精度调优流程
精度调优背景
用户迁移后的模型在昇腾AI处理器(简称NPU)上训练,功能已调通,但可能会遇到精度不达标或者收敛效果差的问题,用户模型在昇腾AI处理器上执行时,包括但不限于:
- loss曲线与参考基准差异不符合预期
- 验证准确度与参考基准差异不符合预期
这些精度问题由于具有以下特征而非常难以定位:
- 训练正常结束
- 日志无任何异常
- 仅在与参考基准对比时才发现结果不符合预期
为指引开发者进行精度调优,本节提供了精度调优流程指引。
精度调优思路
精度问题来源可能来自于各个方面:
- 提供的参考基准存在问题
- 进行模型迁移时存在问题
- 网络中算子精度问题等
根据问题来源的不同以及高概率的问题发生点,您可以按照以下流程进行精度问题的定位。
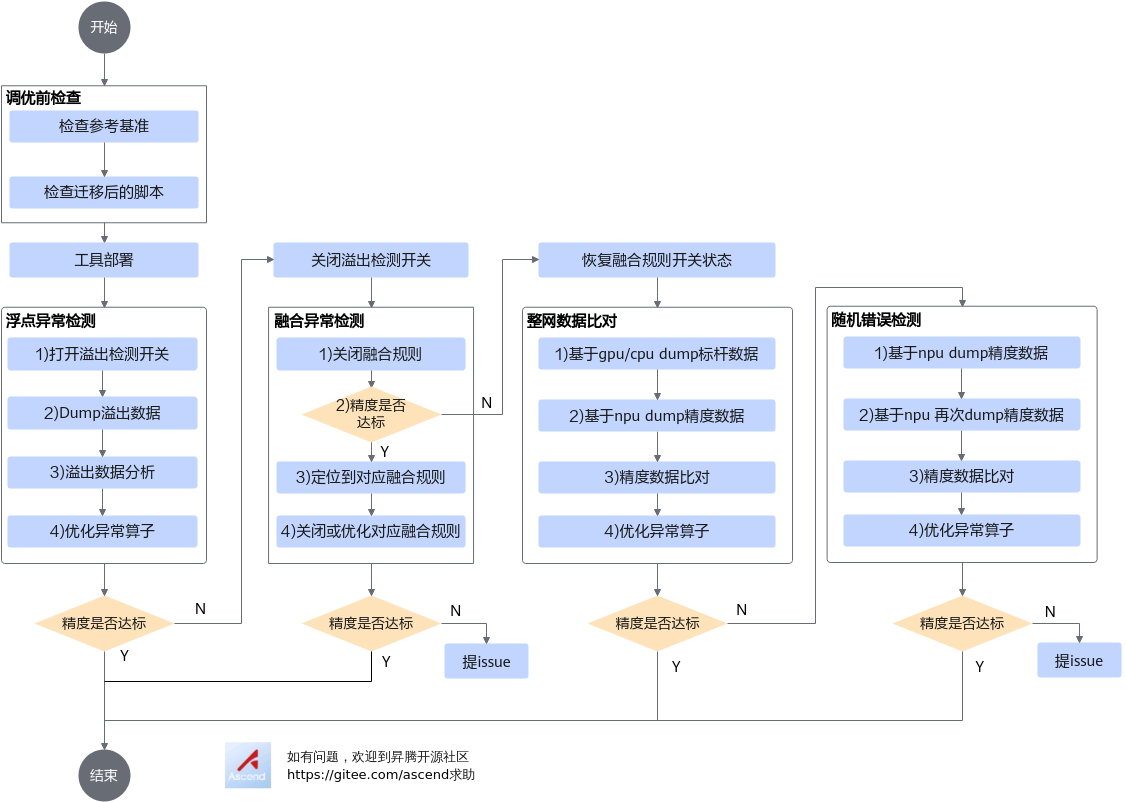
序号 |
操作 |
说明 |
|---|---|---|
1 |
训练网络精度调优前,一般进行如下两方面的检查:
|
|
2 |
训练网络精度调优前,需要在NPU训练环境部署一键式精度分析工具。 |
|
3 |
训练网络执行过程中,可能发生频繁的浮点异常情况,即loss scale值下降次数较多或者直接下降为1,此时需要通过分析溢出数据,对频繁的浮点异常问题进行定界定位。 |
|
4 |
训练网络执行过程中,系统会根据内置的融合规则对网络中算子进行融合,以达到提高网络性能的效果。由于大多数融合是自动识别的,可能存在未考虑到的场景,导致精度问题,因此可以尝试关闭融合规则,定界网络问题是否是由于融合导致。 |
|
5 |
排除以上问题后,在训练网络精度仍未达预期时,通过采集训练过程中各算子的运算结果(即Dump数据),然后和业界标准算子(如TensorFlow)运算结果进行数据偏差对比,快速定位到具体算子的精度问题。 |
|
6 |
网络执行过程中,可能存在部分计算过程在相同输入的情况下给出了不同的输出的问题。当出现以上随机问题时,可以通过执行两次训练,并分别采集各算子的运算结果(即dump数据),通过比对分析,从而快速定位到导致随机问题的算子层。 |
父主题: 精度调优
