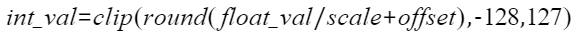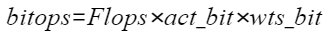简介
本章节详细介绍AMCT量化场景,以及每个场景下的功能。
量化方式
AMCT支持命令行方式和Python API接口方式量化原始网络模型,两种方式优缺点比较如下:
命令行方式 |
Python API接口方式 |
|---|---|
量化准备动作简单,只需准备模型和模型匹配的数据集即可。 |
需要了解Python语法和量化流程。 |
量化过程简单,只涉及参数选择,无需对量化脚本进行适配。 |
需要适配修改量化脚本。 |
当前仅支持如下特性:
|
支持量化的所有功能。 |
命令行方式中的均匀量化示例请参见快速入门,QAT模型适配CANN模型命令行方式调用示例请参见Gitee或Github;Python API接口方式请参见训练后量化。
量化分类
量化根据是否需要重训练,分为训练后量化(Post-Training Quantization,简称PTQ)和量化感知训练(Quantization-Aware Training,简称QAT),概念解释如下:
- 训练后量化
训练后量化是指在模型训练结束之后进行的量化,对训练后模型中的权重由浮点数(当前支持FP32/FP16)量化到低比特整数(当前支持INT8),并通过少量校准数据基于推理过程对数据(activation)进行校准量化,从而尽可能减少量化过程中的精度损失。训练后量化简单易用,只需少量校准数据,适用于追求高易用性和缺乏训练资源的场景。
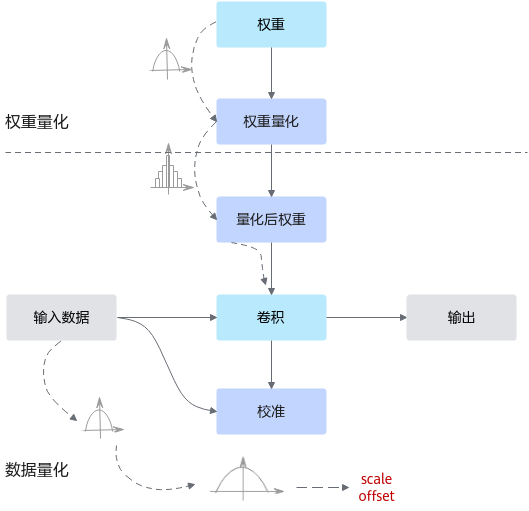
通常,训练后的模型权重已经确定,因此可以根据权重的数值离线计算得到权重的量化参数。而通常数据是在线输入的,因此无法准确获取数据的数值范围,通常需要一个较小的有代表性的数据集来模拟在线数据的分布,利用该数据集执行前向推理,得到对应的中间浮点结果,并根据这些浮点结果离线计算出数据的量化参数。其原理如图1所示。训练后量化使用的量化算法请参见训练后量化算法。
根据量化后是否手动调优量化配置文件,分为手工量化和自动量化。
根据是否对权重数据进行压缩又分为均匀量化和非均匀量化。如果量化后的精度不满足要求,则可以进行自动量化或手工调优,推荐使用自动量化。
- 量化感知训练
量化感知训练是指在重训练过程中引入量化,通过重训练提高模型对量化效应的能力,从而获得更高的量化模型精度的一种量化方式。量化感知训练借助用户完整训练数据集,在训练过程中引入伪量化的操作(从浮点量化到定点,再还原到浮点的操作),用来模拟前向推理时量化带来的误差,并借助训练让模型权重能更好地适应这种量化的信息损失,从而提升量化精度。
通常,量化感知训练相比训练后量化,精度损失会更小,但主要缺点是整体量化的耗时会更长;此外,量化过程需要的数据会更多,通常是完整训练数据集。
量化感知训练当前仅支持对FP32数据类型的网络模型进行量化。其运行原理如图2所示。量化感知训练使用的量化算法请参见量化感知训练算法
当前仅支持手工量化,如果量化后的精度不满足要求,可以进行手工调优。

相关概念
量化过程中使用的相关术语解释如下:
术语 |
解释 |
|---|---|
数据量化和权重量化 |
训练后量化和量化感知训练,根据量化对象不同,又分为数据(activation)量化和权重(weight)量化。 当前昇腾AI处理器支持数据(Activation)做对称/非对称量化,权重(weights)仅支持做对称量化(量化根据量化后数据中心点是否为0可以分为对称量化、非对称量化,详细的量化算法原理请参见量化算法原理)。
|
量化位宽 |
量化根据量化后低比特位宽大小分为常见的INT8、INT4、INT16、Binary量化等,AMCT支持INT8、INT4和INT16量化方式。
其中:
|
测试数据集 |
数据集的子集,用于最终测试模型的效果。 |
校准 |
训练后量化场景中,做前向推理获取数据量化因子的过程。 |
校准数据集 |
训练后量化场景中,做前向推理使用的数据集。该数据集的分布代表着所有数据集的分布,获取校准集时应该具有代表性,推荐使用测试集的子集作为校准数据集。如果数据集不是模型匹配的数据集或者代表性不够,则根据校准集计算得到的量化因子,在全数据集上表现较差,量化损失大,量化后精度低。 |
训练数据集 |
数据集的子集,基于用户训练网络中的数据集,用于对模型进行训练。 |
量化因子 |
将浮点数量化为整数的参数,包括缩放因子(Scale),偏移量(Offset)。 将浮点数量化为整数(以INT8为例)的公式如下:
|
Scale |
量化因子,浮点数的缩放因子,该参数又分为:
|
Offset |
量化因子,偏移量,该参数又分为:
|
量化敏感度 |
模型在不同数据精度下,计算结果是有差异的,正常情况下,数据精度越高计算越准确,网络模型的推理结果越准确,而使用量化方法降低网络模型或者某层的数据精度后,会影响模型推理的精度。为了评估这种影响,引入量化敏感度的概念。 量化敏感度用于评价网络模型或者可量化层受量化影响大小。通过比较网络的输出或者某层的输出在量化前后的差异来计算量化敏感度,常见的指标有MSE(Mean Square Error,均方误差),余弦相似度等。 |
比特复杂度 |
对模型中的某层来说,浮点计算量为Flops。而比特复杂度(bitops)则综合了浮点计算量和数据精度,描述在不同的数据精度下(比如,FP32/FP16/INT8/INT4),计算资源存在的差异。 具体计算方法如下,其中Flops为浮点计算量,act_bit为数据的数据精度,wts_bit为权重的数据精度。
|