AI CPU算子开发流程
通过MindStudio工具进行AI CPU算子开发的总体开发流程如下:
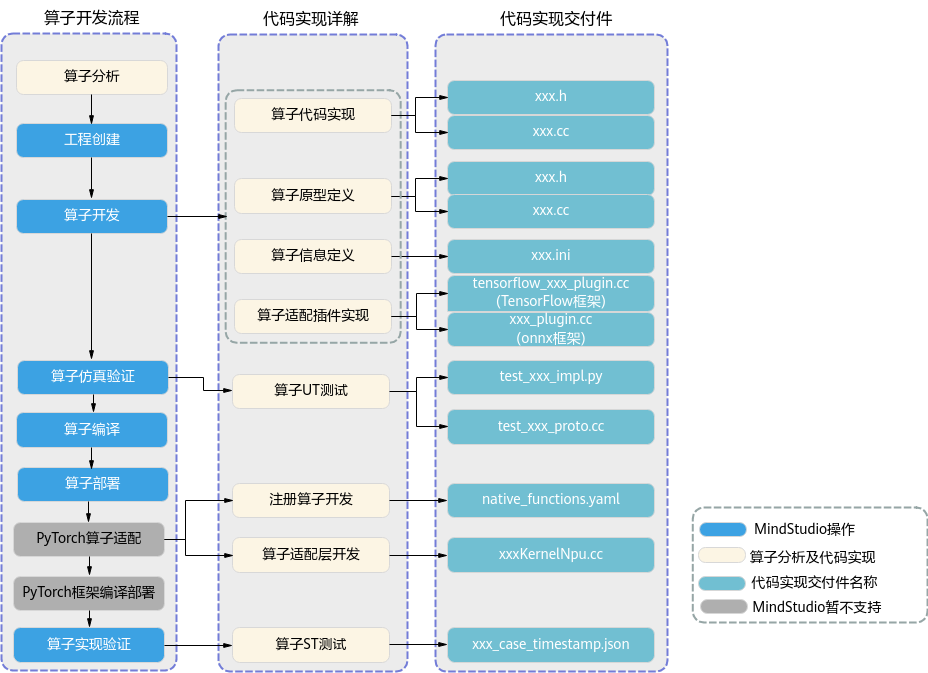
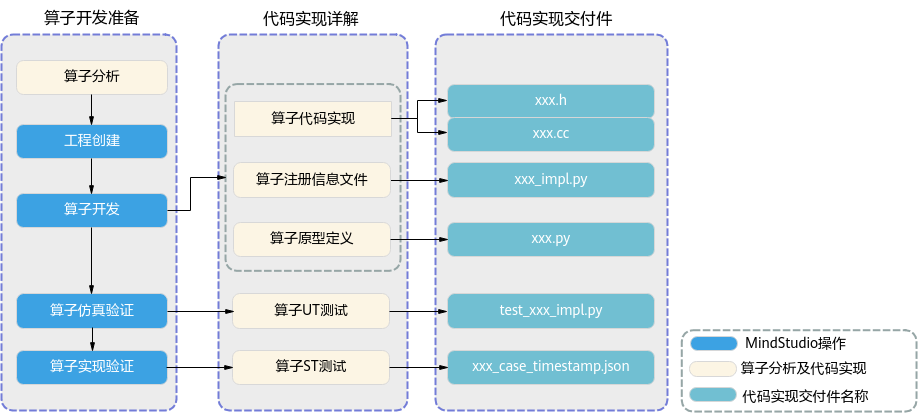
- 算子分析:明确算子的功能、输入、输出,规划算子类型名称以及算子编译生成的库文件名称等。
- 工程创建:通过MindStudio工具创建AI CPU算子工程,创建完成后,会自动生成算子工程目录及相应的文件模板,开发者可以基于这些模板进行算子开发。
- 算子开发:MindSpore框架的算子实现和注册信息文件以及算子原型定义具体实现方式请参考《MindSpore教程》的“自定义算子”。
- 算子代码实现:实现算子的计算逻辑。
- 算子原型定义:算子原型定义规定了在昇腾AI处理器上可运行算子的约束,主要体现算子的数学含义,包含定义算子输入、输出、属性和取值范围,基本参数的校验和shape的推导,原型定义的信息会被注册到GE的算子原型库中。离线模型转换时,GE会调用算子原型库的校验接口进行基本参数的校验,校验通过后,会根据原型库中的推导函数推导每个节点的输出shape与dtype,进行输出tensor的静态内存的分配。
- 算子信息定义:算子信息配置文件用于将算子的相关信息注册到算子信息库中,包括算子的OpType、输入输出dtype、name等信息。网络运行时,AI CPU Engine会根据算子信息库中的算子信息做基本校验,并进行算子匹配。
- 算子适配插件实现:基于第三方框架(TensorFlow/ONNX)进行自定义算子开发的场景,开发人员完成自定义算子的实现代码后,需要进行插件的开发将基于TensorFlow/ONNX的算子映射成昇腾AI处理器的算子。
- UT测试:即单元测试(Unit Test),仿真环境下验证算子实现的功能正确性,包括算子逻辑实现代码及算子原型定义实现代码。
- 算子编译:将算子适配插件实现文件编译成算子插件,原型定义文件编译成算子原型库,信息定义文件编译成算子信息库。
- 算子部署:将算子实现文件、编译后的算子插件、算子原型库和算子信息库部署到昇腾AI处理器算子库中(opp的对应目录下)。
- PyTorch算子适配:昇腾AI处理器具有内存管理,设备管理和算子调用实现功能。PyTorch算子适配根据PyTorch原生结构进行昇腾AI处理器扩展。
- ST测试:即系统测试(System Test),可以自动生成测试用例,在真实的硬件环境中验证算子实现代码的功能正确性。
父主题: 开发流程