性能数据展示
支持界面预览
支持集群场景展示
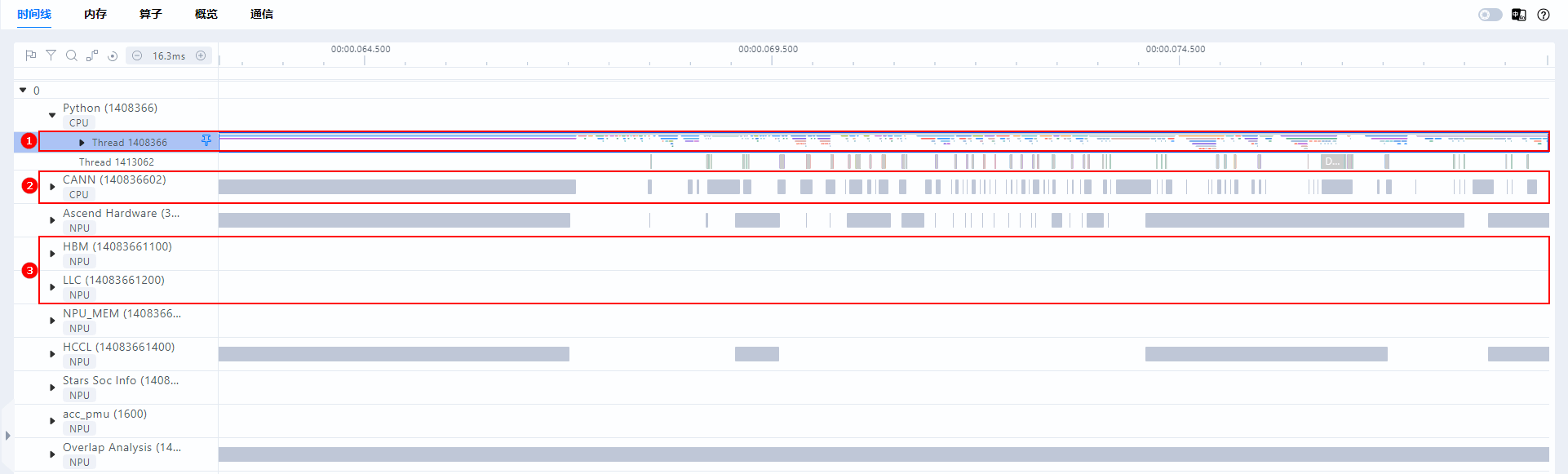
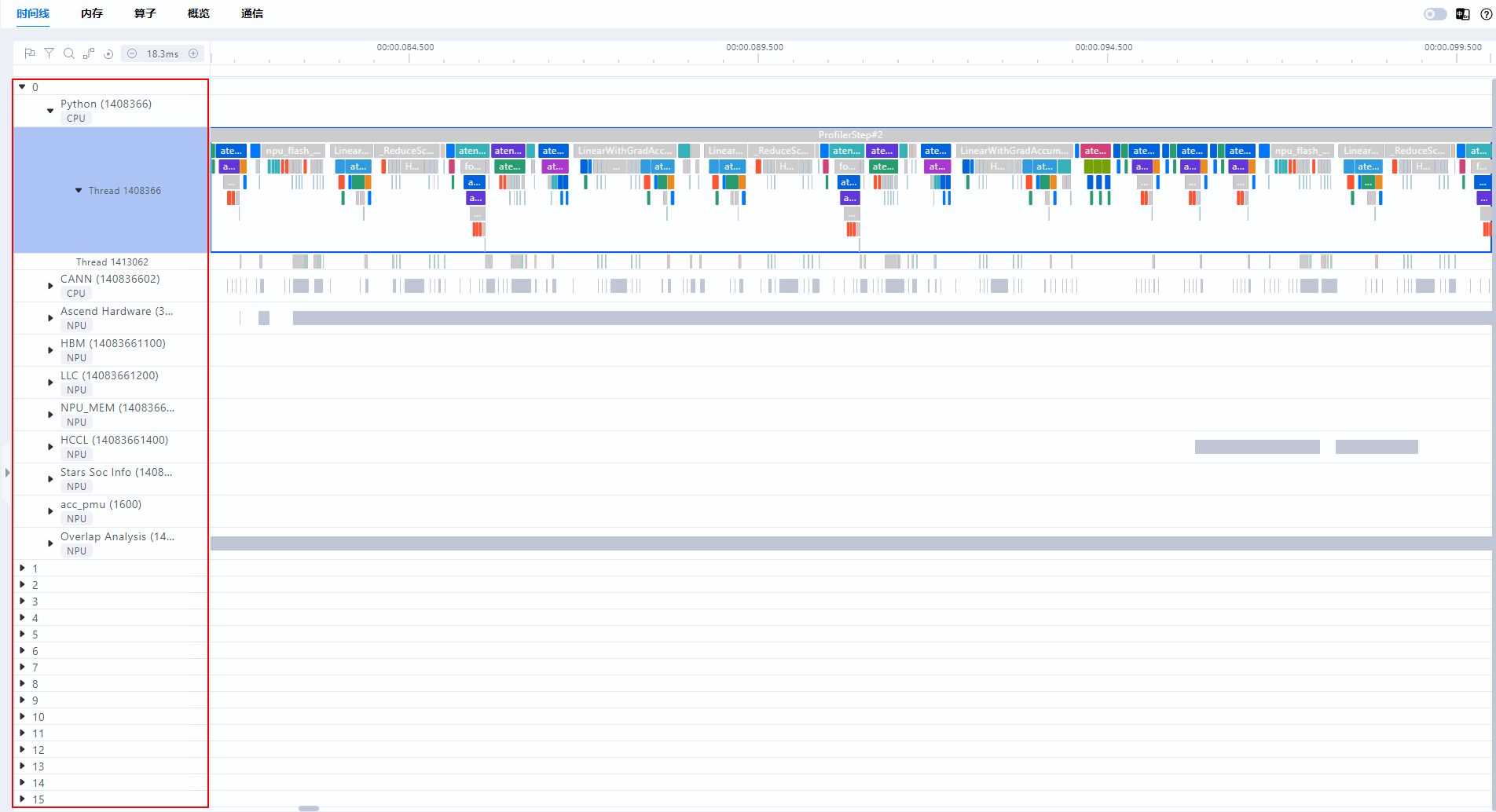
MindStudio Insight支持导入和展示集群场景数据,无需手动合并多个单卡数据。支持训练场景下的多机多卡和推理场景下多卡等场景,MindStudio Insight能够自动识别导入文件夹下所有的trace_view.json和msprof*.json文件。以16卡为例进行展示,如图2所示。
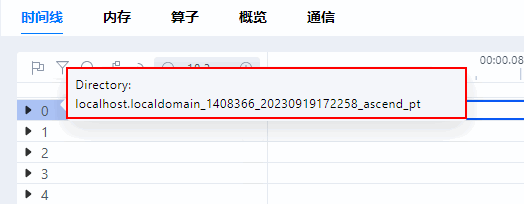
在集群场景中,为方便快速定位某卡的数据所对应的文件目录,可以将鼠标悬停在卡的序号上,则会显示该卡数据所对应的文件目录。例如将鼠标悬停在“0”上,则会在后方弹出示该卡所对应的文件目录,如图3所示。
支持分卡/泳道显示和对比
- 当导入集群场景数据时,展示的时间线(Timeline)信息较多,为更好的帮助用户对比分析,MindStudio Insight支持按卡和按泳道进行过滤展示。
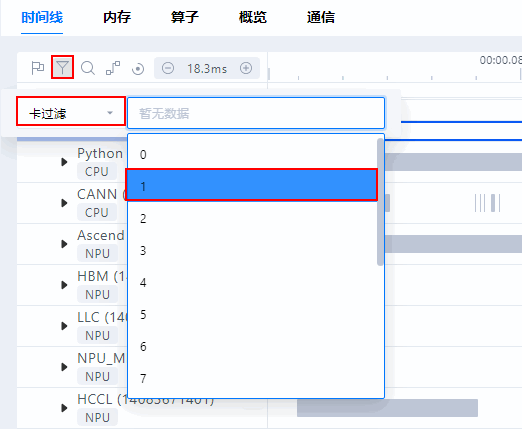
- 按卡显示:以只显示1卡为例,单击界面左上方
 ,选择“卡过滤”,然后单击后方输入框,在下拉框选择“1”,即可显示1卡的时间线(Timeline)信息,如图4所示。
,选择“卡过滤”,然后单击后方输入框,在下拉框选择“1”,即可显示1卡的时间线(Timeline)信息,如图4所示。
- 按泳道显示:以只显示每张卡的Overlap Analysis泳道为例,单击界面左上方工具栏
 ,选择“泳道过滤”,然后单击后方输入框,在下拉框选择“Overlap Analysis”,即可显示Overlap Analysis泳道的时间线(Timeline)信息,如图5所示。
,选择“泳道过滤”,然后单击后方输入框,在下拉框选择“Overlap Analysis”,即可显示Overlap Analysis泳道的时间线(Timeline)信息,如图5所示。
- 按卡显示:以只显示1卡为例,单击界面左上方
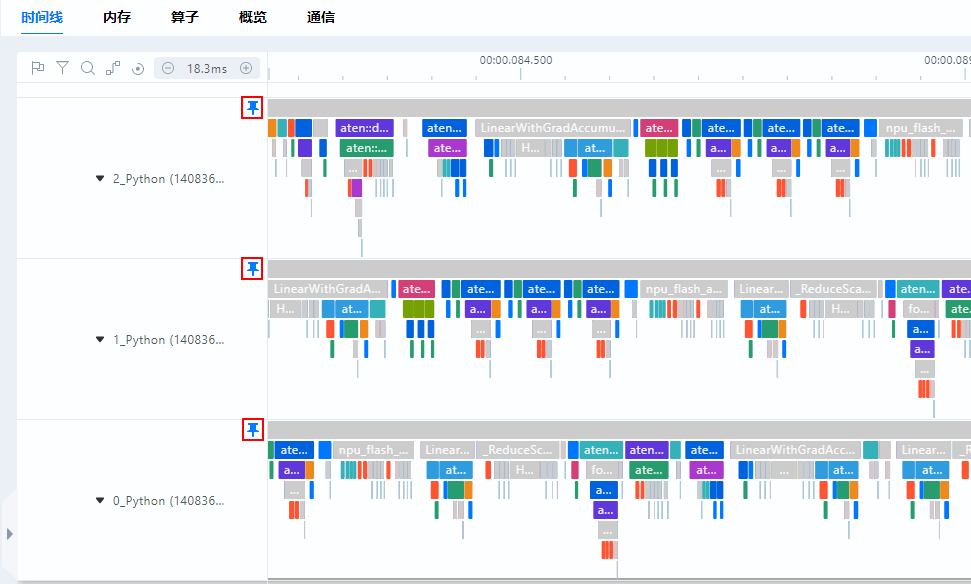
- MindStudio Insight支持固定并置顶泳道,方便同其他同类层级进行对比。
例:单击0、1、2卡中的某三层级名后方的
 ,则可置顶,再次单击
,则可置顶,再次单击 即可取消置顶,如图6所示。
即可取消置顶,如图6所示。

支持单卡时间对齐

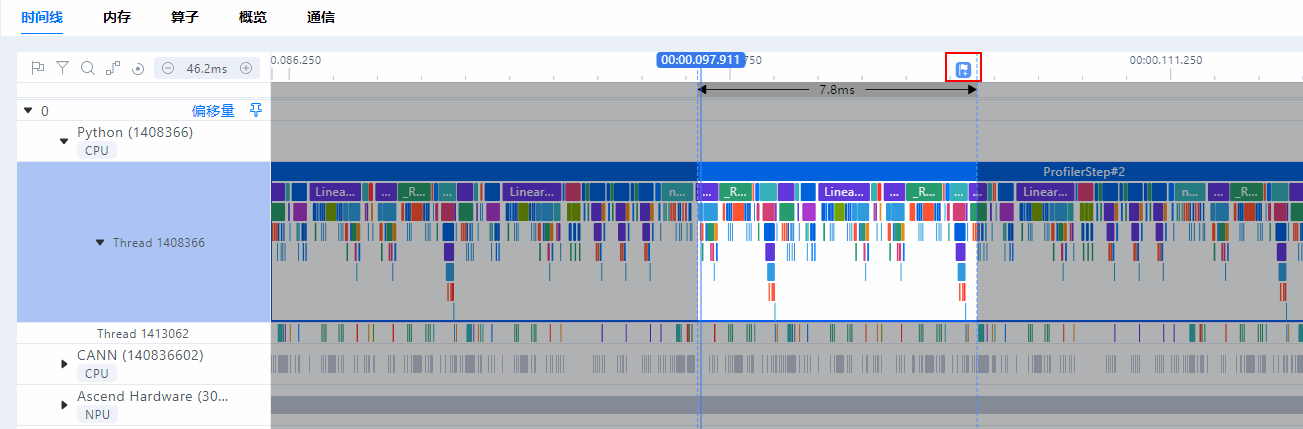
单卡场景和集群场景都已实现时间线(Timeline)相对位置自动对齐,以单卡维度自动设置偏移量进行对齐,如需手动设置相对位置对齐,请参见如下操作。
- 手动设置对齐到起始位置
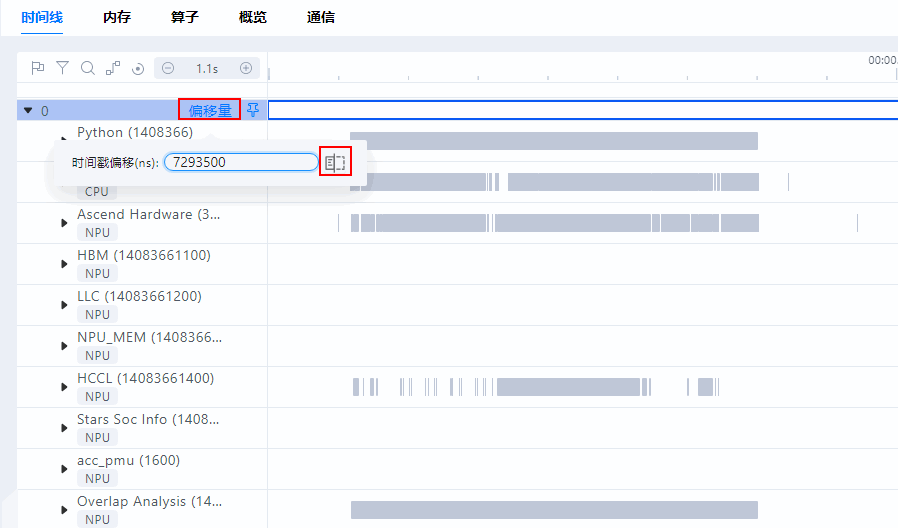
在偏移量的弹窗中单击
 (对齐到起始位置)按钮,会在“时间戳偏移(ns)”输入框中显示该卡中最左侧的线程数据与时间轴初始位置(00:00.000)的偏移量,然后按回车键,时间线(Timeline)界面将会把该线程数据与时间轴初始位置对齐。
(对齐到起始位置)按钮,会在“时间戳偏移(ns)”输入框中显示该卡中最左侧的线程数据与时间轴初始位置(00:00.000)的偏移量,然后按回车键,时间线(Timeline)界面将会把该线程数据与时间轴初始位置对齐。如图7所示,0卡中最左侧线程数据与时间轴初始位置的偏移量为7293500ns。
- 手动设置偏移量
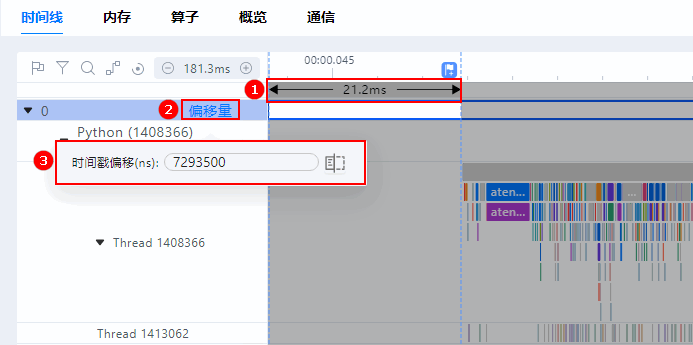
对于多机多卡场景,由于机器上时间不准,可能造成多卡间时间线(Timeline)相对位置不准确,MindStudio Insight支持单卡维度的时间校准,如图8所示,通过设置偏移量,可以将单卡的时间线(Timeline)左右移动,从而达到时间“校准”的目的。偏移量的单位为ns,负值为右移,正值为左移。
支持多机多卡展示
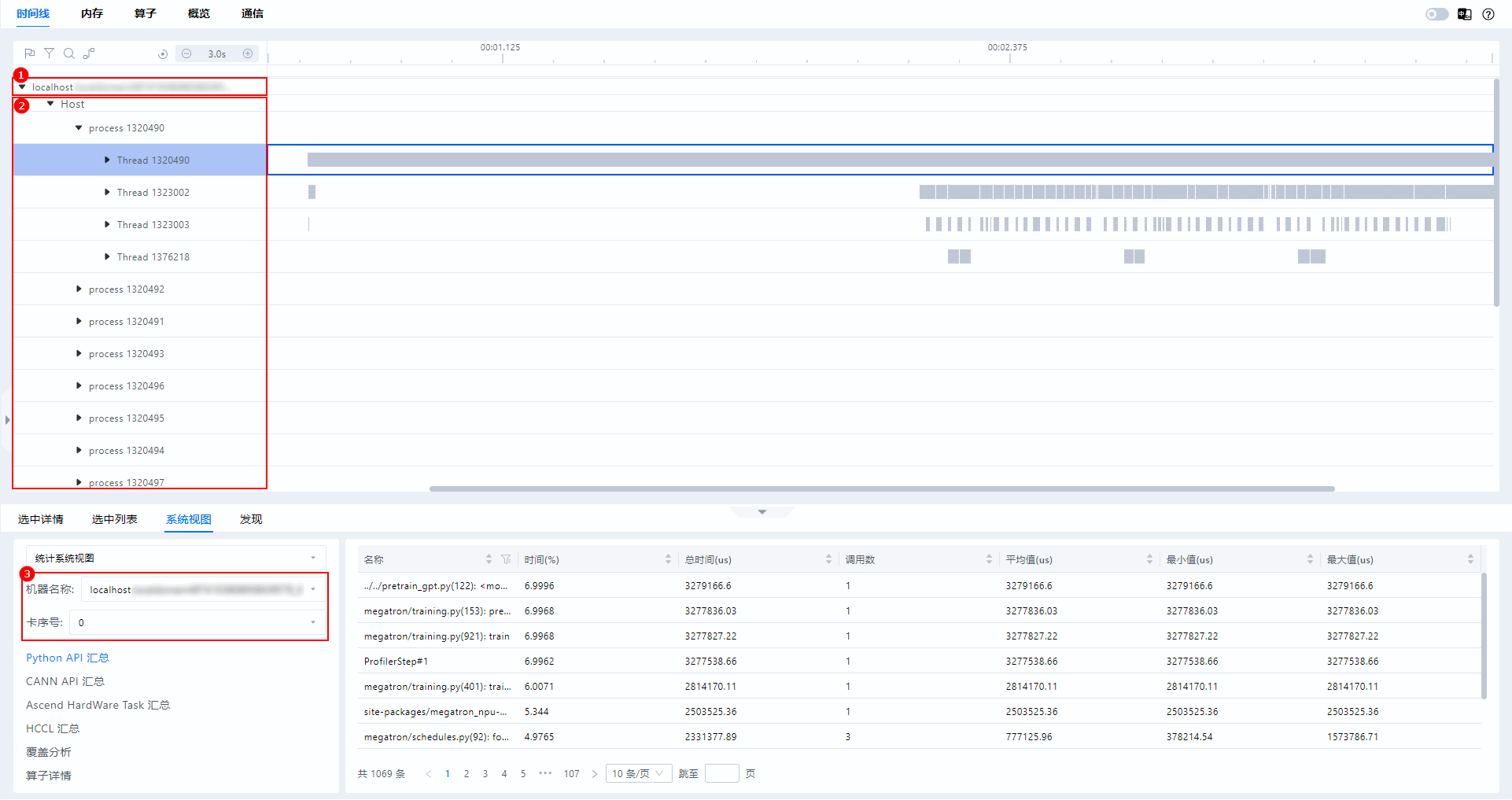
当导入多机多卡数据时,MindStudio Insight支持以机器维度展示数据,如图9所示。
图中1为机器名称,是由hostName和hostUid组成。
图中2为泳道层级展示,为Host和“Card”。
图中3为参数配置项,在多机多卡场景下,需先选择“机器名称”,再选择该机器下的“卡序号”进行配置。当导入的DB文件中存在名称为“HOST_INFO”的表时,在时间线(Timeline)界面下的“系统视图”页签(选择“统计系统视图”和“专家系统视图”时)和“发现”页签下,存在该配置项。
该功能仅支持在全量DB场景下展示。
设置和查看标记
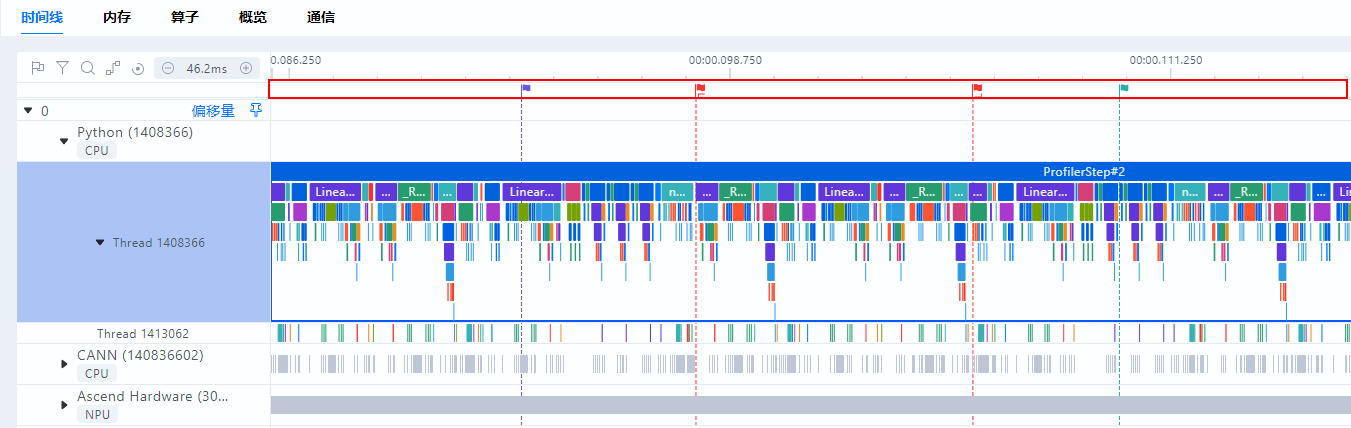
- 区域标记
左键双击任一标记,可以设置该标记对的属性,支持修改标记对名称、颜色以及删除该标记对,如图11所示。
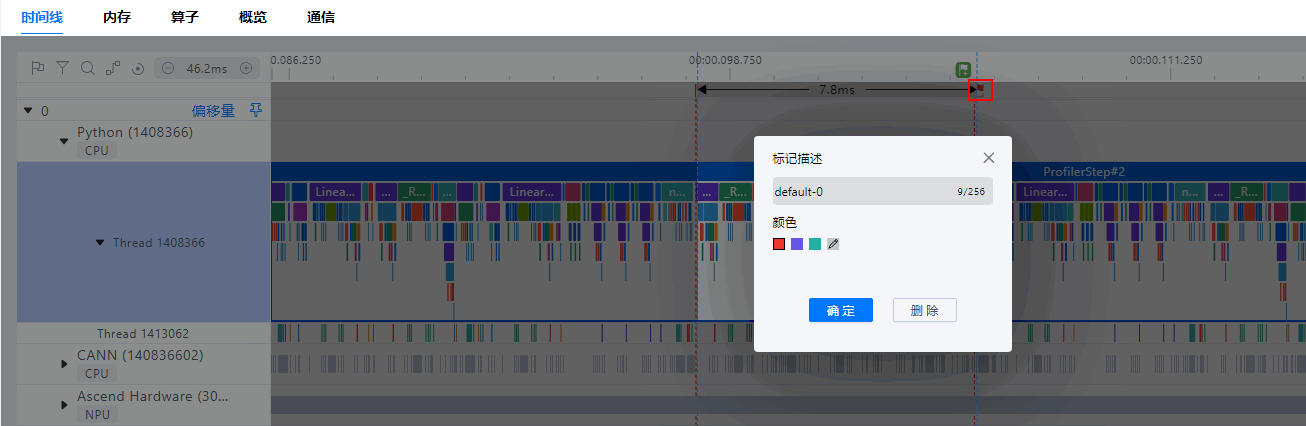
- 单点标记
左键双击标记,可以设置该标记的属性,支持修改标记对名称、颜色以及删除该标记。
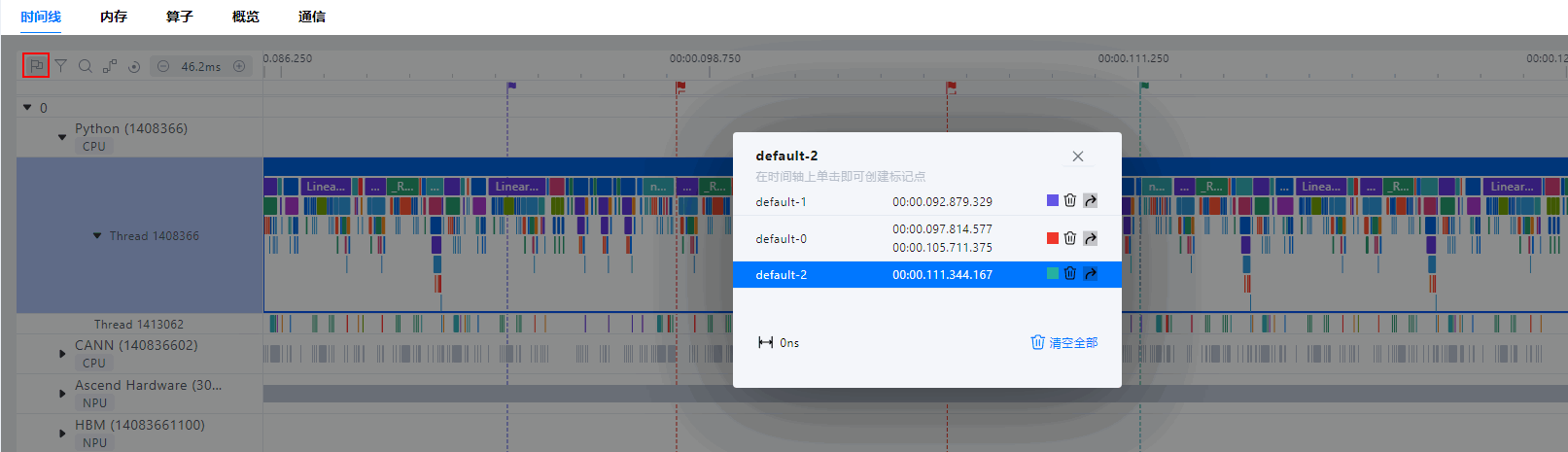
- 标记管理



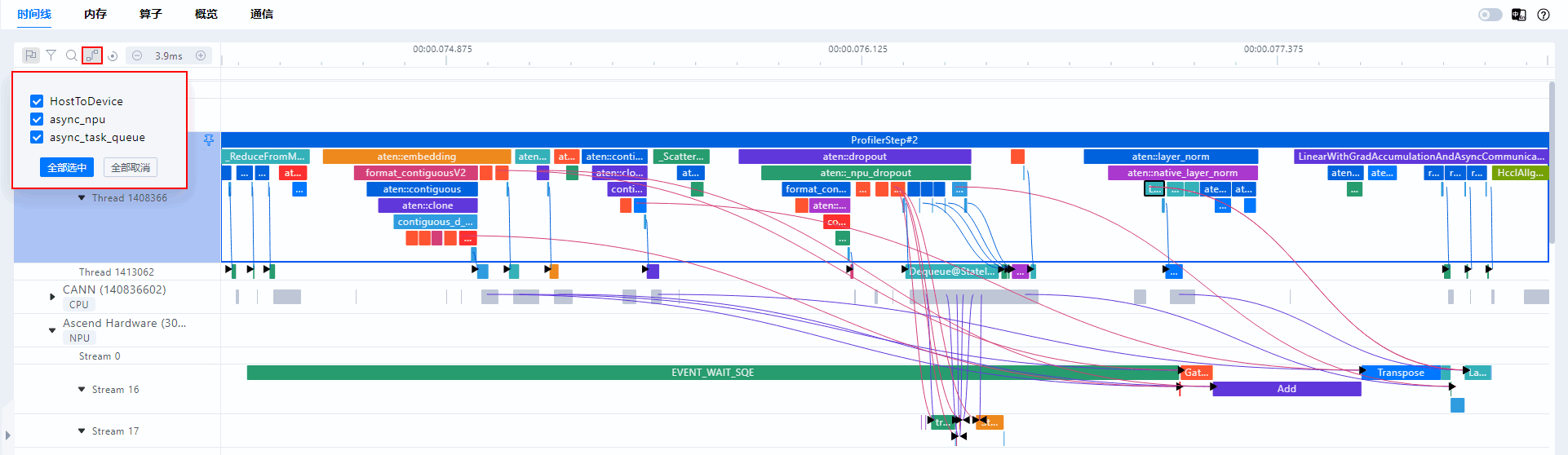
算子连线功能
- MindStudio Insight支持算子连线关系展示,单击有连线的算子,即可显示该算子关联的连线,即使折叠连线起点或者终点的进程,连线也不会消失,如图14所示。
如果同时折叠连线起点和终点的进程,连线就会消失。
- MindStudio Insight支持全量连线的功能,单击界面左上方工具栏中的
 ,在弹框中选择某一(几)个连线类型,则在图形化窗格展示对应类型的所有连线,如图15所示。
,在弹框中选择某一(几)个连线类型,则在图形化窗格展示对应类型的所有连线,如图15所示。
应用层算子到NPU算子之间通过连线方式展示下发到执行的对应关系如下所示:
- HostToDevice
- CANN层Node(算子)到AscendHardware的NPU算子的下发执行关系(Host到Device)。
- CANN层Node(算子)到HCCL通信算子的下发执行关系(Host到Device)。
- async_npu
- 应用层算子到Ascend Hardware的NPU算子的下发执行关系。
- 应用层算子到HCCL通信算子的下发执行关系。
- async_task_queue:应用层Enqueue到Dequeue的入队列到出队列对应关系,仅PyTorch场景。
- fwdbwd:前向API到反向API,仅PyTorch场景。
- MsTx:打点数据到AscendHardware的NPU算子的下发执行关系。
- 各层的对应关系是否呈现与对应采集场景是否采集该数据有关,请以实际情况为准。
- 各层之间的连线与各层是否展开呈联动关系,如果选择了某个连线类型,对应层没有展开,则不会显示该类型的连线。
- HostToDevice

支持选择性解析多卡数据
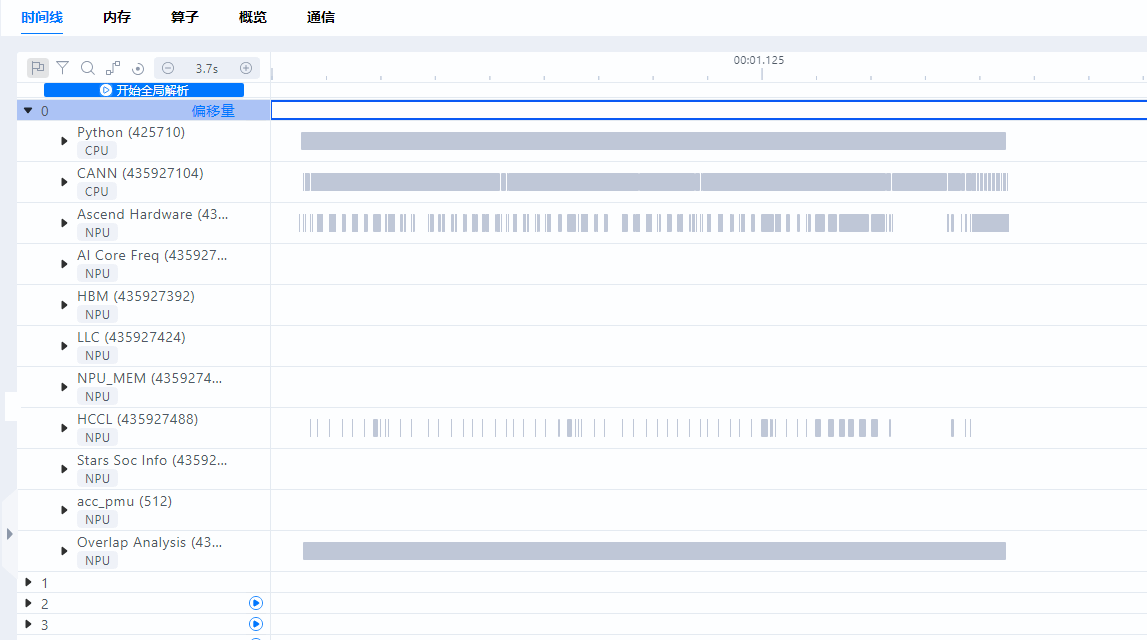
MindStudio Insight工具导入超过16卡的数据时,在时间线(Timeline)界面支持选择性解析数据,可一键全部解析或部分解析。
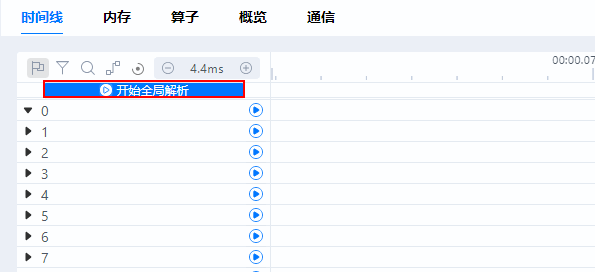
- 一键全部解析:在时间线(Timeline)界面,单击“开始全局解析”,将开始解析所有卡的数据,如图16所示。当所有卡的数据解析完成后,“开始全局解析”按钮消失。
- 部分解析:当只需要解析部分卡的数据时,可逐个单击对应卡序号后边的
 ,解析所选卡的数据,如图17所示。当对应卡数据解析完成后,按钮消失,如图中0卡和1卡所示。
,解析所选卡的数据,如图17所示。当对应卡数据解析完成后,按钮消失,如图中0卡和1卡所示。
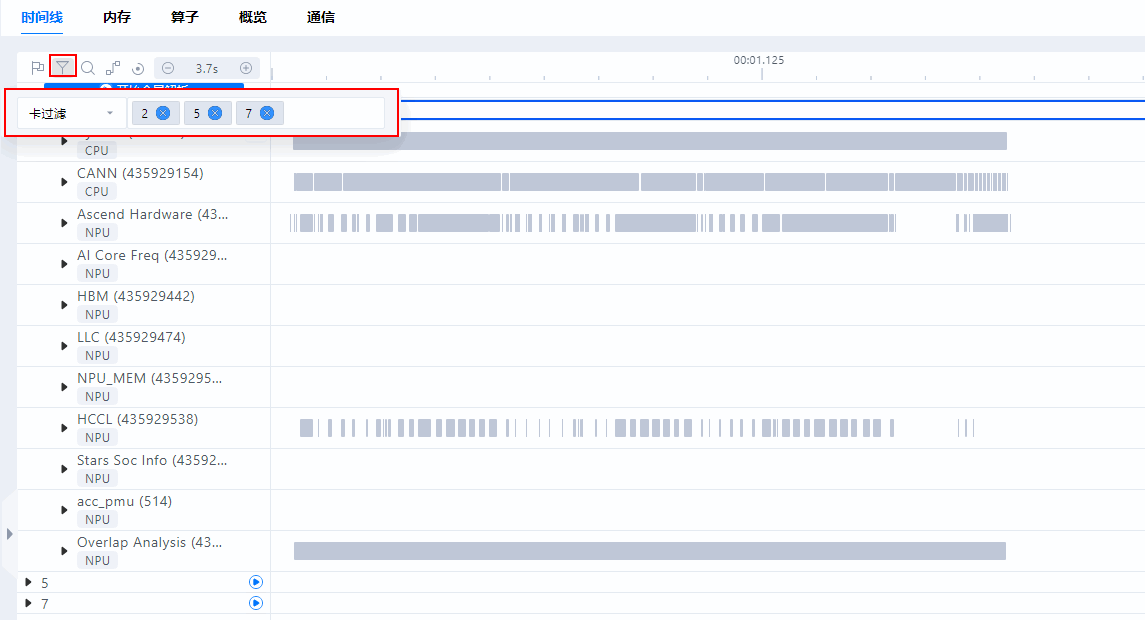
如果导入的卡数量较多,可通过卡过滤功能定位所需解析数据的卡,进行数据解析操作。在时间线(Timeline)界面的工具栏中,单击
 ,选择“卡过滤”,然后单击后方输入框,在下拉框选择所需呈现的卡,即可在时间线(Timeline)界面展示对应信息,单击卡序号后边的
,选择“卡过滤”,然后单击后方输入框,在下拉框选择所需呈现的卡,即可在时间线(Timeline)界面展示对应信息,单击卡序号后边的 ,进行数据解析,如图18所示,解析2、5、7卡数据。
,进行数据解析,如图18所示,解析2、5、7卡数据。