均匀量化
均匀量化是指量化后的数据比较均匀地分布在某个数值空间中,例如INT8量化就是用只有8比特的INT8数据来表示32比特的FP32数据或16比特的FP16数据,将FP32/FP16的卷积运算过程(乘加运算)转换为INT8的卷积运算,加速运算和实现模型压缩;均匀的INT8量化则是量化后数据比较均匀地分布在INT8的数值空间[-128, 127]中。
如果均匀量化后的模型精度无法满足要求,则需要进行基于精度的自动量化或量化感知训练或手工调优。均匀量化支持量化的层以及约束如下,量化示例请参见样例列表。
支持的层类型 |
约束 |
备注 |
|---|---|---|
torch.nn.Linear |
- |
复用层(共用weight和bias参数)不支持量化。 |
torch.nn.Conv2d |
|
|
torch.nn.Conv3d |
|
|
torch.nn.ConvTranspose2d |
|
|
torch.nn.AvgPool2d |
- |
- |
接口调用流程
均匀量化接口调用流程如图1所示。
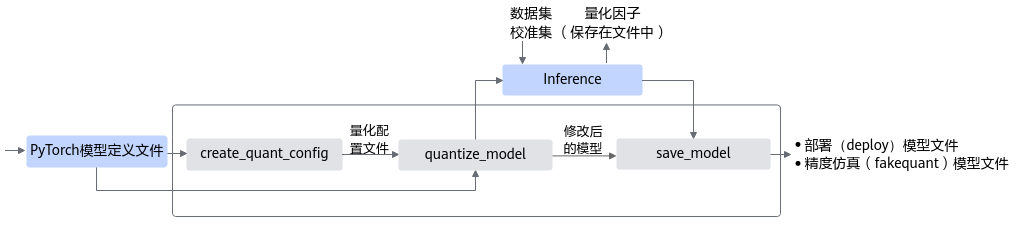
蓝色部分为用户实现,灰色部分为用户调用AMCT提供的API实现,工具使用分为如下场景:
- 用户首先构造PyTorch的原始模型,然后使用create_quant_config生成量化配置文件。
- 根据PyTorch模型和量化配置文件,即可调用quantize_model接口对原始PyTorch模型进行优化,优化后的PyTorch模型中包含了量化算法。
- 使用校准集在PyTorch环境下执行前向推理,产生量化因子,并将量化因子输出到文件中。
- 最后用户可以调用save_model接口保存量化后的模型,包括可在ONNX执行框架ONNX Runtime环境中进行精度仿真的模型文件和可部署在昇腾AI处理器的模型文件。
- 精度仿真模型文件:ONNX格式的模型文件,模型名中包含fake_quant,可以在ONNX Runtime环境进行精度仿真。
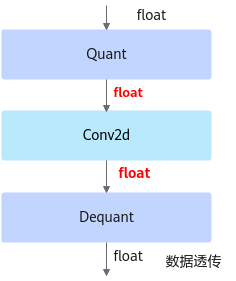
fake_quant模型主要用于验证量化后模型的精度,可以在ONNX Runtime环境下运行。进行前向推理的计算过程中,在fake_quant模型中对卷积层等的输入数据和权重进行了量化反量化的操作,来模拟量化后的计算结果,从而快速验证量化后模型的精度。如下图所示,以INT8量化为例,Quant层、Conv2d卷积层和DeQuant层之间的数据都是Float32数据类型的,其中Quant层将数据量化到INT8又反量化为Float32,权重也是量化到INT8又反量化为Float32,实际卷积层的计算是基于Float32数据类型的,该模型用于在ONNX Runtime环境验证量化后模型的精度,不能够用于ATC工具转换成om模型。图2 fake_quant模型
- 部署模型文件:ONNX格式的模型文件,模型名中包含deploy,经过ATC转换工具转换后可部署到在昇腾AI处理器。
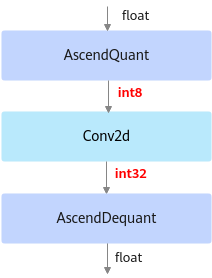
以INT8量化为例,deploy模型由于已经将权重等转换成为了INT8,INT32类型, 因此不能在ONNX Runtime环境上执行推理计算。如下图所示,deploy模型的AscendQuant层将Float32的输入数据量化为INT8,作为卷积层的输入,权重也是使用INT8数据类型作为计算,在deploy模型中的卷积层的计算是基于INT8,INT32数据类型的,输出为INT32数据类型经过AscendDeQuant层转换成Float32数据类型传输给下一个网络层。图3 deploy模型
- 精度仿真模型文件:ONNX格式的模型文件,模型名中包含fake_quant,可以在ONNX Runtime环境进行精度仿真。
调用示例
训练后量化主要包括如下几个步骤:
- 准备训练好的模型和数据集。
- 在原始PyTorch环境中验证模型精度以及环境是否正常。
- 编写训练后量化脚本调用AMCTAPI。
- 执行训练后量化脚本。
- 在ONNX Runtime环境中验证量化后仿真模型精度。

- 由于软件约束(动态shape场景下暂不支持输入数据为DT_INT8),量化后的部署模型使用ATC工具进行模型转换时,不能使用动态shape相关参数,例如--dynamic_batch_size和--dynamic_image_size等,否则模型转换会失败。
- 使用AMCT工具量化后的部署模型,使用ATC工具进行模型转换时,不能再使用高精度特性,比如不能再通过--precision_mode参数配置force_fp32或must_keep_origin_dtype(原图fp32输入);不能再通过--precision_mode_v2参数配置origin;不能通过--op_precision_mode配置high_precision参数等。在高精度模式下设置量化参数,既拿不到量化的性能收益,也拿不到高精度模式的精度收益。
- 如下示例标有“由用户补充处理”的步骤,需要用户根据自己的模型和数据集进行补充处理,示例中仅为示例代码。
- 如下示例调用AMCT的部分,函数入参请根据实际情况进行调整。
- 导入AMCT包,并通过安装后处理>AMCT(PyTorch)中的环境变量设置日志级别。
1import amct_pytorch as amct
- (可选,由用户补充处理)在PyTorch原始环境中验证推理脚本及环境。
建议使用原始待量化的模型和测试集,在PyTorch环境下推理,验证环境、推理脚本是否正常。
推荐执行该步骤,请确保原始模型可以完成推理且精度正常;执行该步骤时,可以使用部分测试集,减少运行时间。
1user_do_inference_torch(ori_model, test_data, test_iterations)
- 调用AMCT,量化模型。
- 生成量化配置。
1 2 3 4 5 6 7 8
config_file = './tmp/config.json' skip_layers = [] batch_num = 1 amct.create_quant_config(config_file=config_file, model=ori_model, input_data=ori_model_input_data, skip_layers=skip_layers, batch_num=batch_num)
- 修改图,在图中插入数据量化,权重量化等相关的算子,用于计算量化相关参数。
1 2 3 4 5 6 7
record_file = './tmp/record.txt' modified_onnx_model = './tmp/modified_model.onnx' calibration_model = amct.quantize_model(config_file=config_file, modified_onnx_model=modified_onnx_model, record_file=record_file, model=ori_model, input_data=ori_model_input_data)
- (由用户补充处理)基于PyTorch环境,使用修改后的模型(calibration_model)在校准集(calibration_data)上做模型推理,生成量化因子。
- 校准集及其预处理过程数据要与模型匹配,以保证量化的精度。
- 前向推理的次数为batch_num,如果次数不够,后续过程会失败。
校准过程中如果提示[IFMR]: Do layer xxx data calibration failed!错误信息,则请参见校准执行过程中提示“[IFMR]: Do layer xxx data calibration failed!”解决。
1user_do_inference_torch(calibration_model, calibration_data, batch_num)
- 保存模型。
根据量化因子,调用save_model接口,插入AscendQuant、AscendDequant等算子,保存为量化模型。
1 2 3 4
quant_model_path = './results/user_model' amct.save_model(modified_onnx_file=modified_onnx_file, record_file=record_file, save_path=quant_model_path)
- 生成量化配置。
- (可选,由用户补充处理)基于ONNX Runtime的环境,使用量化后模型(quant_model)在测试集(test_data)上做推理,测试量化后仿真模型的精度。使用量化后仿真模型精度与2中的原始精度做对比,可以观察量化对精度的影响。
1 2
quant_model = './results/user_model_fake_quant_model.onnx' user_do_inference_onnx(quant_model, test_data, test_iterations)
父主题: 手工量化