方案介绍
为了解决Spine+Leaf网络架构下,Spine交换机下行流量冲突问题,MindCluster为用户提供了两个版本的交换机亲和性调度。为了减少组网成本,MindCluster支持用户单层组网的交换机亲和性调度。为了最大化利用带宽更高的超节点网络,MindCluster为用户提供逻辑超节点亲和性调度。交换机亲和性,即一个Leaf交换机下有多个节点,系统会根据配置的交换机亲和性规则,选择最合适的节点分配给训练任务。
- 交换机亲和性调度 1.0
由Volcano进行亲和性调度,保证任务训练时的流量不会造成Spine交换机的下行流量冲突。当前支持的产品为Atlas 训练系列产品和Atlas A2 训练系列产品;支持的框架为PyTorch和MindSpore框架。
- 交换机亲和性调度 2.0
采用Volcano+iMaster NCE-Fabric的方案,通过iMaster NCE-Fabric来动态计算训练任务通信时的网络通路,不再使用调度器来解决Spine交换机下行流量冲突。同时支持一个交换机下的节点可以被多个跨交换机的任务使用,提高集群的资源利用率。当前支持的产品为Atlas A2 训练系列产品;支持的框架为PyTorch框架。
- 单层交换机亲和性调度
支持Atlas 800I A2 推理服务器进行单层组网(只有Leaf层没有Spine层),使用单层交换机亲和性调度,选择最合适的节点分配给分布式推理任务。

- 当前只支持训练任务进行整卡的交换机亲和性调度(包括断点续训),不支持推理任务,也不支持静态或动态vNPU调度。
- 使用交换机亲和性调度2.0前,请先参见章节,了解相关参数面组网的原理说明和操作指导。
交换机亲和性调度1.0流程图
交换机亲和性调度1.0的调度逻辑请参见图1。

步骤说明如下:
- Volcano读取basic-tor-node-cm文件获取集群的拓扑信息,为调度任务做准备。
- 用户从深度学习平台或命令行下发训练任务。
- Volcano根据从basic-tor-node-cm中获取的信息,将任务Pod调度到合适的计算节点上;并在任务Pod的annotation中写入该Pod调度时当前节点的交换机状态。
交换机亲和性调度2.0流程图
交换机亲和性调度2.0的调度逻辑请参见图2。
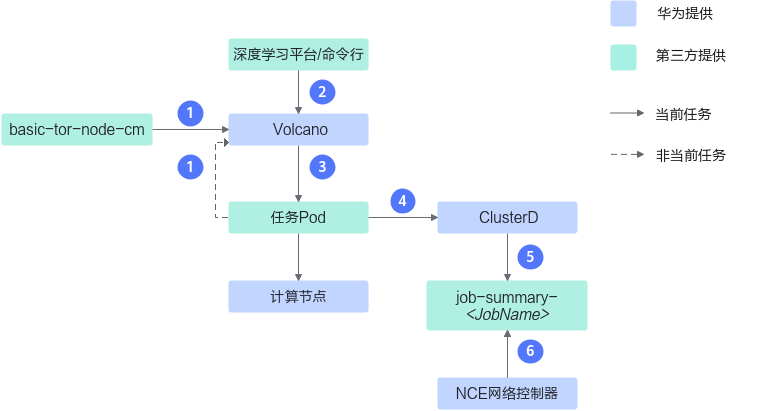
步骤说明如下:
- Volcano读取basic-tor-node-cm文件获取集群的拓扑信息;Volcano读取集群中所有任务Pod上的annotation来获取集群中每个交换机状态,为调度任务做准备。
- 用户从深度学习平台或命令行下发训练任务。
- Volcano根据从basic-tor-node-cm中获取的信息,将任务Pod调度到合适的计算节点上;并在任务Pod的annotation中写入该Pod调度时当前节点的交换机状态。
- ClusterD通过informer机制感知到任务调度到合适的计算节点,并且汇集任务所有Pod的信息。
- ClusterD将任务信息写到job-summary-<JobName> Configmap中。
- iMaster NCE-Fabric通过job-summary-<JobName> ConfigMap文件读取任务的信息,动态计算训练任务通信时的网络通路。
任务说明
交换机亲和性调度针对不同的任务类型,选择不同的调度策略。任务类型是下发训练任务yaml中的tor-affinity字段取值,不同任务类型对任务的副本数要求不同,具体说明如下:
任务类型 |
任务标签 |
任务副本数 |
|---|---|---|
普通任务 |
normal-schema |
不限 |
大模型任务 |
large-model-schema |
大于或等于4 |
填充任务 |
large-model-schema |
小于4 |