概述
PD分离介绍
Prefill & Decode分离部署(简称:PD分离部署)是将Prefill(预填充)和Decode(解码)这两个推理阶段分开处理的技术,通常适用于对时延有严格要求的场景。PD分离部署可以提高NPU的利用率,尤其是大语言模型时,通过将Prefill实例和Decode实例分开部署,减少Prefill阶段和Decode阶段分时复用在时延上造成的互相干扰,实现同时延下吞吐提升。PD分离工作原理如图1所示。
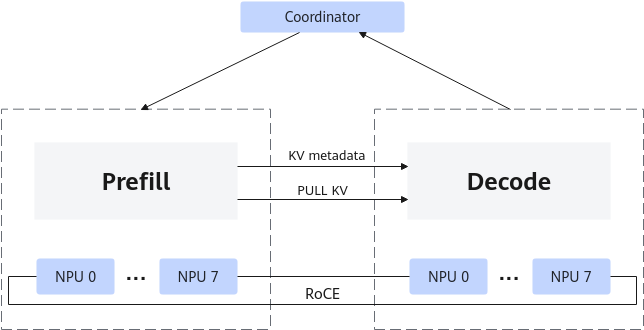
大语言模型推理的阶段可以分为Prefill与Decode阶段:
- Prefill阶段:在生成式语言模型中,Prefill阶段涉及到模型对初始提示(Prompt)的处理,生成初始的隐藏状态(Hidden States)。这个阶段通常涉及对整个模型的一次前向传播,因此计算密集度较高。对于每个新的输入序列,都需要进行一次Prefill。
- Decode阶段:在Prefill阶段之后,模型基于初始隐藏状态逐步生成后续的文本。这一阶段的特点是计算相对较少,但需要反复进行计算,直到生成足够的文本或达到某个终止条件。在生成过程中,只计算最新的token激活值,并进行attention计算,计算最终的预测token。
部署方案
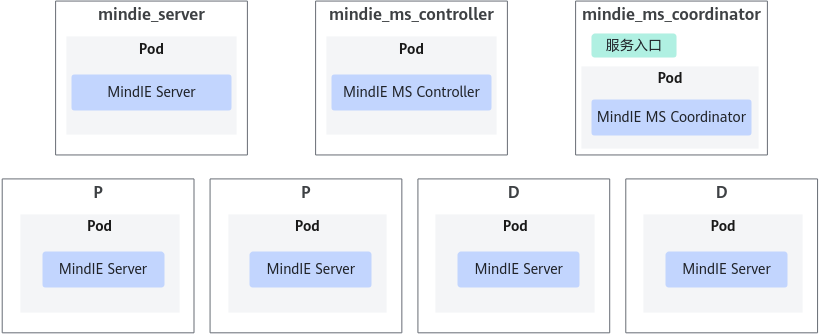
PD分离部署在线下K8s集群的参考部署方案:
通过创建3个K8s的Deployment分别部署MindIE MS Controller(单Pod副本)、MindIE MS Coordinator(单Pod副本)以及MindIE Server(多Pod副本)。
通过K8s的Service为Coordinator Pod开放PD集群的推理入口。
图2 PD分离的部署形态
PD分离优势
PD分离主要包括以下优势:
- 资源利用优化:由于Prefill阶段计算密集,而Decode阶段计算较为稀疏,将这两个阶段分离可以更好的利用NPU的计算资源。
- 提高吞吐量:分离后的Prefill和Decode可以同时处理不同的请求,这意味着在Prefill阶段处理新请求的同时,Decode阶段可以继续处理之前请求的解码任务,从而提高了整体的处理能力。
- 降低延迟:由于Prefill和Decode分别在不同的阶段进行,可以减少等待时间,特别是当有多个请求并发到达时。

父主题: 场景介绍