模型迁移分析
以Hugging Face的LLaMA模型为例,简单介绍模型结构以及如何迁移模型,使用Ascend Transformer Boost加速库推理接口,具体代码解析如下。
- Hugging Face的模型结构定义在“${transformers_package}/models/${model_name}/modeling_${model_name}.py”,生成LLaMA模型的generate接口实际调用的是“${transformers_package}/generation/utils.py”的generatate接口,整体流程如下,此处以greedy_search后处理为例:
# 以greedy_search后处理为例 def greedy_search(...) -> Union[GreedySearchOutput, torch.LongTensor] # 初始化参数: 前置会生成attention_mask ... # 核心推理流程 while True: ... # prepare model inputs # 数据前处理过程: 生成postion_ids model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs) # 核心推理流程 outputs = self( **model_inputs, return_dict=True, output_attentions=output_attentions, output_hidden_states=output_hidden_states, ) ... # 后处理search过程 next_token_logits = outputs.logits[:, -1, :] next_tokens_scores = logits_processor(input_ids, next_token_logits) next_tokens = torch.argmax(next_tokens_scores, dim=-1) ... - 核心推理过程如下,调用对应的model.forward接口,即“${transformers_package}/models/${model_name}/modeling_${model_name}.py”,以核心类LlamaModel类为例。
def forward(...) -> Union[Tuple, BaseModelOutputWithPast]: # 更新模型输入:input_embedding/attetion_mask/position_ids output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions output_hidden_states = ( output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states ) ... if inputs_embeds is None: inputs_embeds = self.embed_tokens(input_ids) # 生成embedding数据 ... # 模型推理流程 for idx, decoder_layer in enumerate(self.layers): ... if self.gradient_checkpointing and self.training: ... else: # 多层Transformer Block推理流程 layer_outputs = decoder_layer( hidden_states, attention_mask=attention_mask, position_ids=position_ids, past_key_value=past_key_value, output_attentions=output_attentions, use_cache=use_cache, ) ... # 多层Transformer Block推理后的Normalization hidden_states = self.norm(hidden_states) ... # 返回输出后,最后还会经过lm_head层 return BaseModelOutputWithPast( last_hidden_state=hidden_states, past_key_values=next_cache, hidden_states=all_hidden_states, attentions=all_self_attns, ) - 具体的decoder_layer层结构定义如下:
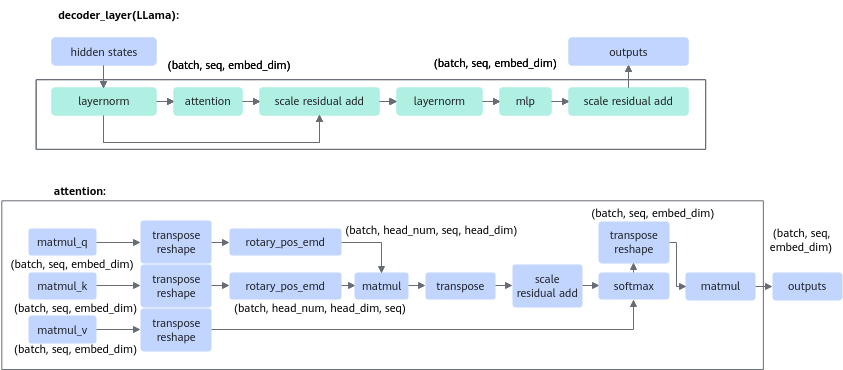
# decoder layer定义 class LlamaDecoderLayer(nn.Module): .... def forward(...) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]: residual = hidden_states hidden_states = self.input_layernorm(hidden_states) # Self Attention: 定义在LlamaAttention hidden_states, self_attn_weights, present_key_value = self.self_attn( hidden_states=hidden_states, attention_mask=attention_mask, position_ids=position_ids, past_key_value=past_key_value, output_attentions=output_attentions, use_cache=use_cache, ) hidden_states = residual + hidden_states # Fully Connected residual = hidden_states hidden_states = self.post_attention_layernorm(hidden_states) hidden_states = self.mlp(hidden_states) hidden_states = residual + hidden_states # self_attention定义 class LlamaAttention(nn.Module): ... def forward(...) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]: bsz, q_len, _ = hidden_states.size() query_states = self.q_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2) key_states = self.k_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2) value_states = self.v_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2) kv_seq_len = key_states.shape[-2] if past_key_value is not None: kv_seq_len += past_key_value[0].shape[-2] cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len) query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids) ... attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim) ... # upcast attention to fp32 attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype) attn_output = torch.matmul(attn_weights, value_states) ... attn_output = attn_output.transpose(1, 2) attn_output = attn_output.reshape(bsz, q_len, self.hidden_size) attn_output = self.o_proj(attn_output) ... - 基于原始PyTorch代码可以梳理得到对应模型结构和算子输入输出shape,最终得到整体计算图结构。以LLaMA的decoder_layer结构为例。
加速库适配需要基于加速库算子和构图接口构建与原始计算图等价的加速库图,实现基于加速库的快速推理。
如图1所示,decoder_layer对应加速库的Layer层级,而Layer中的子元素对应加速库的Operation层级,可以看到Operation也是由不同Kernel级别的基础算子组成的(如attention Op)。
- 基于模型计算图结构,可匹配加速库已支持的模型,具体请参见加速库支持模型列表。
父主题: 大模型迁移适配
