北向接口实现方式
实现方式
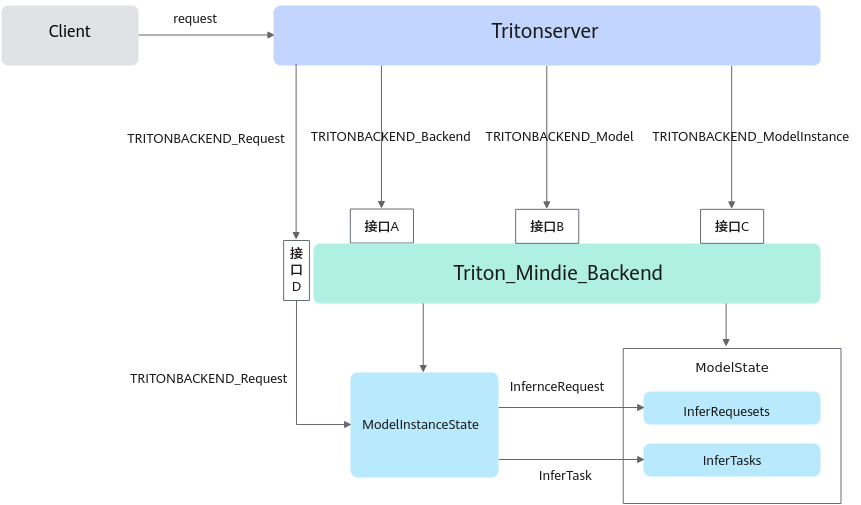
北向实现方式如图1所示,分别设计了四个核心接口A、B、C、D。接口A、B和C负责对Tritonserver传递给Backend的后端、模型和模型实例进行初始化并创建ModelState和ModelInstanceState这两个状态类,如表1所示。接口D将Triton侧请求发送给ModelInstanceState,在其内部转化为MindIE侧的请求和推理任务。最后发送给ModelState并添加进存储队列中,以供MindIE接口循环调用。
除了上述四个核心接口,还设计了两个接口B~和C~用于清除Model和ModelInstance中的状态类。
状态类 |
说明 |
|---|---|
ModelState |
ModelState继承自BackendModel,承接了TRITONBACKEND_Model中的全部模型配置信息(如模型名、模型版本、模型仓路径和最大批处理量等),最后依附在TRITONBACKEND_Model上。ModelState中还包含了两个关键存储队列,一个是请求队列,另一个是推理任务队列,以供MindIE LLM接口循环调用。 |
ModelInstanceState |
ModelInstanceState继承自BackendModelInstance,承接了TRITONBACKEND_ModelInstacne中的全部模型实例配置信息(如实例ID、CPU/GPU类型和硬件ID),最后依附在TRITONBACKEND_ModelInstacne上。ModelInstanceState中定义了Enqueue成员函数,用来接收Triton侧请求并转化为MindIE侧请求InferRequest,同时生成推理任务inferTask,最后一同写入ModelState内队列中。 |
接口描述
参数 |
描述 |
|---|---|
接口函数 |
TRITONSERVER_Error* TRITONBACKEND_Initialize(TRITONBACKEND_Backend* backend)。 |
接口功能 |
Triton传入的backend支持的API版本号与mindie_backend进行校验。 |
输入参数 |
Tritonserver侧的backend类指针。 |
输出参数 |
执行结果状态。 |
参数 |
描述 |
|---|---|
接口函数 |
TRITONSERVER_Error* TRITONBACKEND_ModelInitialize(TRITONBACKEND_Model* model)。 |
接口功能 |
创建一个ModelState并初始化,并将其依附在TRITONBACKEND_Model上。承接了TRITONBACKEND_Model中的全部模型配置信息(如模型名、模型版本、模型仓路径、max_batch_size等,并初始化了两个关键存储队列,一个是请求队列,另一个是推理任务队列,以供MindIE LLM接口循环调用。 |
输入参数 |
Tritonserver侧的模型类指针。 |
输出参数 |
执行结果状态。 |
参数 |
描述 |
|---|---|
接口函数 |
TRITONSERVER_Error* TRITONBACKEND_ModelInstanceInitialize(TRITONBACKEND_ModelInstance* instance)。 |
接口功能 |
创建一个ModelInstanceState并初始化,并将其依附在TRITONBACKEND_ModelInstance上。承接了TRITONBACKEND_ModelInstacne中的全部模型实例配置信息(如实例ID、CPU/GPU类型、硬件ID),其中定义了Enqueue成员函数,用来接收Triton侧请求并转化为MindIE侧请求InferRequest,同时生成推理任务inferTask,最后一同写入ModelState内队列中。 |
输入参数 |
Tritonserver侧的模型实例类指针。 |
输出参数 |
执行结果状态。 |
参数 |
描述 |
|---|---|
接口函数 |
接口函数:TRITONSERVER_Error* TRITONBACKEND_ModelInstanceExecute(TRITONBACKEND_ModelInstance* instance, TRITONBACKEND_Request** requests, const uint32_t request_count)。 |
接口功能 |
backend中执行推理的入口函数,首先从instance中提取出ModelInstanceState,接着调用Enqueue成员函数把所有请求放入model_state_中的请求队列requests_和推理任务哈希表inferTasksMap_,后面供LlmManager进行循环读取、推理。 |
输入参数 |
Tritonserver发送给backend的模型实例类指针、请求队列和请求数量。 |
输出参数 |
执行结果状态。 |
参数 |
描述 |
|---|---|
接口函数 |
接口函数:TRITONSERVER_Error* TRITONBACKEND_ModelFinalize(TRITONBACKEND_Model* model)。 |
接口功能 |
清除依附在TRITONBACKEND_Model上的模型状态ModelState。 |
输入参数 |
Tritonserver侧的模型类指针。 |
输出参数 |
执行结果状态。 |
参数 |
描述 |
|---|---|
接口函数 |
接口函数:TRITONSERVER_Error* TRITONBACKEND_ModelInstanceFinalize(TRITONBACKEND_ModelInstance* instance)。 |
接口功能 |
清除依附在TRITONBACKEND_ModelInstance上的实例状态ModelInstanceState。 |
输入参数 |
Tritonserver侧的模型实例类指针。 |
输出参数 |
执行结果状态。 |
适配流程
- 通过接口A对TRITONBACKEND_Backend初始化:对triton::core传来的TritonBackend(强转成了TRITONBACKEND_Backend)进行初始化。主要对backend支持的API版本号等信息进行校验,代码如下:
TRITONSERVER_Error* TRITONBACKEND_Initialize(TRITONBACKEND_Backend* backend) { const char* cname; RETURN_IF_ERROR(TRITONBACKEND_BackendName(backend, &cname)); std::string name(cname); LOG_MESSAGE( TRITONSERVER_LOG_INFO, (std::string("TRITONBACKEND_Initialize: ") + name).c_str()); // 检查当前triton支持的后端API版本是否支持当前的编译版本 uint32_t api_version_major, api_version_minor; RETURN_IF_ERROR( TRITONBACKEND_ApiVersion(&api_version_major, &api_version_minor)); LOG_MESSAGE( TRITONSERVER_LOG_INFO, (std::string("Triton TRITONBACKEND API version: ") + std::to_string(api_version_major) + "." + std::to_string(api_version_minor)) .c_str()); LOG_MESSAGE( TRITONSERVER_LOG_INFO, (std::string("'") + name + "' TRITONBACKEND API version: " + std::to_string(TRITONBACKEND_API_VERSION_MAJOR) + "." + std::to_string(TRITONBACKEND_API_VERSION_MINOR)).c_str()); if ((api_version_major != TRITONBACKEND_API_VERSION_MAJOR) || (api_version_minor < TRITONBACKEND_API_VERSION_MINOR)) { return TRITONSERVER_ErrorNew( TRITONSERVER_ERROR_UNSUPPORTED, (std::string("Triton TRITONBACKEND API version: ") + std::to_string(api_version_major) + "." + std::to_string(api_version_minor) + " does not support '" + name + "' TRITONBACKEND API version: " + std::to_string(TRITONBACKEND_API_VERSION_MAJOR) + "." + std::to_string(TRITONBACKEND_API_VERSION_MINOR)).c_str()); } return nullptr; // success } - 通过接口B对TRITONBACKEND_Model初始化:对triton::core传来的TritonModel(强转成了TRITONBACKEND_Model)进行初始化。主要创建一个ModelState并初始化,将其依附在TRITONBACKEND_Model上,核心代码如下:(其中ModelState包含了两个关键存储队列,一个是请求队列,另一个是推理任务队列,以供MindIE LLM接口循环调用。)
TRITONSERVER_Error* TRITONBACKEND_ModelInitialize(TRITONBACKEND_Model* model) { // 创建一个ModelState类 ModelState* model_state; RETURN_IF_ERROR(ModelState::Create(model, &model_state)); // 将ModelState类依附在TRITONBACKEND_Model上 RETURN_IF_ERROR(TRITONBACKEND_ModelSetState(model, reinterpret_cast<void*>(model_state))); return nullptr; // success } - 通过接口C对TRITONBACKEND_ModelInstance初始化:对triton::core传来的TritonModelInstance(强转成了TRITONBACKEND_ModelInstance)进行初始化。主要创建一个ModelInstanceState并初始化,并将其依附在TRITONBACKEND_ModelInstance上,代码如下:(ModelInstanceState中定义了Enqueue成员函数,用来接收triton侧请求并转化为MindIE侧请求InferRequest,同时生成推理任务InferTask,最后一同写入ModelState内的存储队列中。)
TRITONSERVER_Error* TRITONBACKEND_ModelInstanceInitialize(TRITONBACKEND_ModelInstance* instance) { // 获取该模型实例属于的模型. TRITONBACKEND_Model* model; RETURN_IF_ERROR(TRITONBACKEND_ModelInstanceModel(instance, &model)); // 获取依附在该模型实例上的ModelState. void* vmodelstate; RETURN_IF_ERROR(TRITONBACKEND_ModelState(model, &vmodelstate)); ModelState* model_state = reinterpret_cast<ModelState*>(vmodelstate); // 创建一个ModelInstanceState并依附在模型实例上 ModelInstanceState* instance_state; RETURN_IF_ERROR(ModelInstanceState::Create(model_state, instance, &instance_state)); RETURN_IF_ERROR(TRITONBACKEND_ModelInstanceSetState(instance, reinterpret_cast<void*>(instance_state))); return nullptr; // success } - 通过接口D设置Backend接收triton侧请求的动作:首先从ModelInstance中提取出ModelInstanceState,接着调用Enqueue成员函数把所有请求放入ModelState中的请求队列requests_和推理任务哈希表inferTasksMap_,供LlmManager进行循环读取和推理,代码如下:
TRITONSERVER_Error* TRITONBACKEND_ModelInstanceExecute( TRITONBACKEND_ModelInstance* instance, TRITONBACKEND_Request** requests, const uint32_t request_count) { // 获取模型实例状态 ModelInstanceState* instance_state; RETURN_IF_ERROR(TRITONBACKEND_ModelInstanceState(instance, reinterpret_cast<void**>(&instance_state))); LOG_MESSAGE( TRITONSERVER_LOG_INFO, (std::string("model instance ") + instance_state->Name() + ", executing " + std::to_string(request_count) + " requests") .c_str()); // 将triton::core传来的请求经过解析、转换后存储进ModelState中的请求队列中 instance_state->Enqueue(requests, request_count); return nullptr; // success } void ModelInstanceState::Enqueue(TRITONBACKEND_Request **requests, const uint32_t request_count) { LOG_MESSAGE( TRITONSERVER_LOG_VERBOSE, (std::string("Process Requests: Executing ModelInstanceState::Enqueue")).c_str()); // 创建InferTask哈希表 std::unordered_map<MindIE_LLM::InferRequestId, std::shared_ptr<triton::backend::mindie::InferTask>> newInferTaskMap; std::vector<std::shared_ptr<MindIE_LLM::InferRequest>> newRequests; // 依次将每个来自triton::core的请求转化为mindie支持的请求类型,并记录下请求Id,以InferTask形式一同存入哈希表中 for (uint32_t i = 0; i < request_count; i++) { TRITONBACKEND_Request *bRequest = requests[i]; auto inferTask = std::make_shared<InferTask>(bRequest); auto req = inferTask->GetMieRequest(); auto requestId = req->GetRequestId(); newInferTaskMap[requestId] = inferTask; newRequests.push_back(req); } // 将哈希表中所有的InferTask任务类一同存储进ModelState队列中,以供MindIE读取 std::unique_lock lock(model_state_->GetMutex()); model_state_->GetInferTasksMap().insert(newInferTaskMap.begin(), newInferTaskMap.end()); for (uint32_t i = 0; i < newRequests.size(); i++) { model_state_->GetRequestsQueue().push(newRequests.at(i)); } }