界面介绍
功能说明
概览(Summary)界面提供通信域识别、划分和耗时拆解、分析功能。支持自动识别通信域,用户也可自行配置;支持按照通信域对比stage耗时、计算耗时和通信耗时,从而分析同一通信域内的切分是否均匀,是否存在通信慢卡和慢链路问题,帮助开发者快速识别问题。
界面展示
概览(Summary)界面由基本信息(Base Info)(区域一)和并行策略分析(Parallel Strategy Analysis)(区域二)组成,如图1所示。
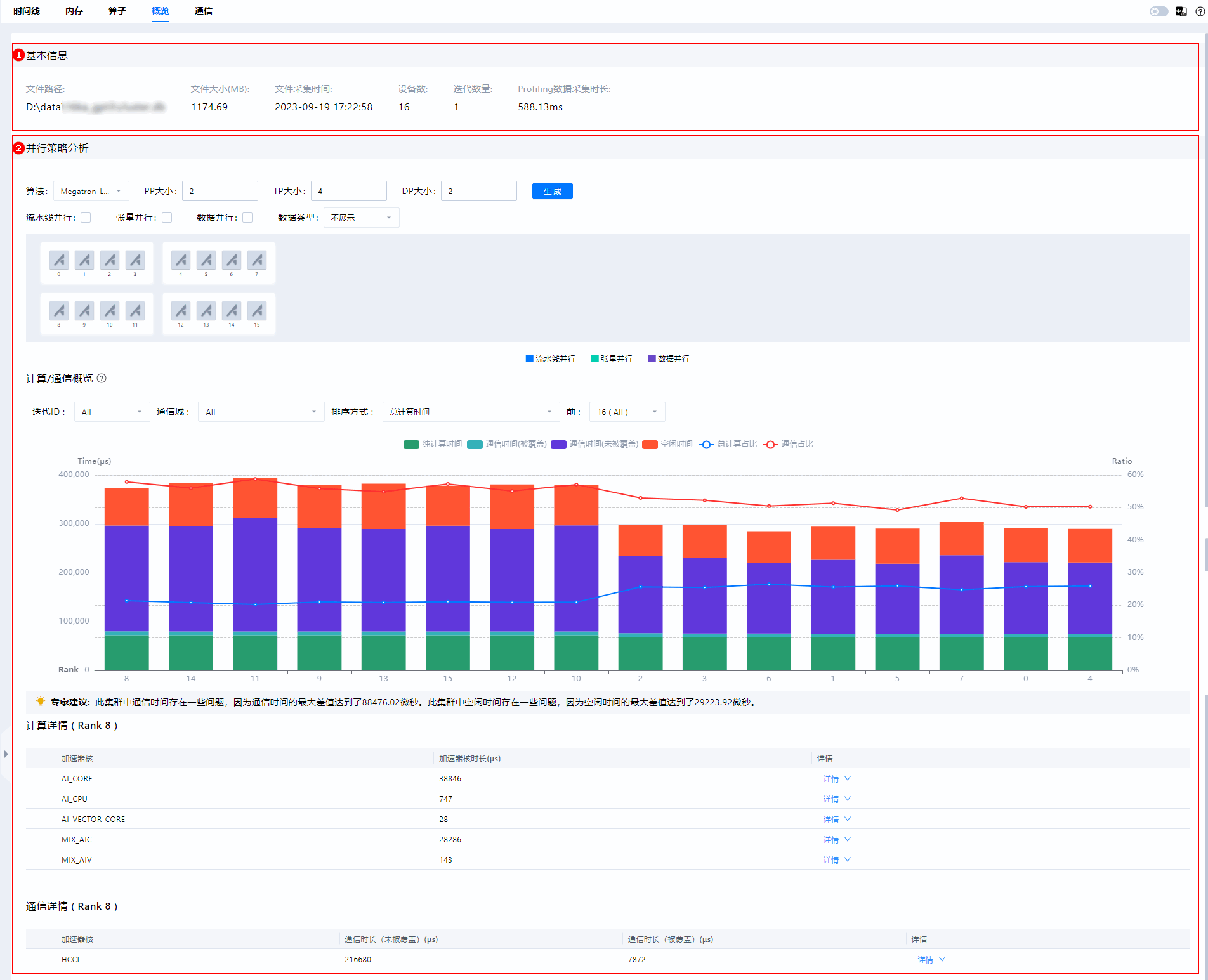
- 区域一:基本信息(Base Info),数据的基本信息,包括设备和迭代数量、性能数据大小、数据采集时长等信息。
“Profiling数据采集时长”在TEXT场景和DB场景下可能存在差异,TEXT场景下,Profiling数据采集时长是以采集到数据的时间为起始,数据结束为终止的时间周期,DB场景下,Profiling数据采集时长是以数据采集开始时间为起始,数据采集结束时间为终止的时间周期,二者的微小差异对于Profiling数据分析无影响。
- 区域二:并行策略分析(Parallel Strategy Analysis),包括并行策略概览、计算/通信概览、计算详情(Rank ID)、通信详情(Rank ID)以及硬件节点耗时和节点receive算子耗时概览。
并行策略概览包括并行策略设置和并行策略图展示,并行策略设置参数解释如表1所示,并行策略以图形展示,选择图中卡片,可悬浮显示该卡的耗时详情。
表1 并行参数 中文字段
英文字段
说明
算法
Algorithm
默认为Megatron-LM(tp-dp-pp),还可选Megatron-LM(tp-pp-dp)。
Megatron-LM是一种用于训练大规模深度学习模型的分布式训练框架,通过高效利用计算资源和内存来加速深度学习模型的训练过程,其中tp、dp、pp表示逻辑卡号的编号顺序。
PP大小
PP Size
流水线并行大小。
流水线并行(Pipeline Parallelism)通过将模型的不同层次分布在不同的卡上执行,在一个卡执行当前批次数据时,另一个卡可以处理下一个批次的数据。
TP大小
TP Size
张量并行大小。
张量并行(Tensor Parallelism)是一种将模型参数划分成多个部分,并分布到不同卡上进行计算。
DP大小
DP Size
数据并行大小。
数据并行(Data Parallelism)将训练集分成不同多个批次,分配到不同卡上进行计算。
数据类型
Data Type
可按照数据类型展示并行策略图。
- 不展示,即并行策略图上的卡片信息为默认状态。
- 当分别选择“预处理时间”、“总计算时间”、“纯计算时间”、“通信时间(被覆盖)”、“通信时间(未被覆盖)”或“空闲时间”时,会在选框后显示“精度”参数,且并行策略图上的卡片会按照对应值被填色,可直观的分析出各卡性能情况。“精度”参数解释与使用请参见支持以精度维度分析。
计算/通信概览(Computation/Communication Overview),计算及通信概览,柱状图展示计算或通信算子的迭代耗时数据,折线图展示计算或通信算子的耗时占比数据,专家建议(Advice)是对计算通信域内各卡的计算时间、通信时间(未被覆盖)和空闲时间进行数据分析后给出的建议,帮助开发者快速分析,界面参数解释请参见表2所示。
表2 计算/通信概览 中文字段
英文字段
说明
迭代ID
Step
迭代ID,下拉框支持选择某一个迭代或者所有迭代。
通信域
Rank Group
节点ID,下拉框支持选择一个、多个或者所有节点。
排序方式
Order By
横坐标将从左至右根据选中迭代下的集群节点按以下选项进行降序排列:- 总计算时间(Total Computing):NPU上的内核时间总和。
- 纯计算时间(Pure Computing):纯计算时间 = 总计算时间 – 通信时间(被覆盖)。
- 通信时间(被覆盖)(Communication(Overlapped)):被覆盖的通信时长。
- 通信时间(未被覆盖)(Communication(Not Overlapped)):未被覆盖的通信时长,即纯通信时长。
- 空闲时间(Free):间隙时长。
- 卡序号(Rank ID):卡序号。
前
Top
可通过配置Top参数值选择展示“排序方式”的TopN条数据。
Time(us)
Time(us)
左侧纵坐标表示时长,单位us。计算方式如下:
总时间 = 预处理时间 + 纯计算时间 + 通信时间(被覆盖) + 通信时间(未被覆盖)+ 间隙时间,其中Preparing为数据预处理时间。
Ratio
Ratio
右侧纵坐标表示耗时占比,包括以下占比信息:
- 总计算比例(Computing Ratio):总计算耗时占比 = 总计算时间 / 总时间。
- 通信比例(Communication Ratio):通信耗时占比 = 未被覆盖的通信时长 / 总时间。
专家建议
Advice
慢卡分析建议,是对计算通信域内各卡的计算时间、通信时间(未被覆盖)和空闲时间进行数据分析后给出的专家建议。
慢卡分析规则(以计算时间为例):如果通信域内各卡的计算时间(最大值-最小值)/各卡总时间(计算时间+通信时间(未被覆盖)+空闲时间)的平均值大于5%,说明计算时间有异常。
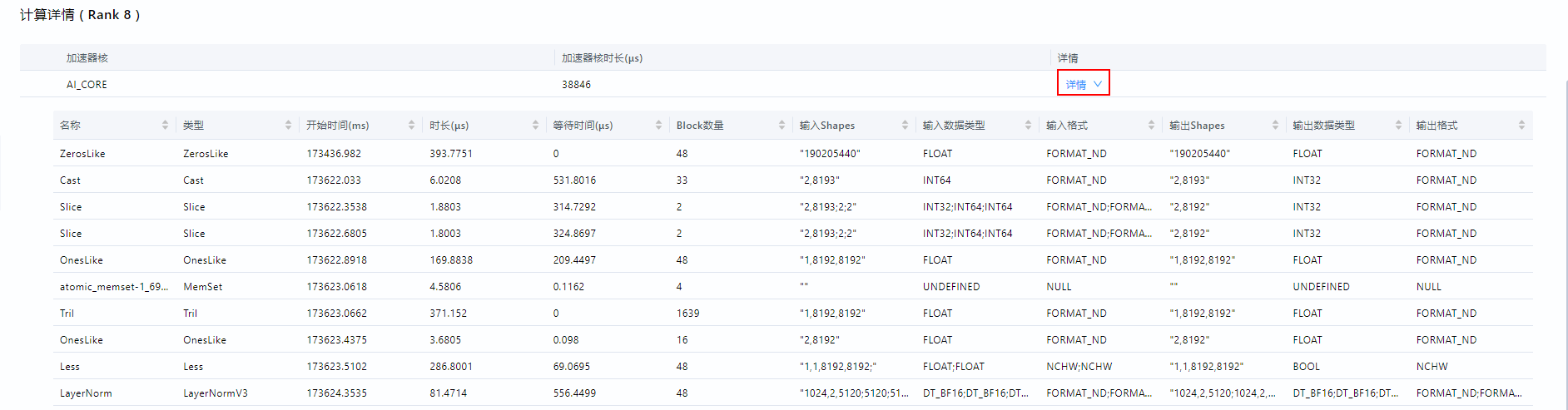
计算详情(Rank ID)(Computing Detail(Rank ID)),单击计算/通信概览区域中某个节点的柱状图时,将展示该节点加速核的总耗时和利用率,单击对应的“详情”后展示计算算子的详细信息,如图2所示,字段解释如表3所示。表3 计算详情字段说明 中文字段
英文字段
说明
加速器核
Accelerator Core
AI加速核类型,包括AI Core、AI CPU等。
加速器核时长(μs)
Accelerator Core Durations(μs)
加速核的总耗时。
名称
Name
算子名称。
类型
Type
算子类型。
开始时间(ms)
Start Time(ms)
算子执行开始时间。
时长(μs)
Duration(μs)
当前算子执行耗时。
等待时间(μs)
Wait Time(μs)
算子执行等待时间。
Block数量
Block Dim
运行切分数量,对应任务执行时的核数。
输入Shapes
Input Shapes
算子输入Shape。
输入数据类型
Input Data Types
算子输入数据类型。
输入格式
Input Formats
算子输入数据格式。
输出Shapes
Output Shapes
算子输出Shape。
输出数据类型
Output Data Types
算子输出数据类型。
输出格式
Output Formats
算子输出数据格式。
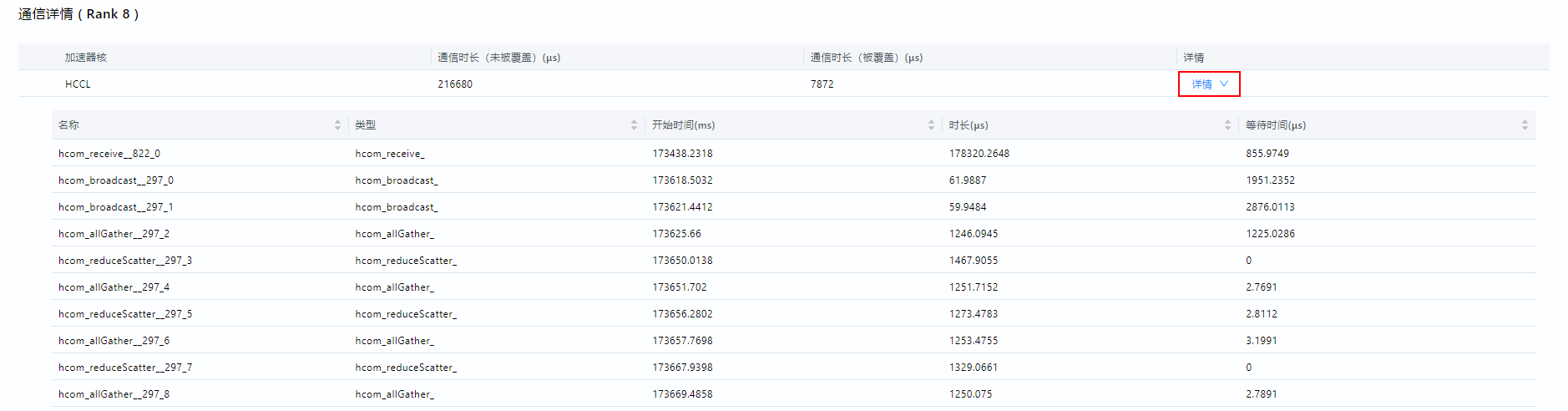
通信详情(Rank ID)(Communication Detail(Rank ID)),单击计算/通信概览区域中某个节点的柱状图时,将展示该节点通信算子的总耗时(包含未被覆盖的通信时长和被覆盖的通信时长),单击对应的“详情”后展示通信算子的详细信息,如图3所示,字段解释如表4所示。表4 通信详情字段说明 中文字段
英文字段
说明
加速器核
Accelerator Core
AI加速核类型,包括AI Core、AI CPU等。
通信时长(未被覆盖)(μs)
Communication(Not Overlapped) Durations(μs)
未被覆盖的通信时长,即纯通信时长。
通信时长(被覆盖)(μs)
Communication(Overlapped) Durations(μs)
被覆盖的通信时长。
名称
Name
通信算子名称。
类型
Type
通信算子类型。
开始时间(ms)
Start Time(ms)
通信算子执行开始时间。
时长(μs)
Duration(μs)
当前通信算子执行耗时。
等待时间(μs)
Wait Time(μs)
通信算子执行等待时间。
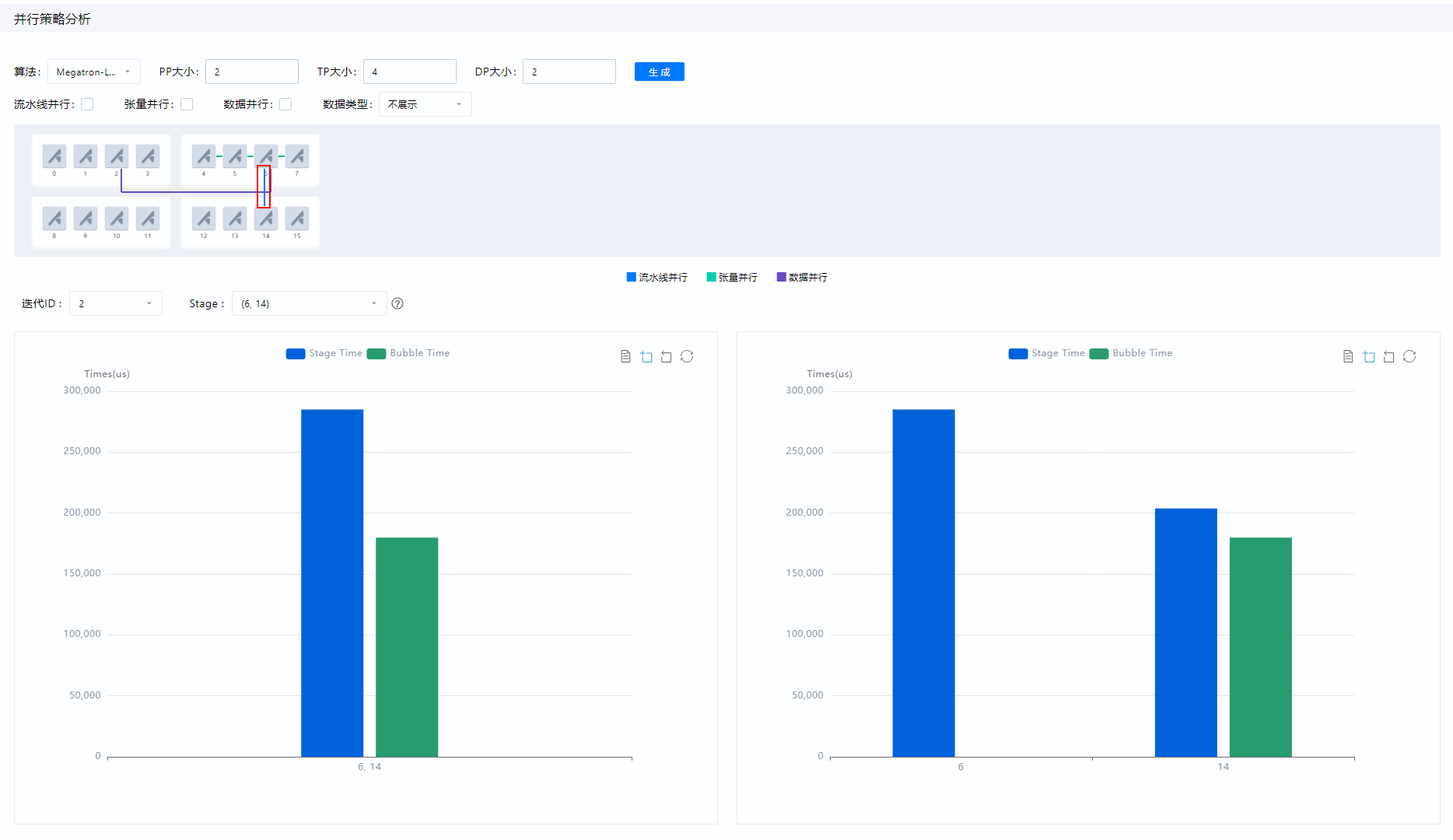
当单击并行策略展示图中单卡图标,出现PP、TP、DP连线,单击PP连线,会展示硬件节点耗时和节点receive算子耗时概览,右侧图表展示的是所选卡的Stage Time和Bubble Time耗时,左侧图表是以Stage为维度展示Stage Time和Bubble Time的平均值,如图4所示,参数解释请参见表5所示。表5 流水线并行参数 中文字段
英文字段
说明
迭代ID
Step
迭代ID,下拉框支持选择某一个迭代。
Stage
Stage
流水线并行分组,下拉框支持选择分组,与并行策略区域流水线并行的分组对应。
Stage Time
Stage Time
硬件节点实际计算时间。
流水线并行时,stage时间表示的是节点运行除receive算子时间外的其他耗时。
Bubble Time
Bubble Time
receive算子时间,表示硬件节点执行过程中,receive算子耗时总和。

- 单击柱状图区域右上角
 按钮,以列表形式查看柱状图中的显示的数据。
按钮,以列表形式查看柱状图中的显示的数据。 - 单击柱状图区域右上角
 按钮,使其置灰,则柱状图将锁定,不再支持鼠标左键框选放大功能;再次单击此按钮,恢复鼠标左键框选放大功能。放大功能默认开启。
按钮,使其置灰,则柱状图将锁定,不再支持鼠标左键框选放大功能;再次单击此按钮,恢复鼠标左键框选放大功能。放大功能默认开启。 - 单击柱状图区域右上角
 按钮,柱状图将会撤销一次放大操作。
按钮,柱状图将会撤销一次放大操作。 - 单击柱状图区域右上角
 按钮,柱状图将会恢复最初状态。
按钮,柱状图将会恢复最初状态。