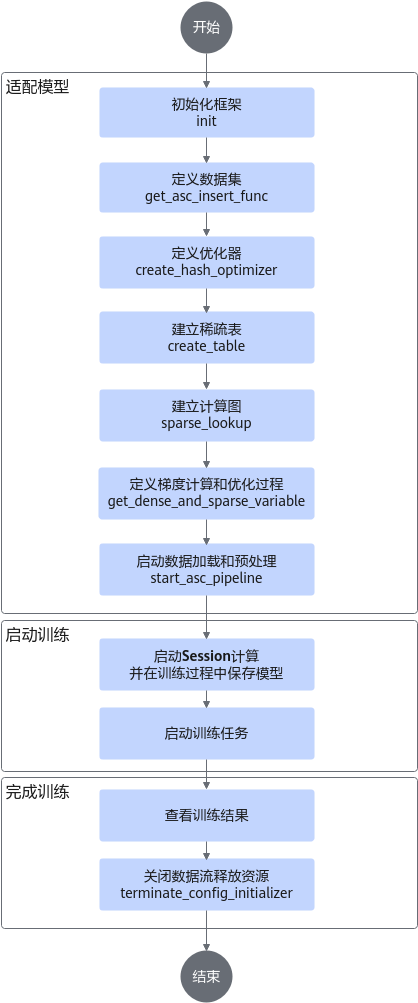
- 初始化框架。在main.py中调用init接口,传入初始化框架需要的相关参数。相关参数请参见参数说明。
# nbatch function needs to be used together with the prefetch and host_vocabulary_size != 0 init(use_mpi=use_mpi, train_steps=TRAIN_steps, eval_steps=EVAL_STEPS, use_dynamic=use_dynamic, use_hot=use_hot, use_dynamic_expansion=use_dynamic_expansion) - 定义数据集。在main.py中调用get_asc_insert_func接口,创建数据集并对数据集进行预处理。相关参数请参见参数说明。
if not MODIFY_GRAPH_FLAG: insert_fn = get_asc_insert_func(tgt_key_specs=feature_spec_list, is_training=is_training, dump_graph=dump_graph) dataset = dataset.map(insert_fn) dataset = dataset.prefetch(100) iterator = dataset.make_initializable_iterator() batch = iterator.get_next() return batch, iterator - 定义优化器。在optimizer.py中定义优化器,支持的优化器类型和相关参数请参见优化器。
# coding: UTF-8 import logging import tensorflow as tf from mx_rec.optimizers.lazy_adam import create_hash_optimizer from mx_rec.optimizers.lazy_adam_by_addr import create_hash_optimizer_by_address from mx_rec.util.initialize import get_use_dynamic_expansion def get_dense_and_sparse_optimizer(cfg): dense_optimizer = tf.compat.v1.train.AdamOptimizer(learning_rate=cfg.learning_rate) use_dynamic_expansion = get_use_dynamic_expansion() if use_dynamic_expansion: sparse_optimizer = create_hash_optimizer_by_address(learning_rate=cfg.learning_rate) logging.info("optimizer lazy_adam_by_addr") else: sparse_optimizer = create_hash_optimizer(learning_rate=cfg.learning_rate) logging.info("optimizer lazy_adam") return dense_optimizer, sparse_optimizer - 建立稀疏表。在main.py中调用create_table接口,建立稀疏表,创建稀疏网络层。相关参数请参见参数说明。
sparse_optimizer_list = [sparse_optimizer for dense_optimizer, sparse_optimizer in optimizer_list] user_hashtable = create_table(key_dtype=tf.int64, dim=tf.TensorShape([cfg.user_hashtable_dim]), name='user_table', emb_initializer=tf.compat.v1.truncated_normal_initializer(), device_vocabulary_size=cfg.user_vocab_size * 10, host_vocabulary_size=0, # cfg.user_vocab_size * 100, # for h2d test optimizer_list=sparse_optimizer_list) item_hashtable = create_table(key_dtype=tf.int64, dim=tf.TensorShape([cfg.item_hashtable_dim]), name='item_table', emb_initializer=tf.compat.v1.truncated_normal_initializer(), device_vocabulary_size=cfg.item_vocab_size * 10, host_vocabulary_size=0, # cfg.user_vocab_size * 100, # for h2d test optimizer_list=sparse_optimizer_list) - 建立计算图。传入稀疏网络层和特征列表,创建模型计算图,在计算图中调用sparse_lookup进行特征查询和误差计算。相关参数请参见参数说明。
def model_forward(input_list, batch, is_train, modify_graph, config_dict=None): embedding_list = [] feature_list, hash_table_list, send_count_list = input_list for feature, hash_table, send_count in zip(feature_list, hash_table_list, send_count_list): access_and_evict_config = None if isinstance(config_dict, dict): access_and_evict_config = config_dict.get(hash_table.table_name) embedding = sparse_lookup(hash_table, feature, send_count, is_train=is_train, access_and_evict_config=access_and_evict_config, name=hash_table.table_name + "_lookup", modify_graph=modify_graph, batch=batch) reduced_embedding = tf.reduce_sum(embedding, axis=1, keepdims=False) embedding_list.append(reduced_embedding) my_model = MyModel() my_model(embedding_list, batch["label_0"], batch["label_1"]) return my_model - 定义梯度计算和优化过程。在main.py中调用get_dense_and_sparse_variable接口,得到密集网络层和稀疏网络层的参数,通过优化器计算梯度并执行优化。接口说明请参见get_dense_and_sparse_variable。
train_iterator, train_model = build_graph([user_hashtable, item_hashtable], is_train=True, feature_spec_list=train_feature_spec_list, config_dict=ACCESS_AND_EVICT, batch_number=cfg.batch_number) eval_iterator, eval_model = build_graph([user_hashtable, item_hashtable], is_train=False, feature_spec_list=eval_feature_spec_list, config_dict=ACCESS_AND_EVICT, batch_number=cfg.batch_number) dense_variables, sparse_variables = get_dense_and_sparse_variable() - 启动数据加载和预处理。在main.py中调用modify_graph_and_start_emb_cache(改图模式)/start_asc_pipeline(非改图模式)接口,启动数据流水线(示例代码中使用if判断配置文件中的MODIFY_GRAPH_FLAG来控制是否使用改图模式)。接口说明请参见modify_graph_and_start_emb_cache。
saver = tf.compat.v1.train.Saver() if MODIFY_GRAPH_FLAG: logging.info("start to modifying graph") modify_graph_and_start_emb_cache(dump_graph=True) else: start_asc_pipeline() with tf.compat.v1.Session(config=sess_config(dump_data=False)) as sess: if MODIFY_GRAPH_FLAG: sess.run(get_initializer(True)) else: sess.run(train_iterator.initializer) sess.run(tf.compat.v1.global_variables_initializer()) EPOCH = 0 if os.path.exists(f"./saved-model/sparse-model-{rank_id}-%d" % 0): saver.restore(sess, f"./saved-model/model-{rank_id}-%d" % 0) else: saver.save(sess, f"./saved-model/model-{rank_id}", global_step=0) for i in range(1, 201): logging.info(f"################ training at step {i} ################") try: sess.run([train_ops, train_model.loss_list]) except tf.errors.OutOfRangeError: logging.info(f"Encounter the end of Sequence for training.") break else: if i % TRAIN_INTERVAL == 0: EPOCH += 1 evaluate() if i % SAVING_INTERVAL == 0: saver.save(sess, f"./saved-model/model-{rank_id}", global_step=i) saver.save(sess, f"./saved-model/model-{rank_id}", global_step=i) - 启动Session计算并在训练过程中保存模型。在main.py中调用saver接口,启动Session计算并在训练过程中保存模型。
saver = tf.compat.v1.train.Saver() if MODIFY_GRAPH_FLAG: logging.info("start to modifying graph") modify_graph_and_start_emb_cache(dump_graph=True) else: start_asc_pipeline() with tf.compat.v1.Session(config=sess_config(dump_data=False)) as sess: if MODIFY_GRAPH_FLAG: sess.run(get_initializer(True)) else: sess.run(train_iterator.initializer) sess.run(tf.compat.v1.global_variables_initializer()) EPOCH = 0 if os.path.exists(f"./saved-model/sparse-model-{rank_id}-%d" % 0): saver.restore(sess, f"./saved-model/model-{rank_id}-%d" % 0) else: saver.save(sess, f"./saved-model/model-{rank_id}", global_step=0) for i in range(1, 201): logging.info(f"################ training at step {i} ################") try: sess.run([train_ops, train_model.loss_list]) except tf.errors.OutOfRangeError: logging.info(f"Encounter the end of Sequence for training.") break else: if i % TRAIN_INTERVAL == 0: EPOCH += 1 evaluate() if i % SAVING_INTERVAL == 0: saver.save(sess, f"./saved-model/model-{rank_id}", global_step=i) saver.save(sess, f"./saved-model/model-{rank_id}", global_step=i) - 关闭数据流释放资源。在main.py中调用terminate_config_initializer,关闭数据流释放资源。接口说明请参见terminate_config_initializer。
terminate_config_initializer() logging.info("Demo done!")
启动模型训练
通过配置文件设置资源信息(rank table方案),启动训练任务。
- 使用以下命令查看NPU芯片信息,其中{ASCEND_DRIVER_PATH}代表驱动安装路径,{device_id}代表查看NPU加速卡ID,在单机单卡任务中通常使用0号卡,在单机多卡任务中需要依次执行查看NPU的ip地址,命令参考如下。
{ASCEND_DRIVER_PATH}/tools/hccn_tool -i {device_id} -ip -g查询命令返回结果中“ipaddr”即为NPU卡对应的ip地址{device_ip}。
- 编写“hccl_json_8p.json”文件,根据上一步骤中获取的{device_ip}对“hccl_json_8p.json”文件进行配置,并保存。
单机多卡配置样例参考如下,其中{device_ip}和{host_ip}需要根据真实环境配置进行替换,若执行单机单卡则只需在“device”中配置一项。
{ "server_count":"1", "server_list":[ { "device":[ { "device_id":"0", "device_ip":"{device_0_ip}", "rank_id":"0" }, { "device_id":"1", "device_ip":"{device_1_ip}", "rank_id":"1" }, { "device_id":"2", "device_ip":"{device_2_ip}", "rank_id":"2" }, { "device_id":"3", "device_ip":"{device_3_ip}", "rank_id":"3" }, { "device_id":"4", "device_ip":"{device_4_ip}", "rank_id":"4" }, { "device_id":"5", "device_ip":"{device_5_ip}", "rank_id":"5" }, { "device_id":"6", "device_ip":"{device_6_ip}", "rank_id":"6" }, { "device_id":"7", "device_ip":"{device_7_ip}", "rank_id":"7" } ], "server_id":"{host_ip}" } ], "status":"completed", "version":"1.0" }单机单卡配置样例参考如下。
{ "server_count":"1", "server_list":[ { "device":[ { "device_id":"0", "device_ip":"{device_0_ip}", "rank_id":"0" } ], "server_id":"{host_ip}" } ], "status":"completed", "version":"1.0" } - 执行如下命令,启动训练任务。
bash run.sh main.py
正常开始执行,打印信息参考如下。
The ranktable solution RANK_TABLE_FILE=“/xxx/example/little_demo/hccl_json_8p.json” py is main.py use horovod to start tasks ...执行完成,日志信息显示参考如下。
ASC manager has been destroyed. MPI has been destroyed. Demo done!
父主题: 模型训练