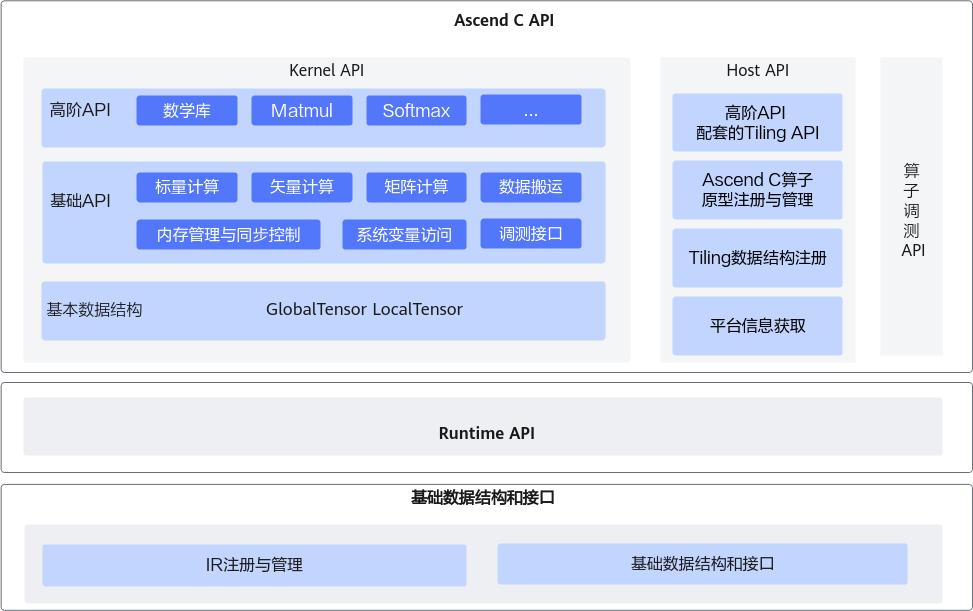
Ascend C API列表
Ascend C提供一组类库API,开发者使用标准C++语法和类库API进行编程。Ascend C编程类库API示意图如下所示,分为:
- Kernel API:用于实现算子核函数的API接口。包括:
- 基本数据结构:kernel API中使用到的基本数据结构,比如GlobalTensor和LocalTensor。
- 基础API:实现对硬件能力的抽象,开放芯片的能力,保证完备性和兼容性。标注为ISASI(Instruction Set Architecture Special Interface,硬件体系结构相关的接口)类别的API,不能保证跨硬件版本兼容。
- 高阶API:实现一些常用的计算算法,用于提高编程开发效率,通常会调用多种基础API实现。高阶API包括数学库、Matmul、Softmax等API。高阶API可以保证兼容性。
- Host API:
- 高阶API配套的Tiling API:kernel侧高阶API配套的Tiling API,方便开发者获取kernel计算时所需的Tiling参数。
- Ascend C算子原型注册与管理API:用于Ascend C算子原型定义和注册的API。
- Tiling数据结构注册API:用于Ascend C算子TilingData数据结构定义和注册的API。
- 平台信息获取API:在实现Host侧的Tiling函数时,可能需要获取一些硬件平台的信息,来支撑Tiling的计算,比如获取硬件平台的核数等信息。平台信息获取API提供获取这些平台信息的功能。
- 算子调测API:用于算子调测的API,包括孪生调试,性能调测等。
进行Ascend C算子Host侧编程时,需要使用基础数据结构和API,请参考基础数据结构与接口;完成算子开发后,需要使用Runtime API完成算子的调用,请参考《AscendCL应用软件开发指南 (C&C++)》中的“AscendCL API参考”章节。
Kernel API——基础API
接口名 |
功能描述 |
|---|---|
获取一个uint64_t类型数字的二进制中0或者1的个数。 |
|
计算一个uint64_t类型数字前导0的个数(二进制从最高位到第一个1一共有多少个0)。 |
|
将一个scalar的类型转换为指定的类型。 |
|
计算一个uint64_t类型数字的二进制中,从最高数值位开始与符号位相同的连续比特位的个数。 |
|
获取一个uint64_t类型数字的二进制中第一个0或1出现的位置。 |
|
float类型标量数据转换成bfloat16_t类型标量数据。 |
|
bfloat16_t类型标量数据转换成float类型标量数据。 |
分类 |
接口名 |
功能描述 |
|---|---|---|
单目指令 |
按元素取自然指数。 |
|
按元素取自然对数。 |
||
按元素取绝对值。 |
||
按元素取倒数。 |
||
按元素做开方。 |
||
按元素做开方后取倒数。 |
||
按元素做按位取反。 |
||
按元素做线性整流Relu。 |
||
双目指令 |
按元素求和。 |
|
按元素求差。 |
||
按元素求积。 |
||
按元素求商。 |
||
按元素求最大值。 |
||
按元素求最小值。 |
||
针对每对元素执行按位与运算。 |
||
针对每对元素执行按位或运算。 |
||
按元素求和,结果和0对比取较大值。 |
||
按元素求和,结果和0对比取较大值,并根据源操作数和目的操作数Tensor的数据类型进行精度转换。 |
||
依次计算按元素求和、结果进行deq量化后再进行relu计算(结果和0对比取较大值)。 |
||
按元素求差,结果和0对比取较大值。 |
||
按元素求差,结果和0对比取较大值,并根据源操作数和目的操作数Tensor的数据类型进行精度转换。 |
||
按元素将src0Local和src1Local相乘并和dstLocal相加,将最终结果存放进dstLocal中。 |
||
按元素将src0Local和dstLocal相乘并加上src1Local,最终结果存放入dstLocal。 |
||
按元素将src0Local和dstLocal相乘并再加上src1Local,将结果和0作比较,取较大值,最终结果存放进dstLocal中。 |
||
标量双目指令 |
矢量内每个元素与标量求和。 |
|
矢量内每个元素与标量求积。 |
||
源操作数矢量内每个元素与标量相比,如果比标量大,则取源操作数值,比标量的值小,则取标量值。 |
||
源操作数矢量内每个元素与标量相比,如果比标量大,则取标量值,比标量的值小,则取源操作数。 |
||
源操作数内每个元素做逻辑左移,逻辑左移的位数由输入参数scalar决定。 |
||
源操作数内每个元素做右移,右移的位数由输入参数scalar决定。 |
||
按元素做带泄露线性整流Leaky ReLU。 |
||
标量三目指令 |
源操作数(srcLocal)中每个元素与标量求积后和目的操作数(dstLocal)中的对应元素相加。 |
|
比较指令 |
逐元素比较两个tensor大小,如果比较后的结果为真,则输出结果的对应比特位为1,否则为0。 |
|
逐元素比较两个tensor大小,如果比较后的结果为真,则输出结果的对应比特位为1,否则为0。Compare接口需要mask参数时,可以使用此接口。计算结果存放入寄存器中。 |
||
逐元素比较一个tensor中的元素和另一个Scalar的大小,如果比较后的结果为真,则输出结果的对应比特位为1,否则为0。 |
||
选择指令 |
给定两个源操作数src0和src1,根据selMask(用于选择的Mask掩码)的比特位值选取元素,得到目的操作数dst。选择的规则为:当selMask的比特位是1时,从src0中选取,比特位是0时从src1选取。 |
|
以内置固定模式对应的二进制或者用户自定义输入的Tensor数值对应的二进制为gather mask(数据收集的掩码),从源操作数中选取元素写入目的操作数中。 |
||
精度转换指令 |
根据源操作数和目的操作数Tensor的数据类型进行精度转换。 |
|
对输入做量化并进行精度转换。 |
||
归约指令 |
在所有的输入数据中找出最大值及最大值对应的索引位置。 |
|
在所有的输入数据中找出最小值及最小值对应的索引位置。 |
||
对所有的输入数据求和。 |
||
每个repeat内所有数据求最大值以及其索引index。 |
||
每个repeat内所有数据求最小值以及其索引index。 |
||
每个repeat内所有数据求和。 |
||
对每个datablock内所有元素求最大值。 |
||
对每个datablock内所有元素求最小值。 |
||
对每个datablock内所有元素求和。源操作数相加采用二叉树方式,两两相加。 |
||
PairReduceSum:相邻两个(奇偶)元素求和。 |
||
每个repeat内所有数据求和。和WholeReduceSum接口相比,不支持mask逐bit模式。建议使用功能更全面的WholeReduceSum接口。 |
||
数据填充 |
将一个变量或一个立即数,复制多次并填充到向量。 |
|
给定一个输入张量,每一次取输入张量中的8个数填充到结果张量的8个datablock(32Bytes)中去,每个数对应一个datablock。 |
||
以firstValue为起始值创建向量索引。 |
||
数据分散/数据收集 |
给定输入的张量和一个地址偏移张量,Gather指令根据偏移地址将输入张量按元素收集到结果张量中。 |
|
掩码操作 |
设置mask模式为Counter模式。该模式下,不需要开发者去感知迭代次数、处理非对齐的尾块等操作,可直接传入计算数据量,实际迭代次数由Vector计算单元自动推断。 |
|
设置mask模式为Normal模式。该模式为系统默认模式,支持开发者配置迭代次数。 |
||
用于在矢量计算时设置mask。 |
||
恢复mask的值为默认值(全1),表示矢量计算中每次迭代内的所有元素都将参与运算。 |
||
量化设置 |
设置DEQSCALE寄存器的值。 |
接口名 |
功能描述 |
|---|---|
数据搬运接口,包括普通数据搬运、增强数据搬运、切片数据搬运、随路格式转换。 |
|
VECIN、VECCALC、VECOUT之间的搬运指令,支持mask操作和datablock间隔操作。 |
接口名 |
功能描述 |
|---|---|
TPipe是用来管理全局内存等资源的框架。通过TPipe类提供的接口可以完成内存等资源的分配管理操作。 |
|
获取框架当前管理全局内存的TPipe指针,用户获取指针后,可进行TPipe相关的操作。 |
|
TPipe可以管理全局内存资源,而TBufPool可以手动管理或复用Unified Buffer/L1 Buffer物理内存,主要用于多个stage计算中Unified Buffer/L1 Buffer物理内存不足的场景。 |
|
提供入队出队等接口,通过队列(Queue)完成任务间通信和同步。 |
|
TQueBind绑定源逻辑位置和目的逻辑位置,根据源位置和目的位置,来确定内存分配的位置 、插入对应的同步事件,帮助开发者解决内存分配和管理、同步等问题。 |
|
使用Ascend C编程的过程中,可能会用到一些临时变量。这些临时变量占用的内存可以使用TBuf数据结构来管理。 |
|
初始化SPM Buffer。 |
|
将需要溢出暂存的数据拷贝到SPM Buffer中。 |
|
从SPM Buffer读回到local数据中。 |
|
获取用户使用的workspace指针。 |
|
在进行融合算子编程时,由于框架通信机制需要使用到workspace,也就是系统workspace,所以在该场景下,开发者要调用该接口,设置系统workspace的指针。 |
|
获取系统workspace指针。 |
|
从源地址所在的特定DDR地址预加载数据到data cache中。 |
|
该接口用来刷新Cache,保证Cache的一致性。 |
接口名 |
功能描述 |
|---|---|
获取当前任务配置的Block数,用于代码内部的多核逻辑控制等。 |
|
获取当前core的index,用于代码内部的多核逻辑控制及多核偏移量计算等。 |
|
获取当前芯片版本一个datablock的大小,单位为byte。开发者根据datablock的大小来计算API指令中待传入的repeatTimes 、dataBlockStride,repeatStride等参数值。 |
|
获取当前AI处理器架构版本号。 |
|
适用于Cube/Vector分离架构,用来获取Cube/Vector的配比。 |
接口名 |
功能描述 |
|---|---|
基于算子工程开发的算子,可以使用该接口Dump指定Tensor的内容。 |
|
基于算子工程开发的算子,可以使用该接口实现CPU侧/NPU侧调试场景下的格式化输出功能。 |
|
基于算子工程开发的算子,可以使用该接口实现CPU/NPU域assert断言功能。 |
|
基于算子工程开发的算子,可以使用该接口Dump指定Tensor的内容。该接口可以支持指定偏移位置的Tensor打印。 |
|
当软件产生异常后,使用该指令使kernel中止运行。 |
分类 |
接口名 |
功能描述 |
|---|---|---|
矢量计算 |
双线性插值操作,分为垂直迭代和水平迭代。 |
|
获取Compare(结果存入寄存器)指令的比较结果。 |
||
获取ReduceSum(针对tensor前n个数据计算)接口的计算结果。 |
||
将连续元素合入Region Proposal内对应位置,每次迭代会将16个连续元素合入到16个Region Proposals的对应位置里。 |
||
与ProposalConcat功能相反,从Region Proposals内将相应位置的单个元素抽取后重排,每次迭代处理16个Region Proposals,抽取16个元素后连续排列。 |
||
根据Region Proposals中的score域对其进行排序(score大的排前面),每次排16个Region Proposals。 |
||
将已经排好序的最多4 条region proposals队列,排列并合并成1条队列,结果按照score域由大到小排序。 |
||
排序函数,一次迭代可以完成32个数的排序。 |
||
将已经排好序的最多4 条队列,合并排列成 1 条队列,结果按照score域由大到小排序。 |
||
获取MrgSort或MrgSort4已经处理过的队列里的Region Proposal个数,并依次存储在四个List入参中。 |
||
给定一个输入的张量和一个地址偏移张量,Gatherb指令根据偏移地址将输入张量收集到结果张量中。 |
||
给定一个连续的输入张量和一个目的地址偏移张量,Scatter指令根据偏移地址生成新的结果张量后将输入张量分散到结果张量中。 |
||
矩阵计算 |
初始化LocalTensor(TPosition为A1/A2/B1/B2)为某一个具体的数值。 |
|
LoadData包括Load2D和Load3D数据加载功能。 |
||
该接口实现带转置的2D格式数据从A1/B1到A2/B2的加载。 |
||
设置图片预处理(AIPP,AI core pre-process)相关参数。 |
||
将图像数据从GM搬运到A1/B1。 搬运过程中可以完成图像预处理操作:包括图像翻转,改变图像尺寸(抠图,裁边,缩放,伸展),以及色域转换,类型转换等。 |
||
加载GM上的压缩索引表到内部寄存器。 |
||
将GM上的数据解压并搬运到A1/B1/B2上。 |
||
用于搬运存放在B1里的512B的稠密权重矩阵到B2里,同时读取128B的索引矩阵用于稠密矩阵的稀疏化。 |
||
用于调用Load3Dv1/Load3Dv2时设置FeatureMap的属性描述。 |
||
设置Load3D时A1/B1边界值。 |
||
用于设置Load3Dv2接口的repeat参数。设置repeat参数后,可以通过调用一次Load3Dv2接口完成多个迭代的数据搬运。 |
||
设置padValue,用于Load3Dv1/Load3Dv2。 |
||
完成矩阵乘加操作。 |
||
完成矩阵乘加操作,传入的左矩阵A为稀疏矩阵, 右矩阵B为稠密矩阵 。 |
||
矩阵计算完成后,对结果进行处理,例如对计算结果进行量化操作,并把数据从CO1搬迁到Global Memory中。 |
||
在Fixpipe的流程中,会涉及到relu (通过将FixpipeParams.reluEn设置为true)和quant(FixpipeParams.QuantParams设置为非NoQuant)的流程,分别用于relu和quant计算。通过该接口设置relu和quant的源操作数。 |
||
在Fixpipe的流程中,会涉及到nz2nd的流程(FixpipeParams.Nz2NdParams.nz2ndEn设置为true)该接口用于设置FixpipeNz2nd相关的配置。 |
||
在Fixpipe的流程中,会涉及到quant量化流程,该接口用于设置量化流程中deq scalar(量化参数)。 |
||
此接口同SetHF32TransMode与SetMMLayoutTransform一样,都用于设置寄存器的值。SetHF32Mode接口用于设置MMAD的HF32模式。 |
||
此接口同SetHF32Mode与SetMMLayoutTransform一样,都用于设置寄存器的值。SetHF32TransMode用于设置MMAD的HF32取整模式,仅在MMAD的HF32模式生效时有效。 |
||
此接口同SetHF32Mode与SetHF32TransMode一样,都用于设置寄存器的值,其中SetMMLayoutTransform接口用于设置MMAD的M/N方向。 |
||
监视设定范围内的UB读写行为,如果监视到有设定范围的读写行为则会出现EXCEPTION报错,未监视到设定范围的读写行为则不会报错。 |
||
计算给定输入张量和权重张量的2-D卷积,输出结果张量。Conv2d卷积层多用于图像识别,使用过滤器提取图像中的特征。 |
||
根据输入的切分规则,将给定的两个输入张量做矩阵乘,输出至结果张量。将A和B两个输入矩阵乘法在一起,得到一个输出矩阵C。 |
||
数据搬运 |
该接口提供数据非对齐搬运的功能。 |
|
设置DataCopyPad接口填充的数值。 |
||
同步控制 |
同一核内不同流水线之间的同步指令。具有数据依赖的不同流水指令之间需要插此同步。 |
|
阻塞相同流水,具有数据依赖的相同流水之间需要插此同步。 |
||
用于阻塞后续的指令执行,直到所有之前的内存访问指令(需要等待的内存位置可通过参数控制)执行结束。 |
||
针对分离架构,AI Core上的Cube核(AIC)与Vector核(AIV)之间的同步设置指令。 |
||
针对分离架构,AI Core上的Cube核(AIC)与Vector核(AIV)之间的同步等待指令。 |
||
缓存处理 |
从指令所在DDR地址预加载指令到ICache中。 |
|
获取ICACHE的PreLoad的状态。 |
||
系统变量访问 |
获取程序计数器的指针,程序计数器用于记录当前程序执行的位置。 |
|
获取AI Core上Vector核的数量。 |
||
获取AI Core上Vector核的ID。 |
||
获取当前系统cycle数,若换算成时间需要按照50MHz的频率,时间单位为us,换算公式为:time = (cycle数/50) us 。 |
||
原子操作 |
原子操作函数,设置后续从VECOUT传输到GM的数据是否执行原子比较,将待拷贝的内容和GM已有内容进行比较,将最大值写入GM。 |
|
原子操作函数,设置后续从VECOUT传输到GM的数据是否执行原子比较,将待拷贝的内容和GM已有内容进行比较,将最小值写入GM。 |
||
设置原子操作使能位与原子操作类型。 |
||
获取原子操作使能位与原子操作类型的值。 |
分类 |
接口名 |
功能描述 |
|---|---|---|
数据转换 |
可实现16*16的二维矩阵数据块的转置和[N,C,H,W]与[N,H,W,C]互相转换。 |
|
数据格式转换,一般用于将NCHW格式转换成NC1HWC0格式。特别的,也可以用于二维矩阵数据块的转置。 |
||
多核控制 |
当不同核之间操作同一块全局内存且可能存在读后写、写后读以及写后写等数据依赖问题时,通过调用该函数来插入同步语句来避免上述数据依赖时可能出现的数据读写错误问题。 |
|
当不同核之间操作同一块全局内存且可能存在读后写、写后读以及写后写等数据依赖问题时,通过调用该函数来插入同步语句来避免上述数据依赖时可能出现的数据读写错误问题。 |
||
当不同核之间操作同一块全局内存且可能存在读后写、写后读以及写后写等数据依赖问题时,通过调用该函数来插入同步语句来避免上述数据依赖时可能出现的数据读写错误问题。 |
||
初始化GM共享内存的值,完成初始化后才可以调用WaitPreBlock和NotifyNextBlock。 |
||
通过读GM地址中的值,确认是否需要继续等待,当GM的值满足当前核的等待条件时,该核即可往下执行,进行下一步操作。 |
||
通过写GM地址,通知下一个核当前核的操作已完成,下一个核可以进行操作。 |
||
原子操作 |
设置接下来从VECOUT到GM,L0C到GM,L1到GM的数据传输是否进行原子累加,可根据参数不同设定不同的累加数据类型。 |
|
通过设置模板参数来设定原子操作不同的数据类型。 |
||
原子操作函数,清空原子操作的状态。 |
||
Kernel Tiling |
用于获取算子kernel入口函数传入的tiling信息,并填入注册的Tiling结构体中,此函数会以宏展开的方式进行编译。如果用户注册了多个TilingData结构体,使用该接口返回默认注册的结构体。 |
|
在核函数中判断本次执行时的tiling_key是否等于某个key,从而标识tiling_key==key的一条kernel分支。 |
||
设置全局默认的kernel type,对所有的tiling key生效。 |
||
设置某一个具体的tiling key对应的kernel type。 |
Kernel API——高阶API
接口名 |
功能描述 |
|---|---|
按元素做反余弦函数计算。 |
|
按元素做双曲反余弦函数计算。 |
|
按元素做反正弦函数计算。 |
|
按元素做反双曲正弦函数计算。 |
|
按元素做三角函数反正切运算。 |
|
按元素做反双曲正切余弦函数计算。 |
|
源操作数中每个元素与标量求积后和目的操作数中的对应元素相加。 |
|
获取大于或等于x的最小的整数值,即向正无穷取整操作。 |
|
将srcTensor中大于scalar的数替换为scalar,小于等于scalar的数保持不变,作为dstTensor输出。 |
|
将srcTensor中小于scalar的数替换为scalar,大于等于scalar的数保持不变,作为dstTensor输出。 |
|
按元素做三角函数余弦运算。 |
|
按元素做双曲余弦函数计算。 |
|
对数据按行依次累加或按列依次累加。 |
|
按元素计算x的gamma函数的对数导数。 |
|
按元素做误差函数计算,也称为高斯误差函数。 |
|
返回输入x的互补误差函数结果,积分区间为x到无穷大。 |
|
按元素取自然指数。 |
|
获取小于或等于x的最小的整数值,即向负无穷取整操作。 |
|
按元素计算两个浮点数相除后的余数。 |
|
按元素做取小数计算。 |
|
按元素计算x的gamma函数的绝对值并求自然对数。 |
|
按元素以e、2、10为底做对数运算。 |
|
实现按元素做幂运算功能。 |
|
将输入的元素四舍五入到最接近的整数。 |
|
按元素执行Sign操作,Sign是指返回输入数据的符号。 |
|
按元素做正弦函数计算。 |
|
按元素做双曲正弦函数计算。 |
|
按元素做正切函数计算。 |
|
按元素做逻辑回归Tanh。 |
|
按元素做浮点数截断操作,即向零取整操作。 |
|
按元素执行Xor(异或)运算。 |
接口名 |
功能描述 |
|---|---|
按元素做伪量化计算,比如将int8_t数据类型伪量化为half数据类型。 |
|
按元素做反量化计算,比如将int32_t数据类型反量化为half/float等数据类型。 |
|
按元素做量化计算,比如将half/float数据类型量化为int8_t数据类型。 |
接口名 |
功能描述 |
|---|---|
对于每个batch中的样本,对其输入的每个特征在batch的维度上进行归一化。 |
|
在深层神经网络训练过程中,可以替代LayerNorm的一种归一化方法。 |
|
将输入数据收敛到[0, 1]之间,可以规范网络层输入输出数据分布的一种归一化方法。 |
|
用于计算LayerNorm的反向传播梯度。 |
|
用于获取反向beta/gmma的数值,和LayerNormGrad共同输出pdx, gmma和beta。 |
|
实现对shape大小为[B,S,H]的输入数据的RmsNorm归一化。 |
接口名 |
功能描述 |
|---|---|
用于对SoftMax相关计算结果做后处理,调整SoftMax的计算结果为指定的值。 |
|
FastGelu化简版本的一种激活函数。 |
|
实现FastGeluV2版本的一种激活函数。 |
|
采用GeLU作为激活函数的GLU变体。 |
|
GELU是一个重要的激活函数,其灵感来源于relu和dropout,在激活中引入了随机正则的思想。 |
|
对输入tensor做LogSoftmax计算。 |
|
一种GLU变体,使用Relu作为激活函数。 |
|
按元素做逻辑回归Sigmoid。 |
|
按元素做Silu运算。 |
|
使用计算好的sum和max数据对输入tensor做softmax计算。 |
|
对输入tensor按行做Softmax计算。 |
|
SoftMax增强版本,除了可以对输入tensor做softmaxflash计算,还可以根据上一次softmax计算的sum和max来更新本次的softmax计算结果。 |
|
SoftmaxFlash增强版本,对应FlashAttention-2算法。 |
|
对输入tensor做grad反向计算的一种方法。 |
|
对输入tensor做grad反向计算的一种方法。 |
|
采用Swish作为激活函数的GLU变体。 |
|
神经网络中的Swish激活函数。 |
接口名 |
功能描述 |
|---|---|
根据最后一轴的方向对各元素求平均值。 |
|
按照元素执行Xor(按位异或)运算,并将计算结果ReduceSum求和。 |
|
获取最后一个维度的元素总和。 |
接口名 |
功能描述 |
|---|---|
获取最后一个维度的前k个最大值或最小值及其对应的索引。 |
|
对数据进行预处理,将要排序的源操作数srcLocal一一对应的合入目标数据concatLocal中,数据预处理完后,可以进行Sort。 |
|
处理Sort的结果数据,输出排序后的value和index。 |
|
排序函数,按照数值大小进行降序排序。 |
|
将已经排好序的最多4条队列,合并排列成1条队列,结果按照score域由大到小排序。 |
接口名 |
功能描述 |
|---|---|
将输入按照输出shape进行广播。 |
|
对height * width的二维Tensor在width方向上pad到32B对齐。 |
|
对height * width的二维Tensor在width方向上进行unpad。 |
接口名 |
功能描述 |
|---|---|
提供根据MaskTensor对源操作数进行过滤的功能,得到目的操作数。 |
接口名 |
功能描述 |
|---|---|
给定两个源操作数src0和src1,根据maskTensor相应位置的值(非bit位)选取元素,得到目的操作数dst。 |
接口名 |
功能描述 |
|---|---|
对输入数据进行数据排布及Reshape操作。 |
接口名 |
功能描述 |
|---|---|
给定起始值,等差值和长度,返回一个等差数列。 |
接口名 |
功能描述 |
|---|---|
Matmul矩阵乘法的运算。 |
接口名 |
功能描述 |
|---|---|
在AI Core侧灵活编排集合通信任务。 |
接口名 |
功能描述 |
|---|---|
将Global Memory上的数据初始化为指定值。 |
Host API
算子调测API
接口名 |
功能描述 |
|---|---|
进行核函数的CPU侧运行验证时,用于创建共享内存:在/tmp目录下创建一个共享文件,并返回该文件的映射指针。 |
|
进行核函数的CPU侧运行验证时,CPU调测总入口,完成CPU侧的算子程序调用。 |
|
用于指定本次CPU调测使用的tilingKey。调测执行时,将只执行算子核函数中该tilingKey对应的分支。 |
|
进行核函数的CPU侧运行验证时,用于释放通过GmAlloc申请的共享内存。 |
|
CPU调测时,设置内核模式为单AIV模式,单AIC模式或者MIX模式,以分别支持单AIV矢量算子,单AIC矩阵算子,MIX混合算子的CPU调试。 |
|
通过CAModel进行算子性能仿真时,可对算子任意运行阶段打点,从而分析不同指令的流水图,以便进一步性能调优。 用于表示起始位置打点,一般与TRACE_STOP配套使用。 |
|
通过CAModel进行算子性能仿真时,可对算子任意运行阶段打点,从而分析不同指令的流水图,以便进一步性能调优。 用于表示终止位置打点,一般与TRACE_START配套使用。 |
|
用于设置性能数据采集信号启动,和MetricsProfStop配合使用。使用msProf工具进行算子上板调优时,可在kernel侧代码段前后分别调用MetricsProfStart和MetricsProfStop来指定需要调优的代码段范围。 |
|
设置性能数据采集信号停止,和MetricsProfStart配合使用。使用msProf工具进行算子上板调优时,可在kernel侧代码段前后分别调用MetricsProfStart和MetricsProfStop来指定需要调优的代码段范围。 |
